Inspiration
In a world overflowing with information, it has become a challenging task to distinguish fact from fiction and subsequently consume it as reliable insights. This situation has led to the spread of misinformation, eroding public trust and undermining the foundation of well-informed decision-making. Hence, the system is proposed to predict the reliability of news articles, empowering users to make informed choices and promoting media literacy in the digital age.
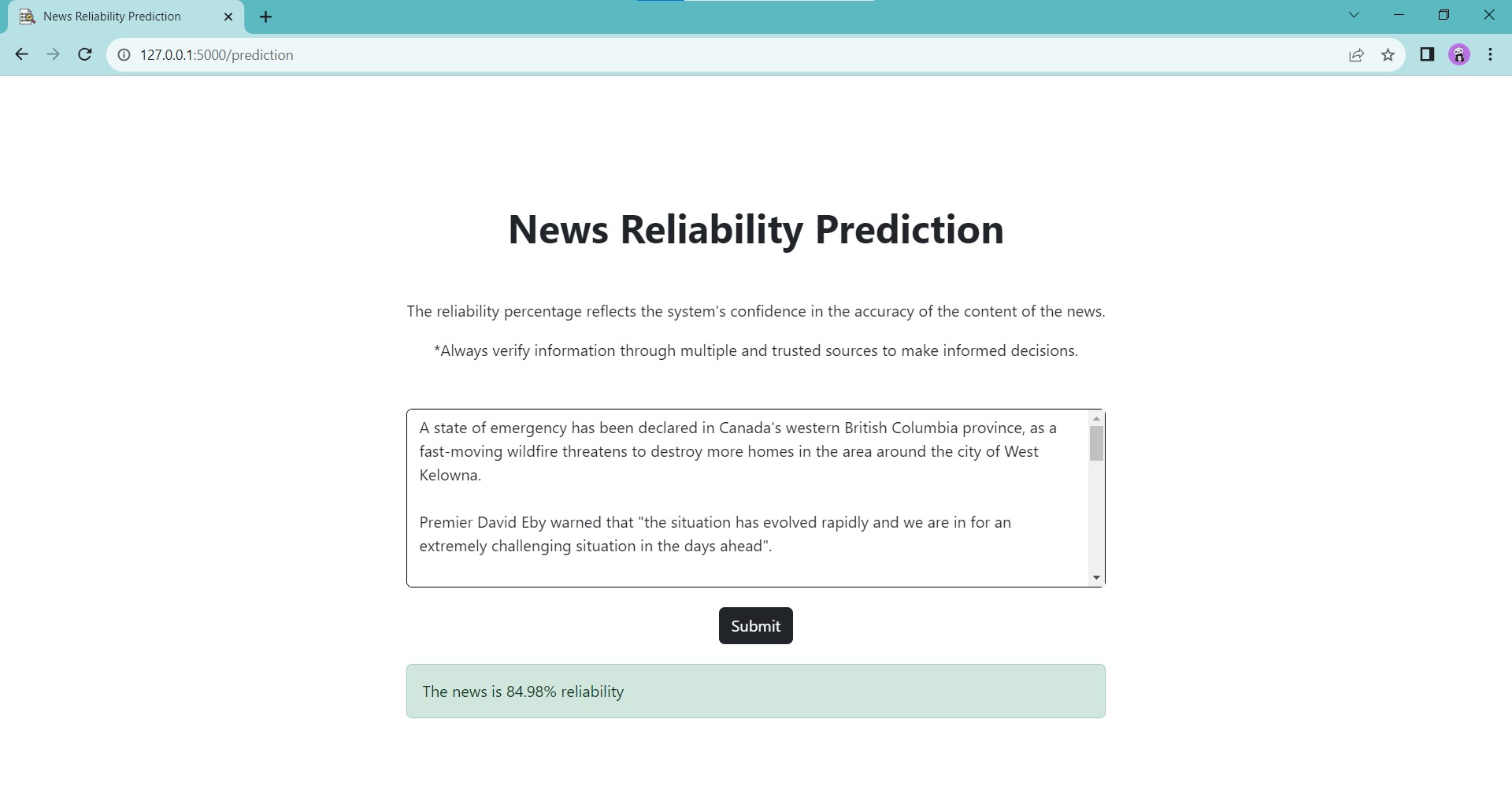
What it does
By inputting the content of the news articles, the system provides real-time feedback on the reliability of the news in percentage form. However, the measurement only serves as a reference on the credibility and authenticity of the news article.
How we built it
The process is started by gathering a suitable dataset that encompasses various topics and sources. Then, the data is preprocessed through the removal of stopwords and stemming (reducing a word to its stem word) to ensure uniformity and consistency in the text data. Using advanced Natural Language Processing (NLP) techniques, the processed text data is transformed into numerical representations that the machine learning algorithm could understand. TF-IDF (Term Frequency-Inverse Document Frequency) vectorization method is then applied to capture the importance of words within each article (feature extraction). Leveraging the power of machine learning, Logistic Regression model was chosen to train on the preprocessed and vectorized data. To ensure the effectiveness and generalization of our model, a portion of the dataset is used for testing and validation purposes. Metrics such as accuracy, precision, recall, and F1-score were employed to assess the model's performance.
For the user interface, Flask, a Python web framework has been applied to built a user-friendly web application. Users can enter news content into the provided text box, and the system processes the input using the trained model to determine the reliability percentage.
Challenges we ran into
One of the prominent challenges in developing the system is dealing with data within news datasets as the data is quite old (5 years ago), which introduces the possibility of outdated information and trends. Additionally, there are difficulties in choosing the correct machine learning model to effectively fit the historical data while ensuring its relevance in predicting the reliability of current news articles.
Accomplishments that we're proud of
I am pleased to share that the machine learning model is able to predict the reliability of news with an accuracy of over 98% on our test dataset as countless hours of research and iterative experimentation has put to achieve this level of accuracy. Additionally, I am also delighted to have created a user-centric interface for our model, which allows users to enter text and get the result of reliability prediction. Throughout this journey, I have also gained and developed newfound skills in data cleaning, natural language processing, and machine learning.
What we learned
Data preprocessing, feature extraction, model selection and training, model evaluation, Natural Language Processing (NLP)
What's next for News Reliability Prediction System
To empower users to effortlessly access the system's functionality, I plan to integrate the system into a Chrome extension, enabling users to highlight text on any webpage and receive instant reliability feedback. Nonetheless, it is important to continuously refine the system's accuracy and reliability by periodically updating the model with new data.






Log in or sign up for Devpost to join the conversation.