Inspiration
In an era where information flows at an unprecedented rate, manually sorting and understanding news articles has become inefficient. We were inspired to build an automated news classification system that can quickly categorize articles into predefined topics, enabling users, researchers, and organizations to organize large volumes of news data effortlessly.
What it does
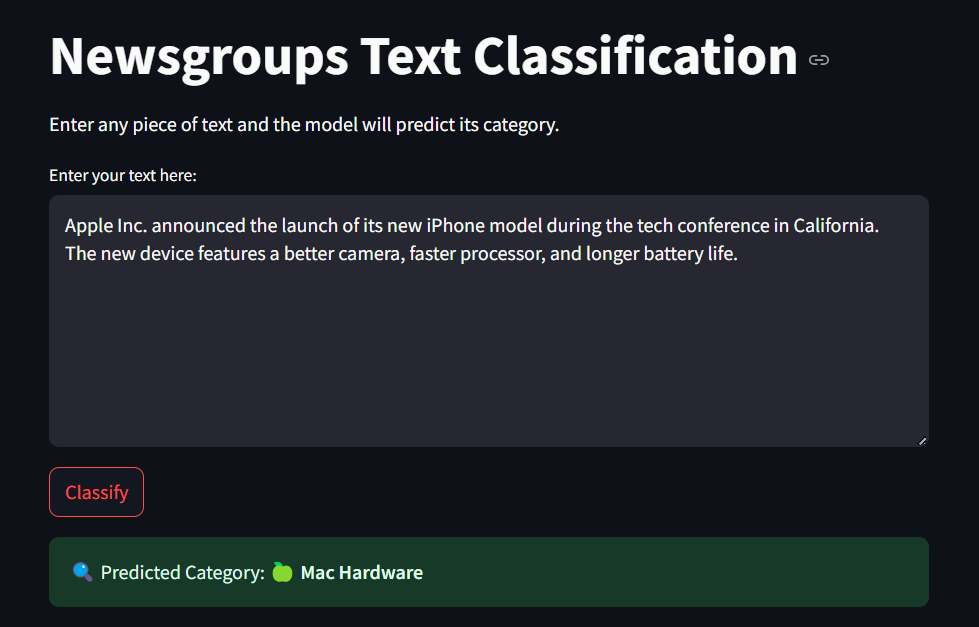
Our project uses Natural Language Processing (NLP) techniques to automatically classify raw news articles into 20 distinct categories (like sports, politics, technology, etc.). It takes completely raw, unstructured text (including headers and metadata) and processes it through: Text cleaning and lemmatization Feature extraction using TF-IDF Model training with Logistic Regression Finally, it predicts the correct category for unseen news articles with high accuracy.
How we built it
We built the project using the following steps: Data Loading: We used the raw 20 Newsgroups dataset. Text Preprocessing: Implemented custom cleaning, tokenization, stopword removal, and lemmatization using spaCy. Feature Engineering: Extracted important features with TF-IDF Vectorization, including unigrams and bigrams. Model Building: Trained a Logistic Regression model to learn from the vectorized news articles. Evaluation: Assessed model performance with accuracy score, classification report, and confusion matrix visualization. Libraries Used: Python, Scikit-learn, spaCy, Seaborn, Matplotlib.
Challenges we ran into
Handling Raw Text: Raw news data contains lots of noise — headers, footers, email addresses, and irrelevant content that had to be cleaned without losing important information. Balancing Preprocessing: Over-cleaning the data led to loss of context, while under-cleaning introduced noise. Finding the right balance was challenging. Model Convergence: Some models like Logistic Regression required tuning parameters (like max_iter) to ensure proper convergence with large text data.
Accomplishments that we're proud of
Successfully processing completely raw, unstructured data into a clean and usable format. Building an end-to-end pipeline from preprocessing → feature engineering → modeling → evaluation. Achieving a high accuracy (around 80%) by fine-tuning the vectorizer and classifier, despite working with complex, real-world textual data. Gaining deep understanding of how real-world NLP projects handle noise and feature extraction.
What we learned
The importance of proper text preprocessing — even minor tweaks can significantly affect model performance.
TF-IDF and n-grams play a crucial role in capturing the context in text classification tasks. Choosing the right model matters — Logistic Regression outperformed Naive Bayes in our case for this dataset. Visualization (like confusion matrices) helps in interpreting model mistakes and guiding further improvements.
What's next for News Calssification
Deploy the model via a simple web application where users can paste news articles and get instant category predictions. Improve the model by experimenting with advanced models like BERT, RoBERTa, or fine-tuned transformers for even better performance. Incorporate Multilabel Classification, where a news article can belong to multiple categories if relevant. Real-time News Streams: Extend the system to classify live news feeds or social media posts. Explainable AI: Integrate techniques to explain why a particular article was classified into a category (model interpretability).
Built With
- natural-language-processing
- python
- scikit-learn
- spacy
- streamlit

Log in or sign up for Devpost to join the conversation.