-
-
NeutronNoodle
-
Question 1
-
Admin Dashboard
-
-
-
-

-
Confidence ratio
-

About Neutronoodle
Inspiration
Every team eventually encounters the same invisible problem: knowledge exists, but accessibility does not. Important answers are buried across PDFs, onboarding guides, internal documentation, archived chats, and forgotten folders. New employees repeatedly ask the same questions, while experienced team members unintentionally become human search engines.
We wanted to build the tool we wished we had during internships, hackathons, and collaborative projects — a system where anyone could upload documents, ask questions naturally, and receive accurate answers backed by verifiable sources.
That idea became Neutronoodle: an AI-powered internal knowledge assistant designed to make organizational knowledge searchable, trustworthy, and easy to retrieve — without hallucinations, dead links, or unreliable guesswork.
What Neutronoodle Does
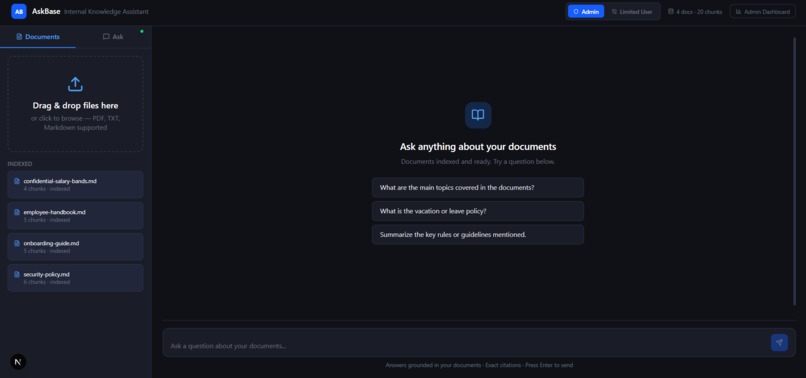
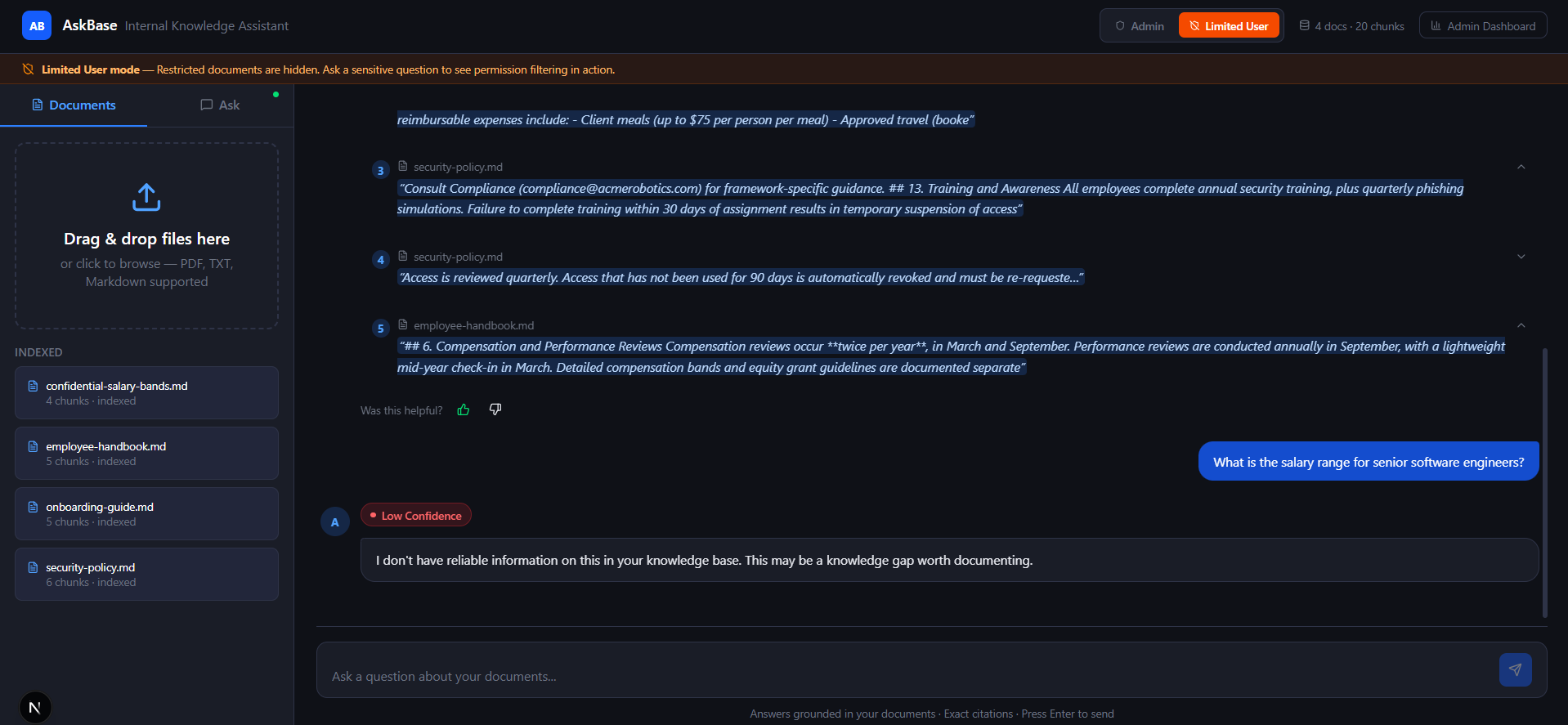
Neutronoodle transforms collections of documents into a citation-grounded conversational assistant with enterprise-grade reliability and access control.
Users can:
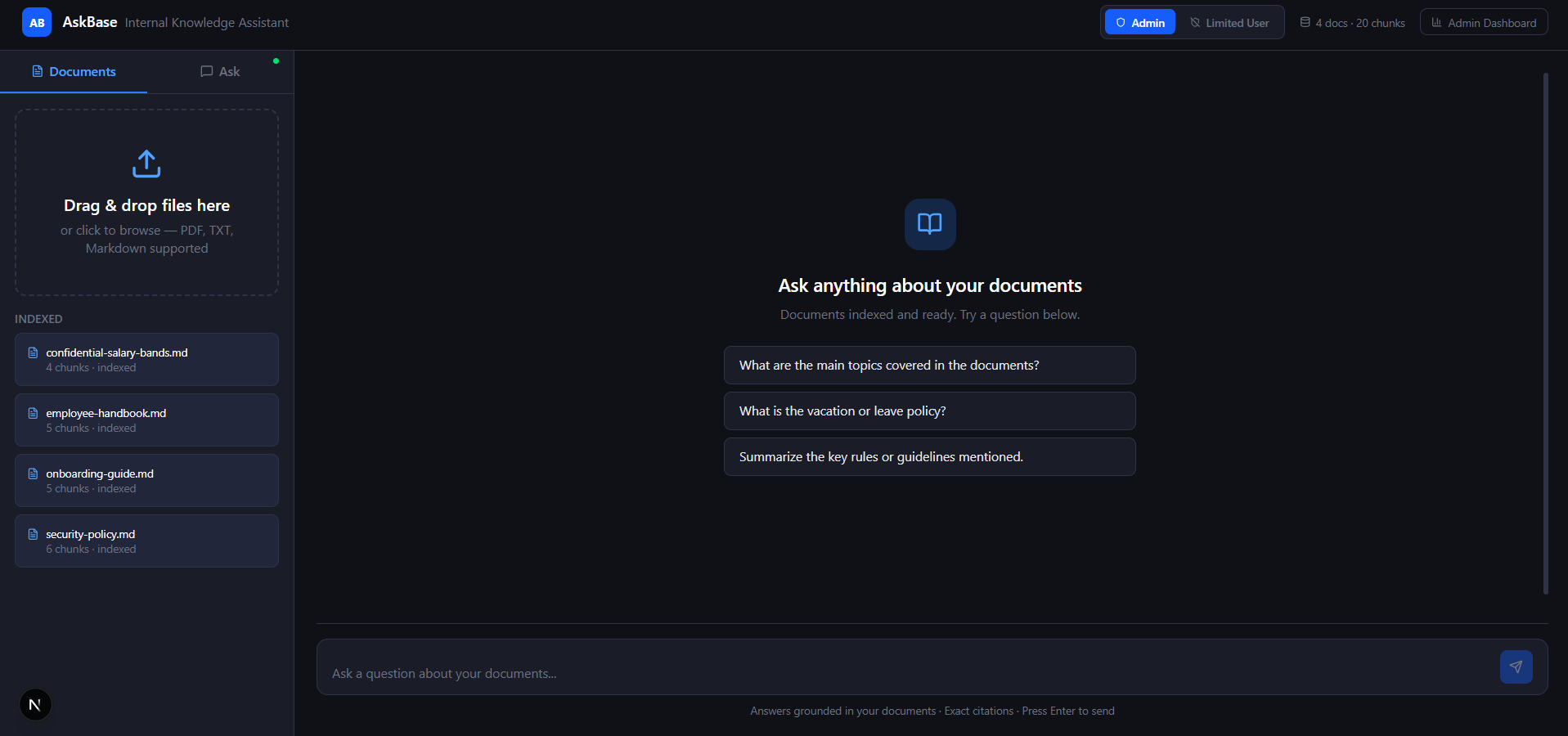
- Upload PDFs, Markdown files, and text documents through a clean drag-and-drop interface.
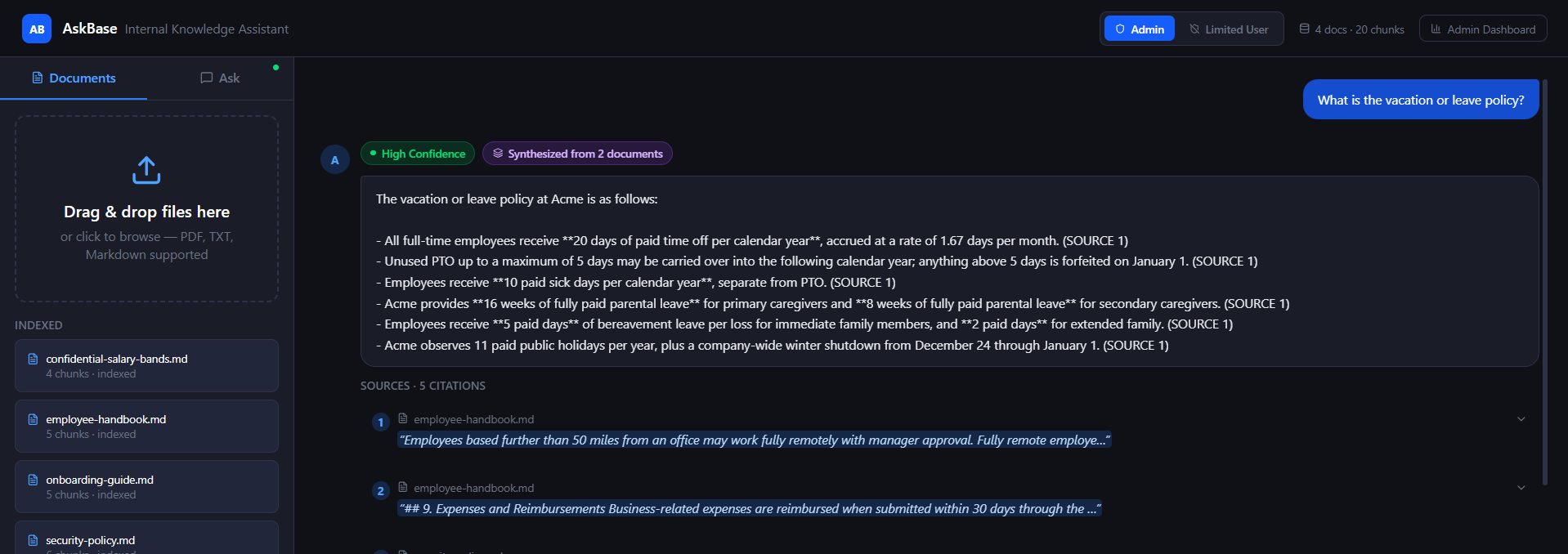
- Ask questions in natural language and receive concise, grounded answers.
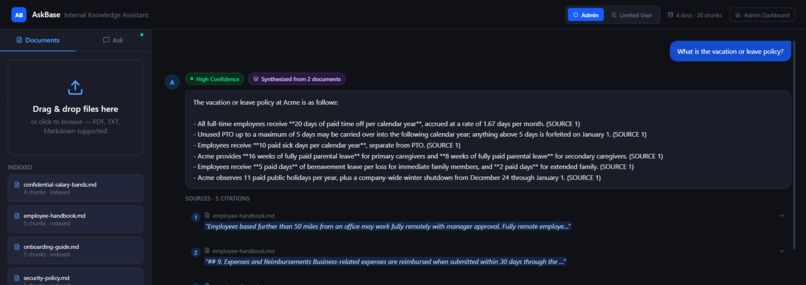
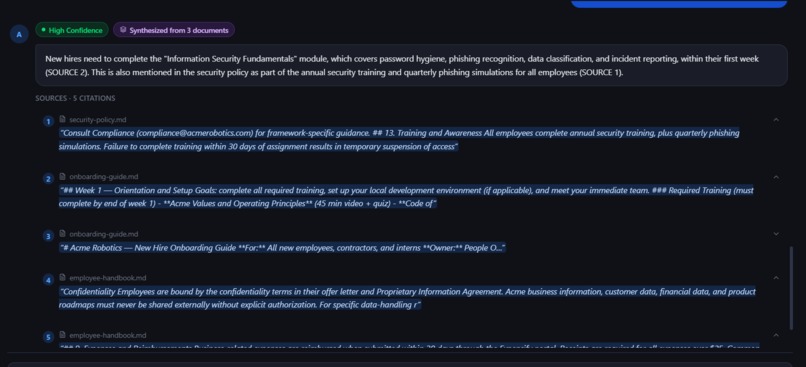
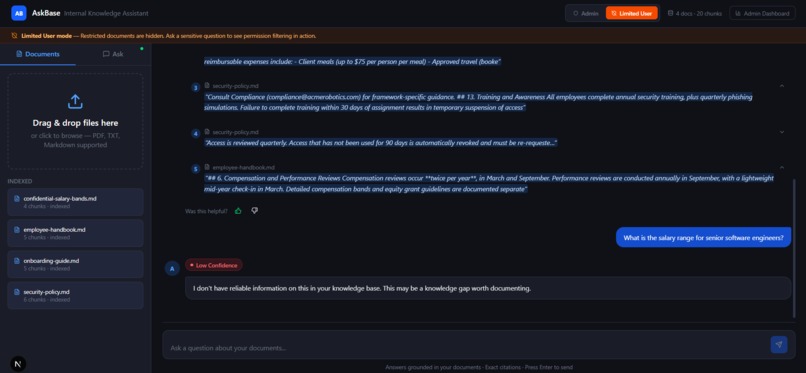
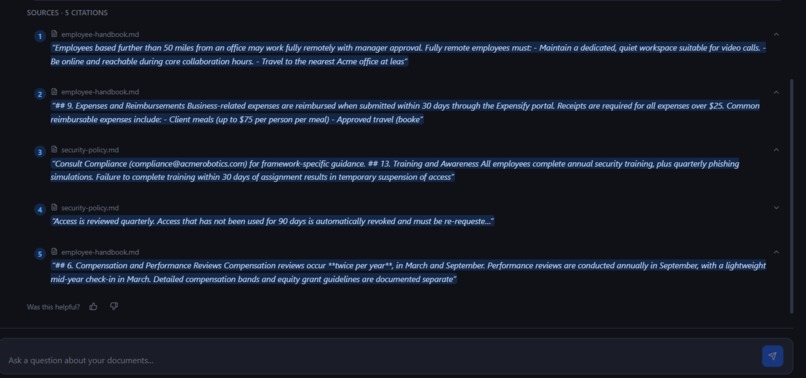
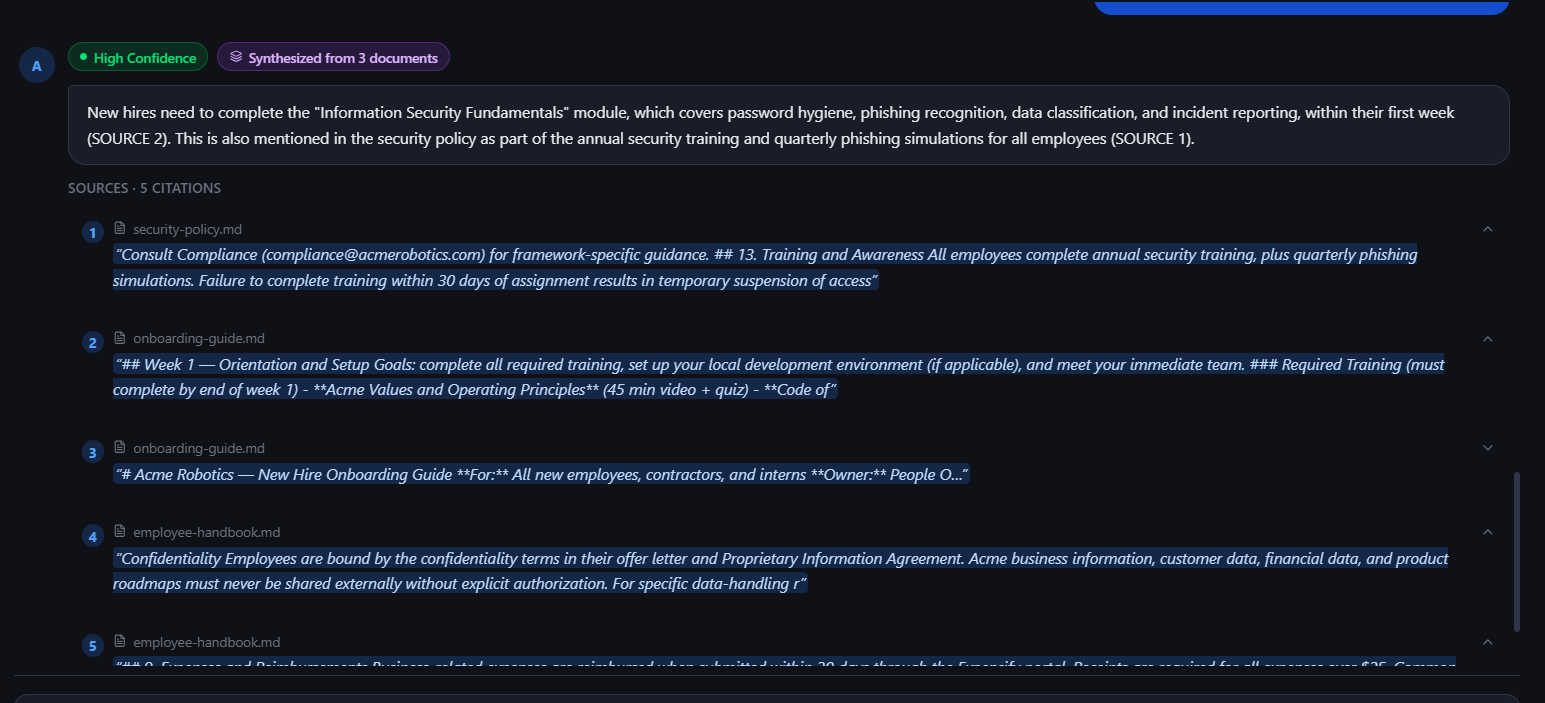
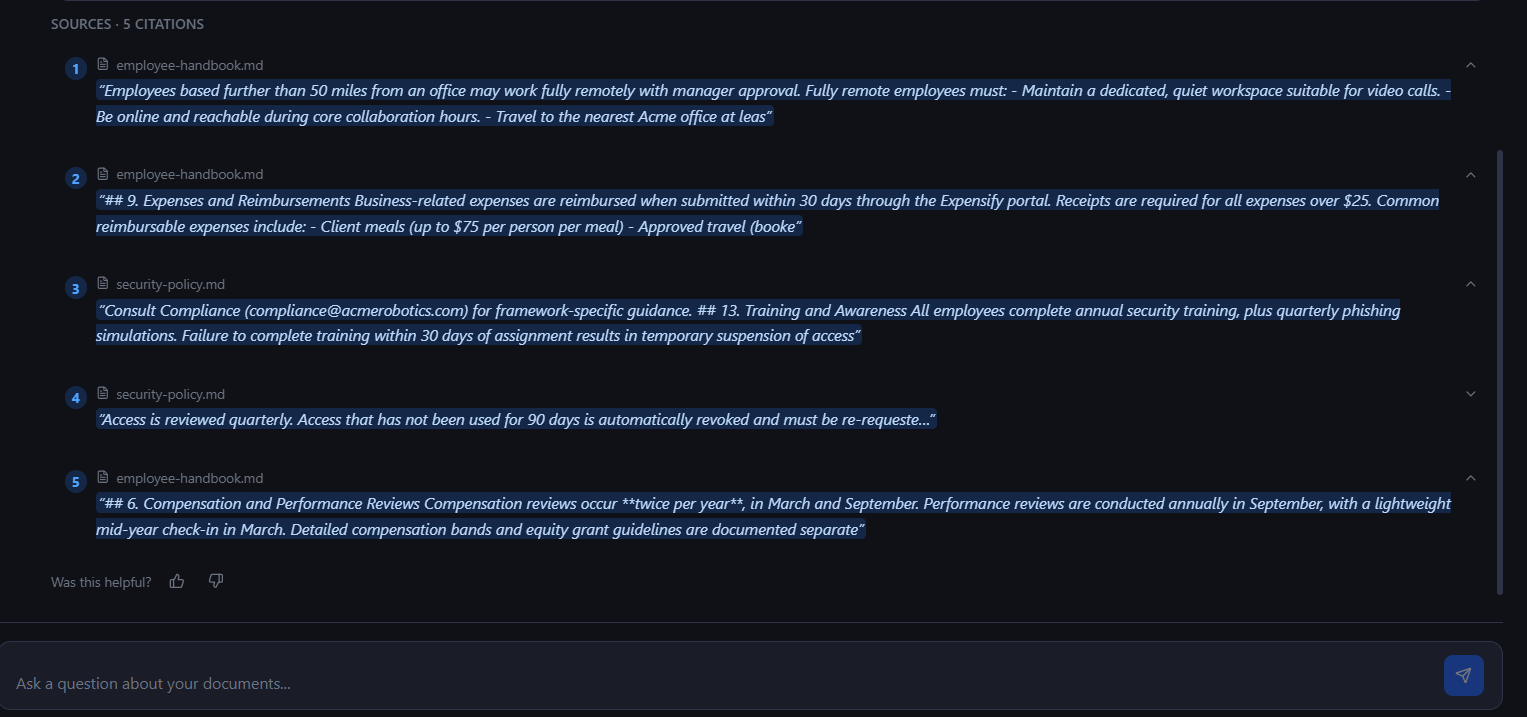
- Inspect inline citations linked directly to the original source passages.
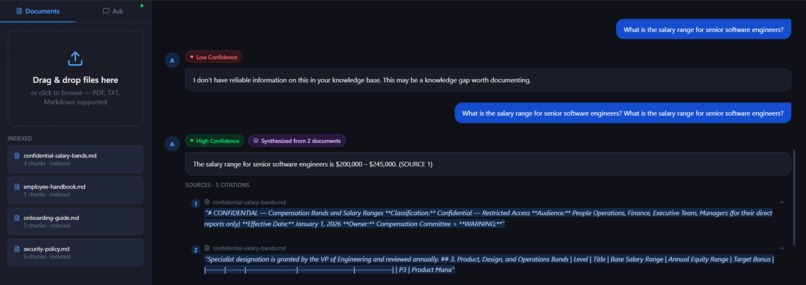
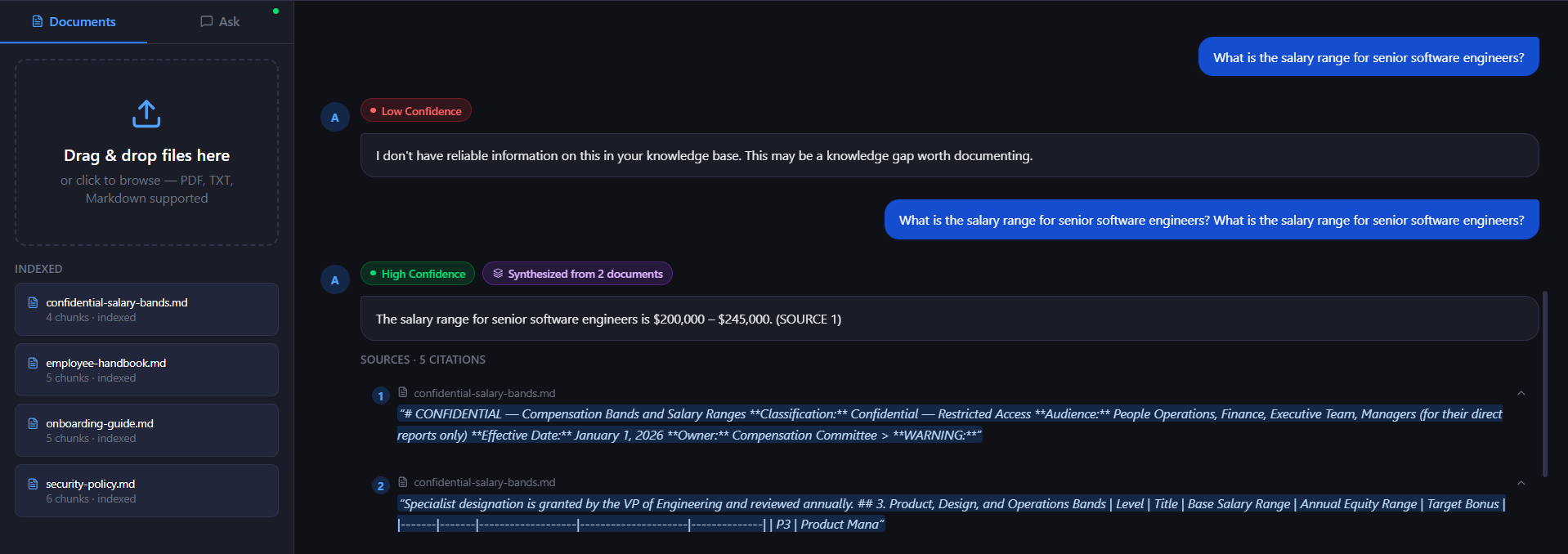
- View confidence indicators (High / Medium / Low) to estimate answer reliability.
- Switch between Admin and Limited User roles for permission-aware document access.
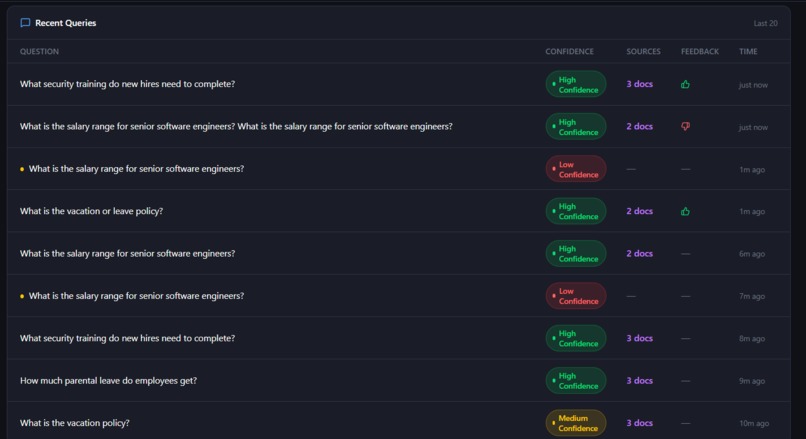
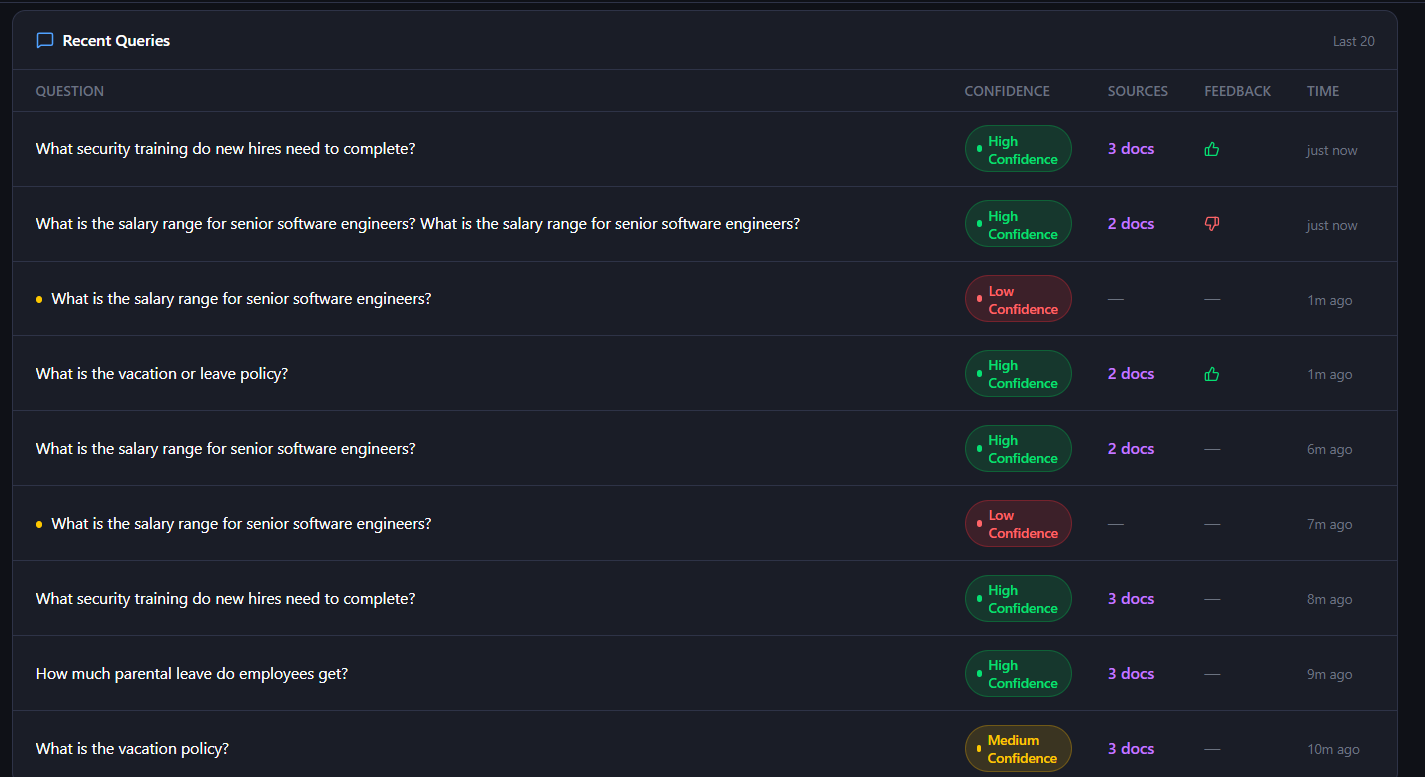
- Monitor platform activity through a built-in Admin Dashboard with analytics and knowledge-gap detection.
Instead of vague responses such as “I think it was somewhere in the handbook,” Neutronoodle returns traceable and verifiable answers tied directly to source evidence.
How We Built It
Neutronoodle was designed as a modular Retrieval-Augmented Generation (RAG) system with graceful degradation at every layer. Rather than relying entirely on a single vendor, the architecture supports pluggable services with automatic fallback mechanisms.
If an API becomes unavailable or a key is missing, the system continues functioning using alternative providers.
Technology Stack
Frontend
- Next.js 16
- React 19
- TypeScript
- Tailwind CSS v4
Backend
- FastAPI
- Server-Sent Events (SSE) for live ingestion progress
AI & Retrieval
- Vector Database: ChromaDB with persistent HNSW indexing
Embeddings:
- Preferred: Cohere
embed-english-v3.0 - Fallback: OpenAI
text-embedding-3-large
- Preferred: Cohere
Retrieval: Hybrid dense-vector + BM25 search
Rank Fusion: Reciprocal Rank Fusion (RRF)
Reranking: Cohere Rerank v3
Generation:
- Primary: Groq-hosted Llama 3.3 70B
- Fallback: Claude 3.5 Sonnet with Citations API
File Processing
- PyMuPDF (primary PDF extraction)
- pypdf (fallback extraction)
UI Components
- react-dropzone
- lucide-react
The frontend provides a polished drag-and-drop upload experience with real-time progress visualization, while the backend handles parsing, chunking, embedding, indexing, retrieval, reranking, and grounded generation.
System Pipeline
The workflow of Neutronoodle is divided into two major stages.
1. Document Ingestion
- Detect file type and extract text.
- Parse PDFs using PyMuPDF with pypdf fallback support.
- Split content into semantic chunks of 512 tokens with approximately 10% overlap.
- Generate embeddings for each chunk.
- Store embeddings in ChromaDB using batched indexing.
- Stream ingestion progress to the frontend using SSE.
Ingestion Flow
Upload → Parse → Chunk → Embed → Index → Store
2. Query Processing
- Perform semantic vector retrieval.
- Execute BM25 lexical retrieval in parallel.
- Fuse rankings using Reciprocal Rank Fusion.
- Rerank retrieved chunks using Cohere Rerank.
- Apply permission-aware filtering.
- Pass grounded context into the LLM.
- Generate responses with citations and confidence scores.
Query Flow
User Query
↓
Hybrid Retrieval
↓
RRF Fusion
↓
Reranking
↓
Permission Filtering
↓
LLM Generation
↓
Grounded Answer + Citations
This architecture balances semantic understanding with exact keyword matching, making the system effective for technical documents, acronyms, policies, identifiers, and enterprise documentation.
The Mathematics Behind Neutronoodle
To retrieve semantically relevant information, Neutronoodle uses cosine similarity between query embeddings and document chunk embeddings:
$$ \text{sim}(\mathbf{q}, \mathbf{c}) = \frac{\mathbf{q} \cdot \mathbf{c}} {|\mathbf{q}| , |\mathbf{c}|} $$
This metric measures how closely a document chunk aligns with the user’s query in high-dimensional embedding space.
For lexical relevance, the system uses the BM25 ranking algorithm:
$$ \text{BM25}(q, d) = \sum_{t \in q} \text{IDF}(t) \cdot \frac{ f(t,d)(k_1 + 1) }{ f(t,d) + k_1 \left( 1 - b + b \cdot \frac{|d|}{\text{avgdl}} \right) } $$
BM25 prioritizes exact keyword matches and technical terminology that embedding models may miss.
To combine semantic and lexical retrieval, Neutronoodle applies Reciprocal Rank Fusion (RRF):
$$ \text{RRF}(d) = \sum_{r \in R} \frac{1}{k + \text{rank}_r(d)}, \quad k = 60 $$
This hybrid strategy consistently outperformed standalone semantic or lexical retrieval during evaluation.
Beyond Q&A — Enterprise Features
Neutronoodle extends beyond a standard chatbot by providing operational and enterprise-focused capabilities.
Role-Based Access Control
Admin and Limited User roles ensure permission-aware retrieval. Sensitive documents containing keywords such as:
confidentialsalaryhrprivaterestricted
are automatically filtered for non-admin users.
Cross-Source Synthesis Indicator
When answers are synthesized from multiple documents, the UI displays a badge indicating the number of contributing sources.
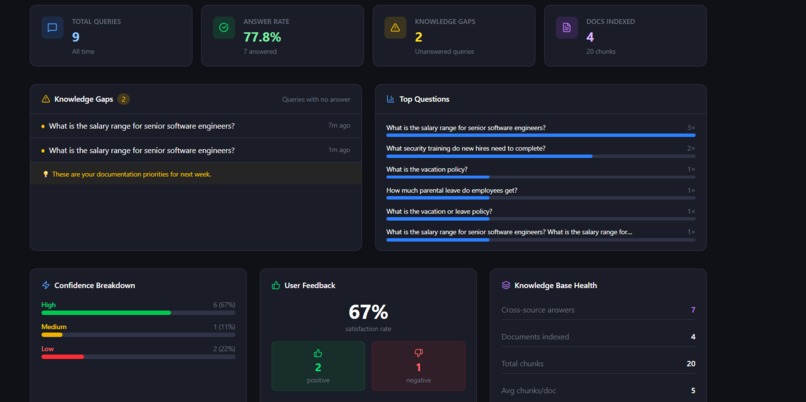
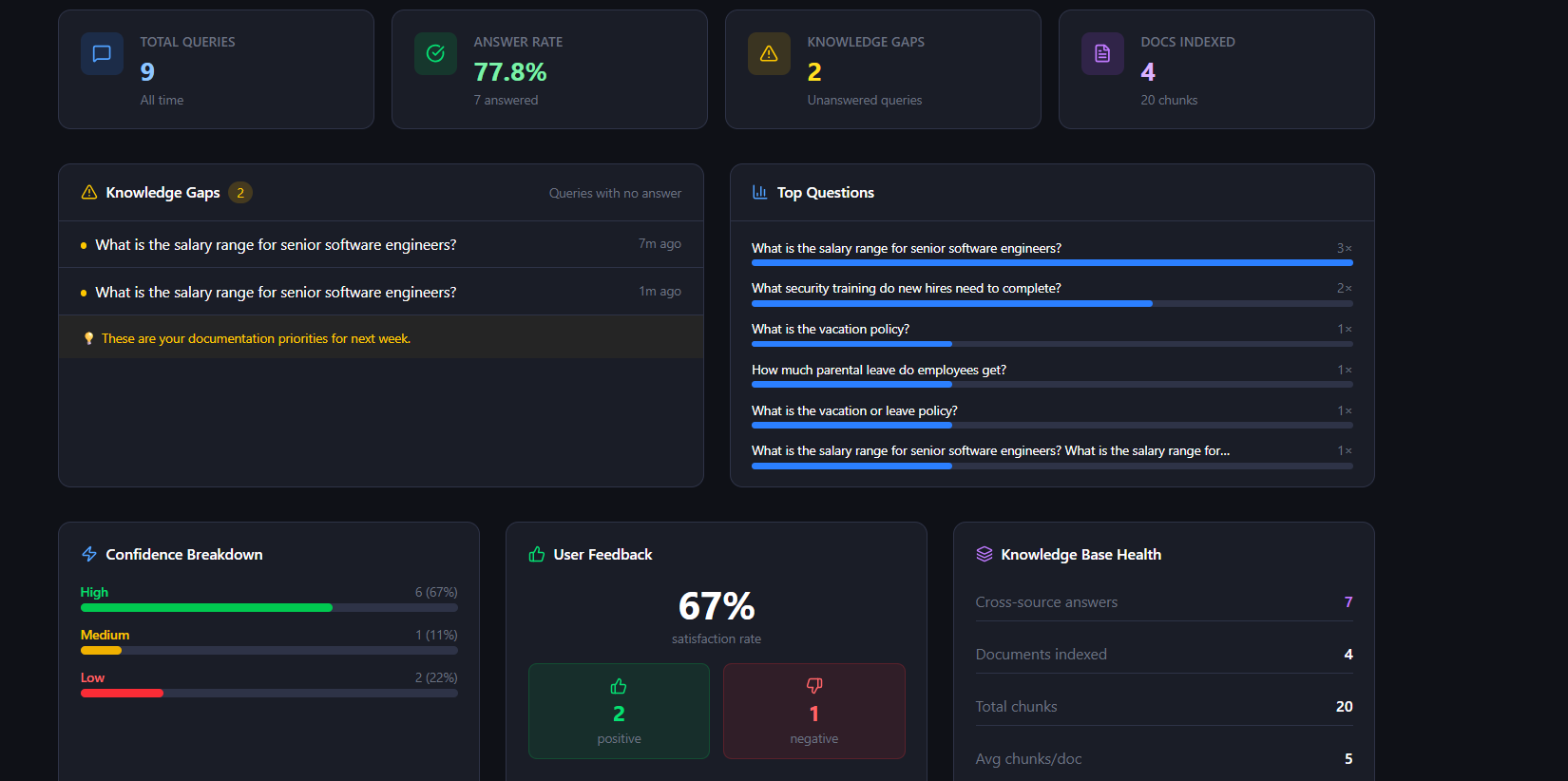
Admin Dashboard
The /admin dashboard provides:
- Total query analytics
- Confidence score distribution
- User feedback statistics
- Top searched questions
- Knowledge-gap detection
- Recent activity monitoring
Robust PDF Handling
Dual-engine extraction ensures support for malformed and complex PDFs.
Streaming Ingestion
Large document uploads are processed in batches with real-time SSE progress updates.
Graceful Degradation
Every major AI dependency has an automatic fallback path to avoid system-wide failures.
Challenges We Faced
1. Finding the Right Chunk Size
Smaller chunks lost context, while larger chunks diluted embedding quality. After experimentation, we selected 512-token chunks with approximately 10% overlap as the optimal balance.
2. Reliable Citations Without Hallucinations
Early versions fabricated citations and page numbers. We solved this using:
- Anthropic Citations API for fallback generation
- Strict source-grounded prompting for Groq-hosted Llama
3. Real-Time SSE Streaming
Coordinating ingestion progress across parsing, embedding, indexing, and batching required careful backend state management.
4. Graceful Degradation Across APIs
External services fail unpredictably. We designed automatic fallback systems to ensure uninterrupted functionality.
5. Confidence Calibration
Mapping retrieval scores into reliable confidence indicators proved difficult and remains an area for future improvement.
6. Permission-Aware Retrieval
Filtering had to occur before generation to ensure restricted content never entered the LLM context.
What We Learned
- Retrieval quality matters more than generation quality.
- Hybrid search consistently outperforms standalone retrieval.
- Citations dramatically improve user trust.
- Open-source models are increasingly competitive.
- Fallback systems are critical for reliability.
- SSE provides a significantly better UX than polling.
- Knowledge-gap analytics become invaluable for improving documentation.
What's Next
Planned Features
- Slack, Notion, and Google Drive connectors
- Folder-level and document-level ACLs
- Multi-turn conversational memory
- Automated retrieval evaluation harnesses
- Confidence calibration models trained on user feedback
- Advanced enterprise analytics and monitoring
Conclusion
Neutronoodle demonstrates how modern Retrieval-Augmented Generation systems can evolve beyond simple chat interfaces into trustworthy enterprise knowledge platforms.
By combining hybrid retrieval, grounded citations, permission-aware filtering, robust fallback systems, and scalable ingestion pipelines, Neutronoodle transforms fragmented organizational knowledge into an accessible and verifiable conversational experience.
The project reinforced an important lesson:
A powerful AI system is not defined solely by the intelligence of its language model, but by the reliability, transparency, and quality of the context it retrieves.
Built With
- bm-25
- chromadb
- fastapi
- groq
- llama3.3
- lucide-react
- nextjs
- pymupdf
- react
- react-dropzone
- reciprocalrankfusion
- tailwind
- typescript

Log in or sign up for Devpost to join the conversation.