NewsBERT
If you want to stay up to date on technical discussions, you probably browse different sources of information like reddit, twitter, medium and various programming blogs.
Inspiration
In the recent two years there was lots of progress made in NLP because of transformer models. One remarkable feature of these pretrained language models can be used for tasks like Zero-Shot Learning.
Zero-shot learning for text mining is basically unsupervised classification where the classes are text themselves.
What it does
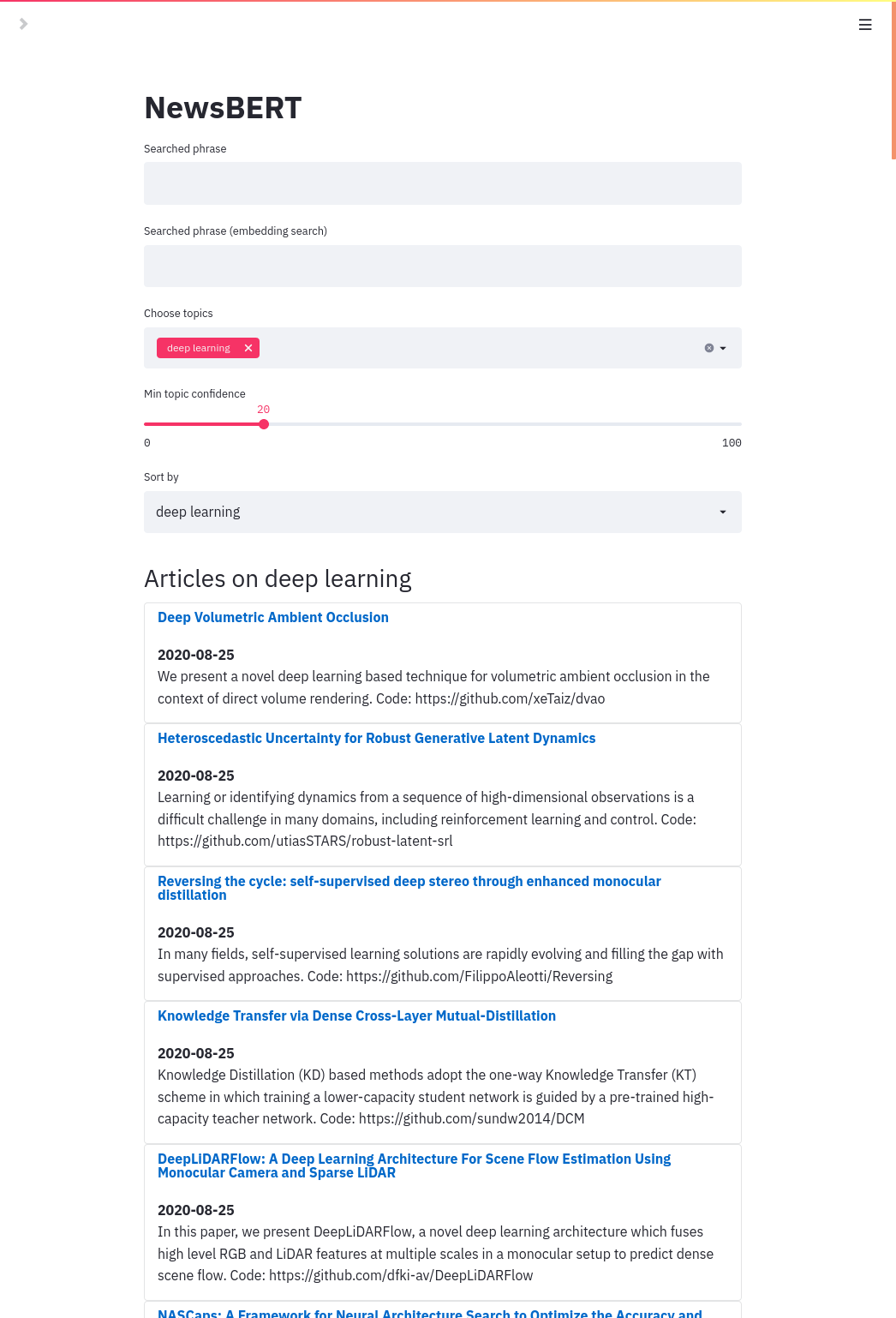
We tackle the problem of organizing information from different social media feeds in single wall that can be sorted by topics.
The app pulls articles from RSS feeds and lets the user filter the articles by topic classes.
How we built it
The app is built using streamlit. We used pretrained models from huggingface transformers and haystack libraries to extract topic scores.
More precisely we use Natural Language Inference models and construct pairs (text, "text is on {topic}") for given topics. The score gives the confidence that text entails the sentence "text is on {topic}" for each topic. This is used as our topic match score.
Our implementation uses deepset's haystack library to reduce zero-shot learning to search problem: for each topic we find top k documents that match query "text is on {topic}".
What's next for NewsBERT
We need to research ways to get better topic scores, for example using approaches similar to ones proposed in Pattern-Exploiting Training.
We also want to check whether classes specified by topic names correspond to something that can be extracted using topic modeling.


Log in or sign up for Devpost to join the conversation.