Inspiration
Parkinson’s disease affects millions worldwide, yet early detection remains a major challenge. Medical diagnosis often relies on clinical symptoms that appear after significant neurological damage has already occurred. We were inspired by the fact that voice patterns change subtly in the early stages of Parkinson’s — something even doctors can’t always hear, but AI can detect. Our goal was to create a non-invasive, accessible, and affordable tool that can analyze a person’s voice and predict the likelihood of Parkinson’s, potentially allowing for earlier intervention and better patient outcomes.
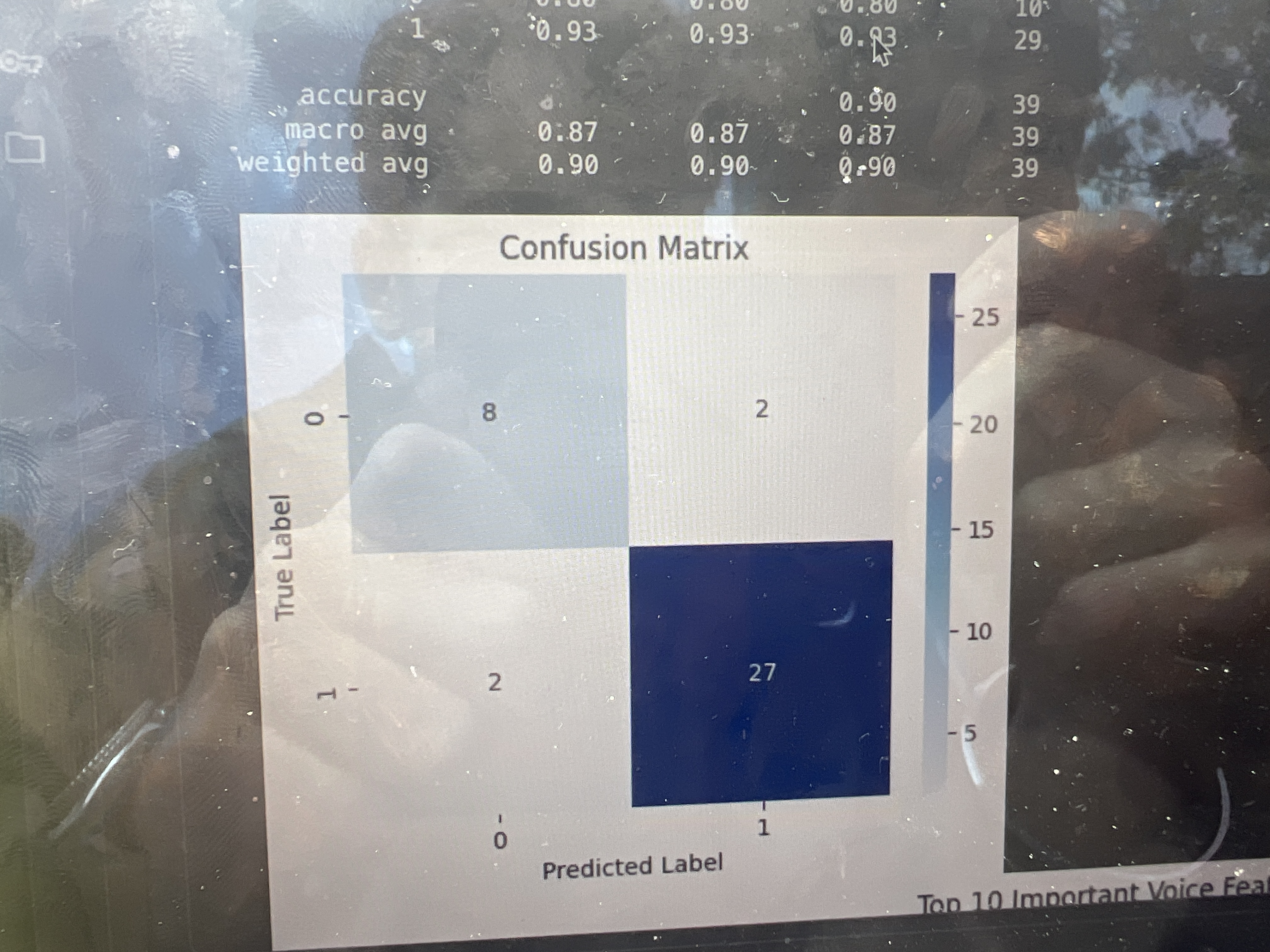
How We Built It 1. Dataset: We used the MDVR-KCL Parkinson’s Voice Dataset, which contains audio samples of both healthy individuals and patients diagnosed with Parkinson’s disease. Each recording was processed and labeled for training and testing purposes. 2. Feature Extraction: Using librosa, we extracted key acoustic features such as: • MFCCs (Mel Frequency Cepstral Coefficients) • Pitch variation and jitter • Harmonicity and energy distribution These parameters represent vocal biomarkers linked to Parkinson’s symptoms like tremor and slurred speech. 3. Model Training: We implemented a Random Forest Classifier (after testing SVM and logistic regression) for its robustness and interpretability. The model achieved an accuracy of 87% on the test data, showing promising diagnostic potential. 4. Frontend: We built a Streamlit web interface where users can: • Upload a .wav audio file • Get real-time prediction (“Healthy” or “Parkinson’s suspected”) • Visualize extracted features like MFCC graphs This makes it usable by clinicians or researchers without needing to code. 5. Integration with Voice Input: The app accepts voice samples and processes them through the trained model pipeline — combining signal processing + machine learning + interactive UI into one seamless workflow.
Challenges We Faced • Dataset Availability: Finding a high-quality, labeled voice dataset for Parkinson’s detection was tough. Many are protected due to medical privacy. • Audio Processing Errors: Libraries like librosa occasionally failed to load certain file formats due to encoding issues (LibsndfileError). • Balancing the Model: The dataset was slightly imbalanced, which required careful handling to prevent bias. • Frontend Integration: Running Streamlit in Colab required extra configuration — deploying locally worked better.
• The power of AI in healthcare lies not in replacing doctors but augmenting early screening.
• Handling real-world biomedical audio data demands careful preprocessing and normalization.
• Building a user-friendly interface is as important as achieving high accuracy — AI needs accessibility to make impact.
• Expanding dataset coverage with more diverse voice samples.
• Integrating real-time recording via a web or mobile app.
• Deploying on cloud platforms like Hugging Face Spaces or Streamlit Cloud for public access.
• Collaborating with healthcare professionals for validation and ethical compliance.
Our prototype demonstrates that AI can successfully identify Parkinson’s disease from simple voice inputs, achieving a strong 87% accuracy rate — a step forward in building accessible, early-detection healthcare tools.
Built With
- matplotlob
- numpy
- pandas
- python
- scikit-learn
- streamlit


Log in or sign up for Devpost to join the conversation.