-
The app frontend
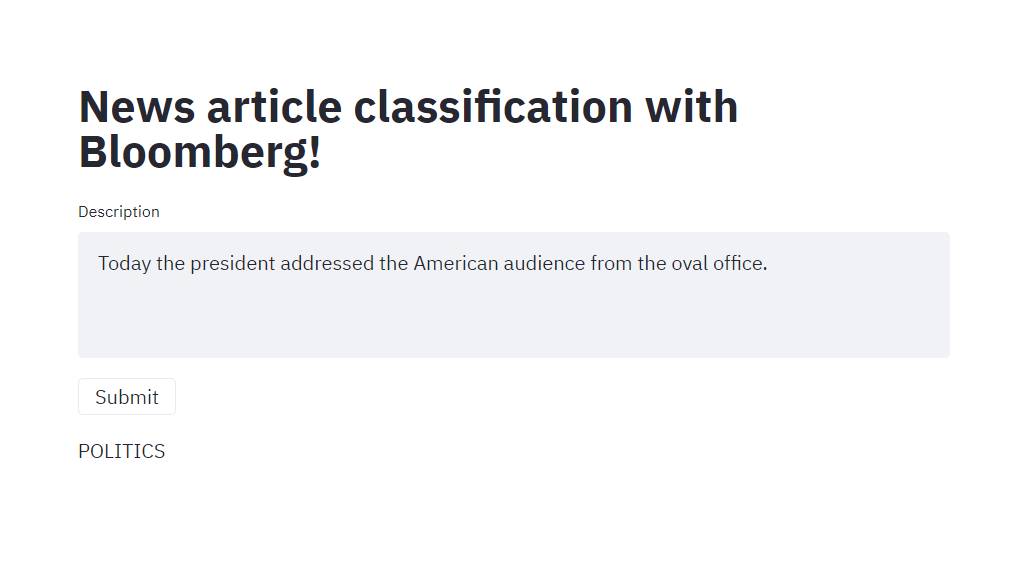
Task 1: Embedding preimage predictions:
- Opening of a space park in London with a lot of music and fanfare.
- A timeline of the Covid pandemic recession in North America and Europe
- Deaths resulting from the Covid pandemic and implications for vaccination campaigns
- Description of the US withdrawal from Afghanistan and conflict in the Middle East.
- Effects of global warming contributing to Hurricane Ian and devastation caused in Florida
Task 2: News article classifier
I used a Kaggle dataset [1] about news articles of several different categories to train a classifier. From the raw data, the preprocessing step was really simple because of the embedding API provided to us. For each news article, there was a short description field, which I directly fed into the embedding to obtain a numerical representation of the data. For simplicity, I only selected 7 of the several categories available in this dataset due to the time limitations of the API. Then, I converted these categories into numerical values and fed them along with their respective embeddings into a random forest classifier. After training, I adjusted the maximum depth to be 7, which provided the best testing accuracy.
To make a convenient frontend, I deployed the random forest classifier model to the Streamlit cloud
References
[1] https://www.kaggle.com/datasets/rmisra/news-category-dataset?resource=download
Built With
- python
- scikit-learn
- streamlit

Log in or sign up for Devpost to join the conversation.