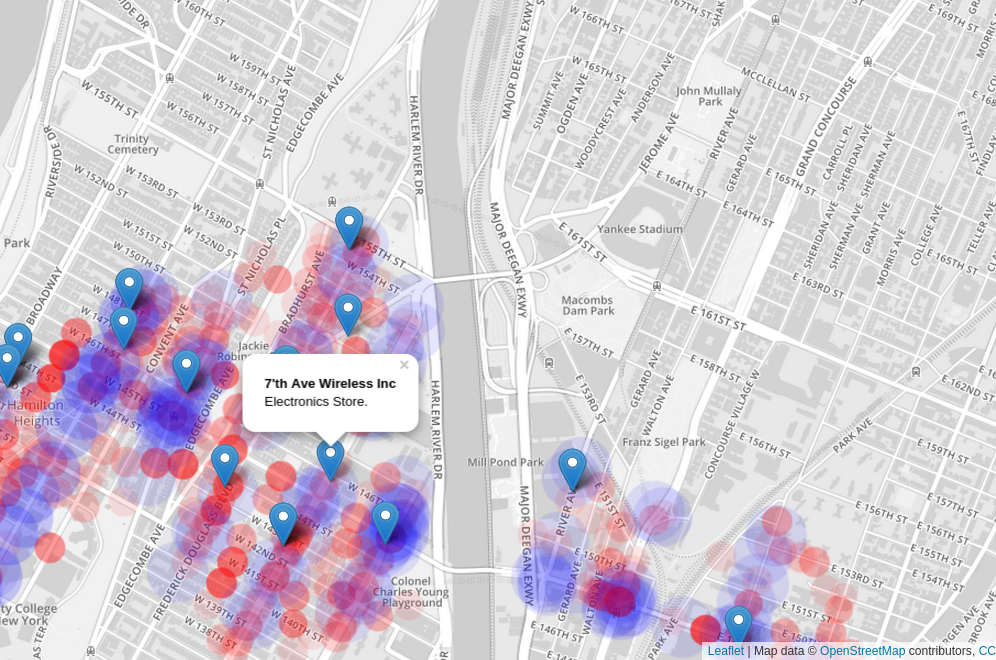

New York Startup Index provides an interactive view of the good and bad of the city, presented in a way that allows you to easily determine the best and worst places to launch a startup. Information about public transportation, local businesses, and crime information are all aggregated on a single map to give you a quick overlay of both historical and real-time information that will allow you to quickly decide where you want to launch a startup.
What's cool about it
Have you ever wondered what the most dangerous parts of New York City were? Or maybe where other tech companies are in the city? The interactive maps provided by New York Startup Index provide all of the information, and more. You can look around the map and unlock the hidden data you never knew existed as you are presented with information on the most common crimes (and the locations that they were reported), places to pick up public transportation, and where other tech companies are around you.
As not all information is relevant to everyone, we provide awesome filters that will let you display only the information you care about. And by using highly scalable technologies like MongoDB and open data sets that are freely available, the open source code base makes it possible to implement this for other cities and fields.
What inspired us
After watching numerous talks at conferences where people worked with open data sets to solve important problems, like finding the two fire hydrants that raked in the most cash in parking violations, we were inspired to use open data in this hack. After seeing the interesting data sets that were made available with New York City's push for releasing open data sets, we decided to pull together some of the most informative ones to plot together on a common map.
How we did it
New York Startup Index takes multiple open data sets and provides an interactive map that allows you to move around the city and see how different areas compare. While some of the data was available in the end format that we were looking for, GeoJSON, we needed to write some custom scripts to parse CSV files and extract the important information from them so we could convert them to a usable GeoJSON format. This data was then stored in a MongoDB database, allowing us to use their excellent geospatial data support to filter down the data sets to just the locations we were looking for.




Log in or sign up for Devpost to join the conversation.