Inspiration
Waiting rooms are a nightmare for patients whose condition can deteriorate in minutes. A drooping face, a pounding head, and slurred speech can go unnoticed when nurses are swamped. In Canada, long wait times are a major barrier to timely care. We strive to create a digital safety net that instantly flags high‑risk patients so clinicians can intervene before it’s too late. In developing countries, where many people cannot afford healthcare, our application offers supports to indivuals feeling unwell.
What it does
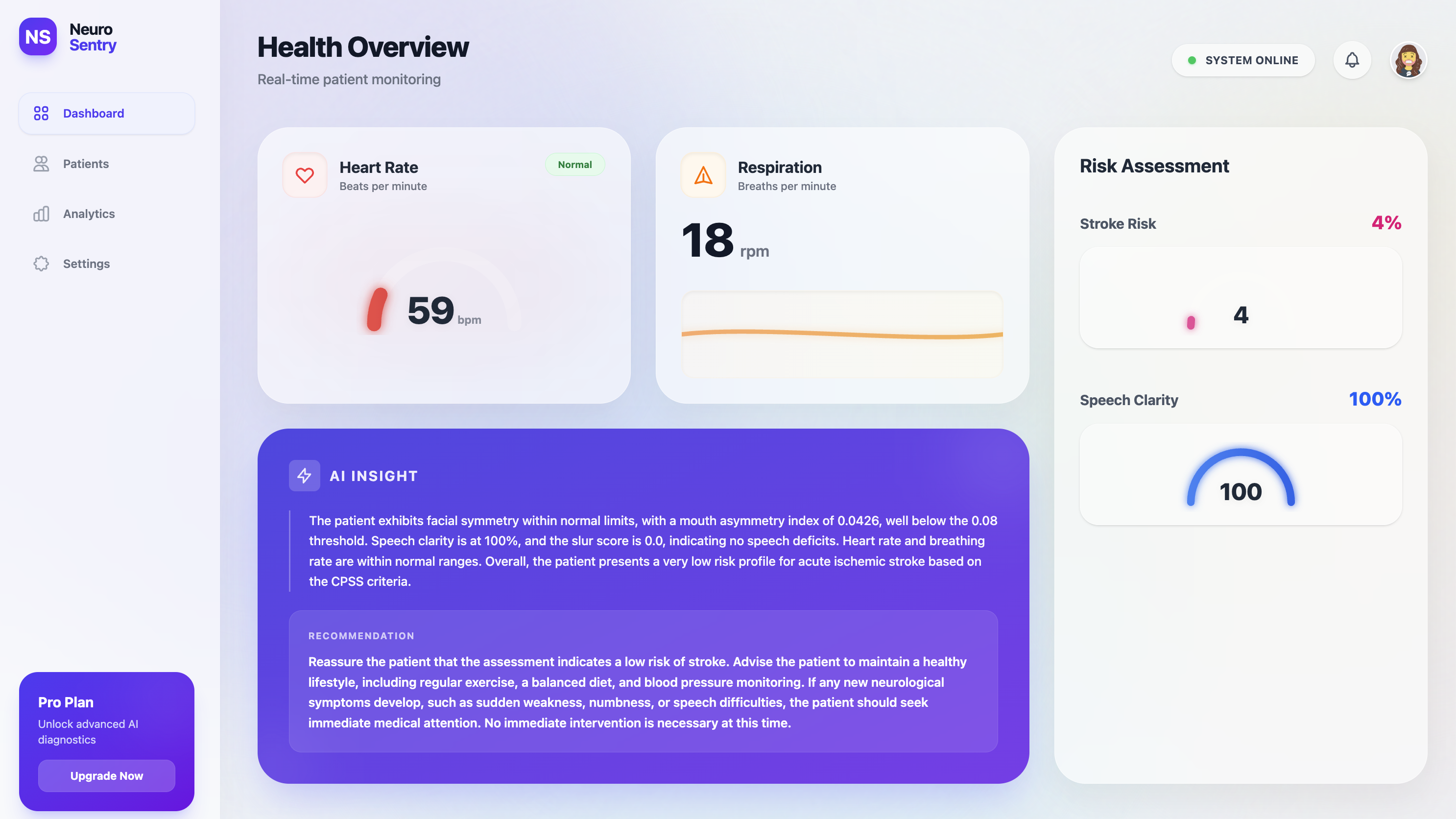
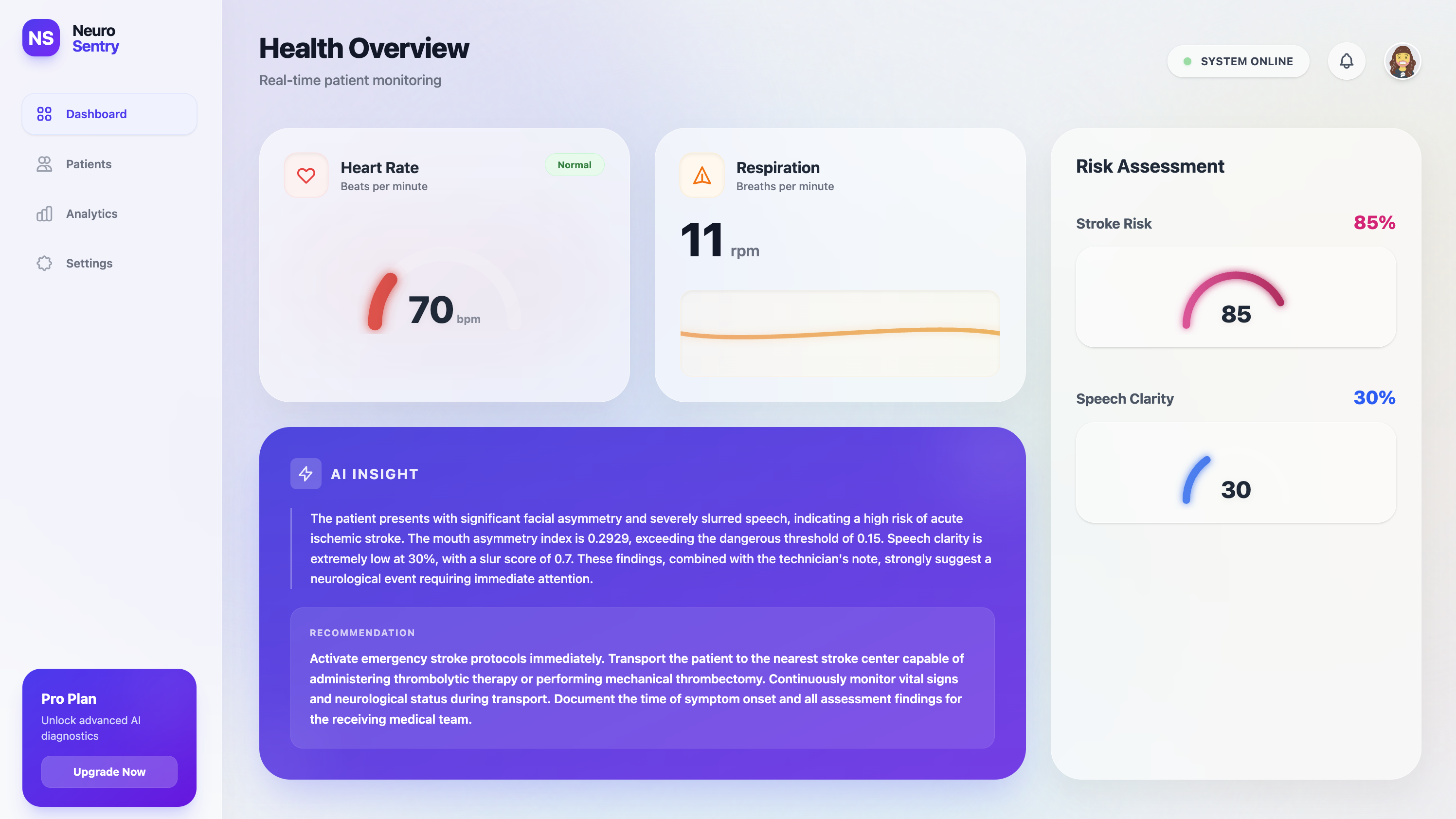
Neuro-Sentry uses your phone's camera and microphone to monitor stroke warning signs in real time. It captures facial asymmetry through precise landmark tracking, analyzes speech patterns for slurring or clarity issues, and measures vital signs like heart rate. The system combines these biometric signals with AI-powered analysis to generate an instant stroke-risk assessment, helping triage patients in waiting rooms or providing preliminary guidance when professional care isn't immediately accessible.
How we built it
We architected Neuro-Sentry as a real-time, multi-layered system where each component plays a critical role:
iOS Bridge – Built with SwiftUI and the Presage SmartSpectra SDK to capture facial-mesh landmarks directly from the phone's camera. It streams vital signs over WebSocket to our backend for instant processing.
Frontend – A React + TypeScript web interface powered by Vite for rapid development. We used Framer Motion for fluid animations and vanilla CSS with glassmorphism effects to create a premium, modern UI. The frontend integrates seamlessly with the Web Audio API through our custom audioRecorder.ts module.
Audio Capture – Leverages the Browser Web Audio API with AudioWorkletNode to record from the desktop microphone. Recording begins automatically when the iOS session starts, then sends the WAV audio blob to the backend for analysis.
Backend – FastAPI with Uvicorn (ASGI) handles high-performance async operations. We use Pydantic for data validation, WebSockets for real-time streaming, and the Google GenAI SDK (Gemini-2.0 Flash) for transcription, speech-clarity scoring, and generating comprehensive AI insights.
The RAG Piece in the Backend (Gemini Prompt)
In backend/gemini_prompt.py, we embed a static clinical knowledge base directly into the prompt that Gemini receives. We call this a lightweight Retrieval‑Augmented Generation (RAG) system because:
Retrieval – The CLINICAL_KNOWLEDGE_BASE string (a multi-line block of medical rules, CPSS protocol, and Sunnybrook thresholds) is hard-coded in the file. It’s the “retrieved” reference material that the model can consult.
Augmentation – When build_triage_prompt() builds the final prompt, it concatenates user-generated telemetry (vitals, face‑mesh asymmetry, speech‑clarity scores) with this knowledge base.
Generation – Gemini then produces a strictly structured JSON report. Its reasoning is grounded in the supplied medical text, preventing hallucinations and ensuring the output follows clinical guidelines.
Data Processing – NumPy and SciPy crunch the numbers while Librosa extracts audio features. We developed custom geometric algorithms to calculate a normalized mouth-asymmetry index—a key indicator for stroke detection.
Configuration – Environment variables via .env (dotenv) keep our Gemini API key secure and out of version control.
All components communicate through WebSocket channels (/presage_stream for video/vitals, /live_state for UI updates), enabling synchronized audio-video analysis. The result is a cohesive, single-screen interface that delivers AI-driven stroke-risk insights in real time.
Data Processing – NumPy and SciPy crunch the numbers while Librosa extracts audio features. We developed custom geometric algorithms to calculate a normalized mouth-asymmetry index—a key indicator for stroke detection.
Configuration – Environment variables via .env (dotenv) keep our Gemini API key secure and out of version control.
All components communicate through WebSocket channels (/presage_stream for video/vitals, /live_state for UI updates), enabling synchronized audio-video analysis. The result is a cohesive, single-screen interface that delivers AI-driven stroke-risk insights in real time.
Challenges we ran into
1) Insufficient data to train our models from scratch
2) Presage provided 478 facial landmark points, which could not be used directly in Gemini. Instead, we had to translate these points into clinical scores using the Sunnybrook Facial Grading System
3) Limited experience with integrating Swift SDK to our backend
4) Gemini could not infer the file type, rejecting our audio
Accomplishments that we're proud of
1) Successfully delivering automated stroke-risk analysis.
2) Generating a reliable, data-driven risk score.
3) Integrating Retrieval-Augmented Generation (RAG) to enhance reasoning and accuracy
What we learned
1) Effective use of Swift
2) Functions of Presage
What's next for Neuro-Sentry
In the future, we aim to expand our detection capabilities to conditions such as asthma attacks, cardiac events, and more. This will further help hospital workers by giving them real-time risk alerts, reducing diagnostic delays, and ensuring the most critical patients receive immediate attention.

Log in or sign up for Devpost to join the conversation.