-
-
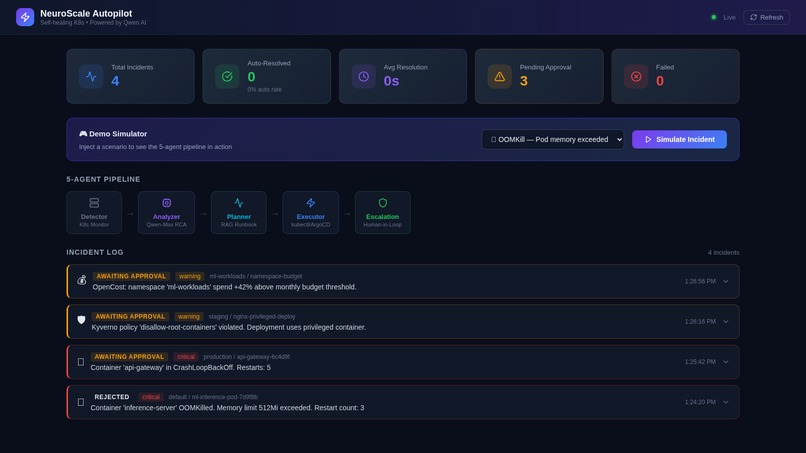
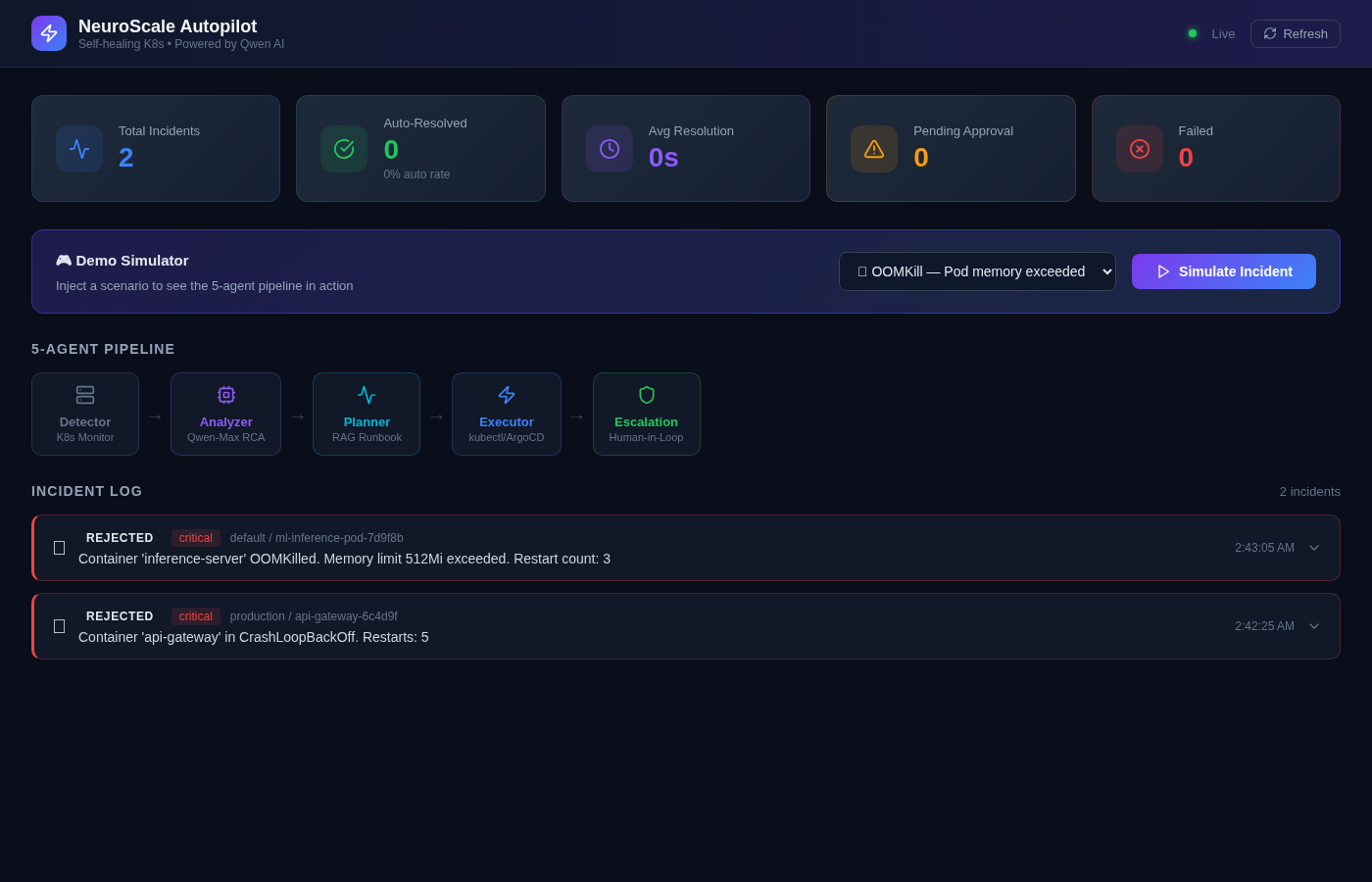
Dashboard-main view
-
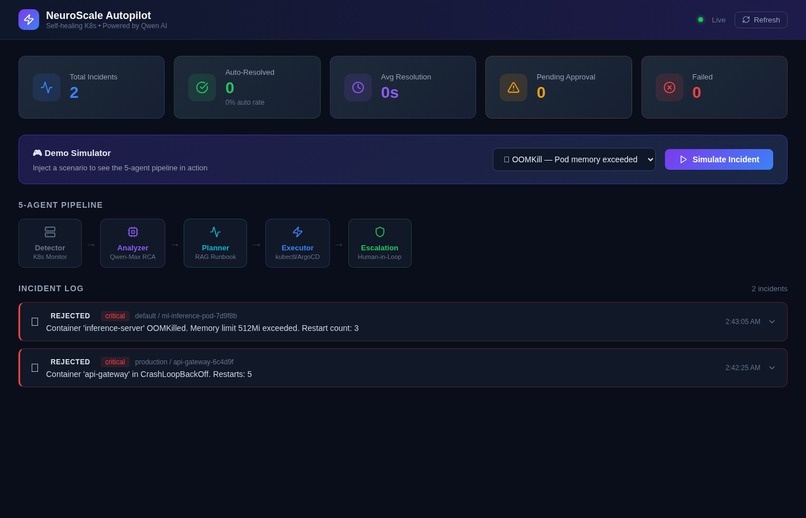
Active Incident Log - 2 Incident Types
-
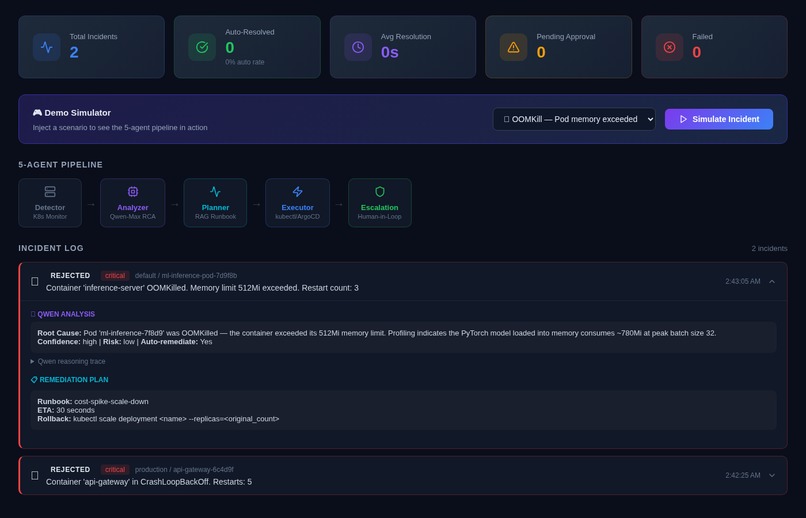
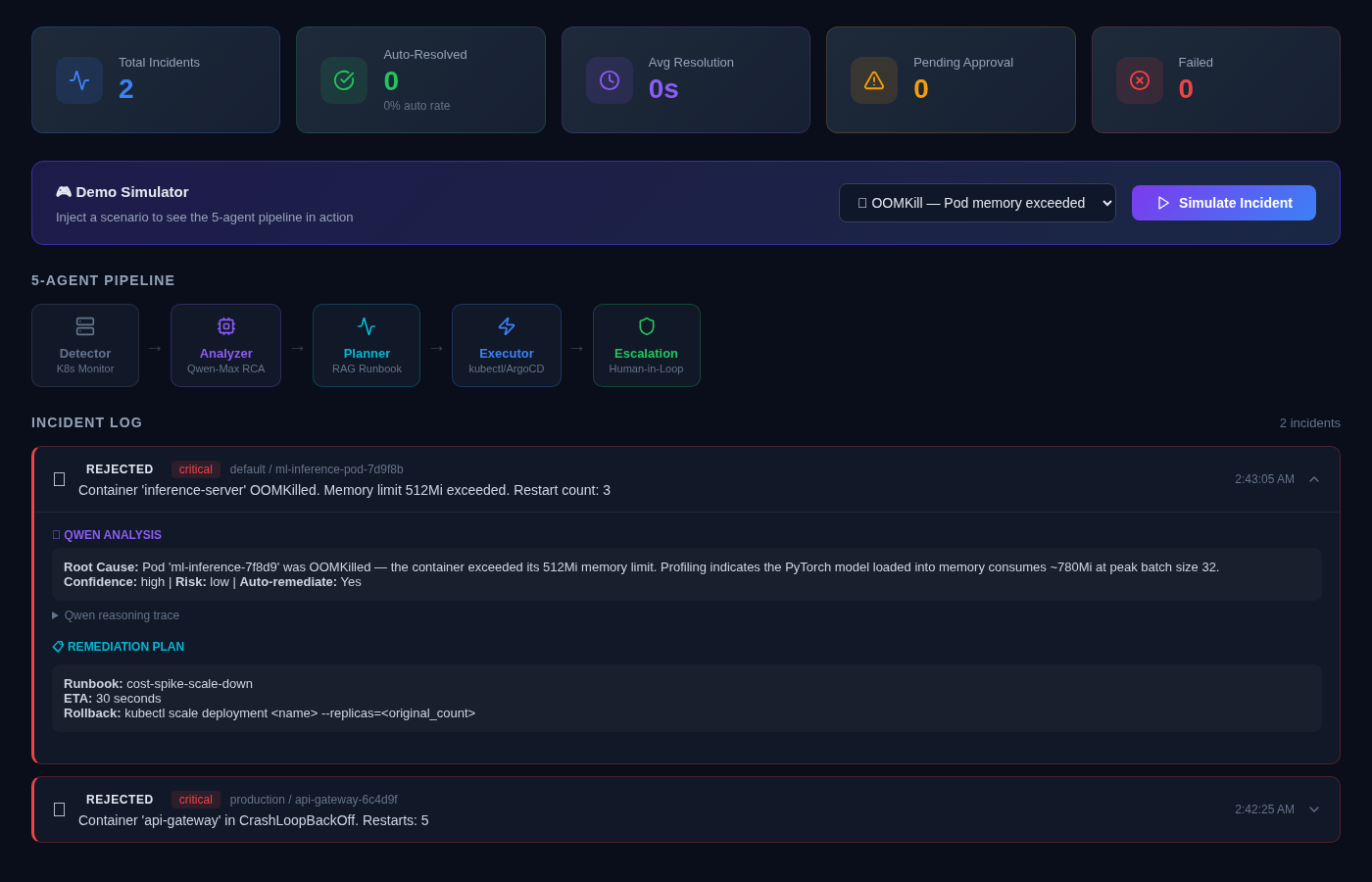
Qwen Analysis + Remediation Plan + Human Approval
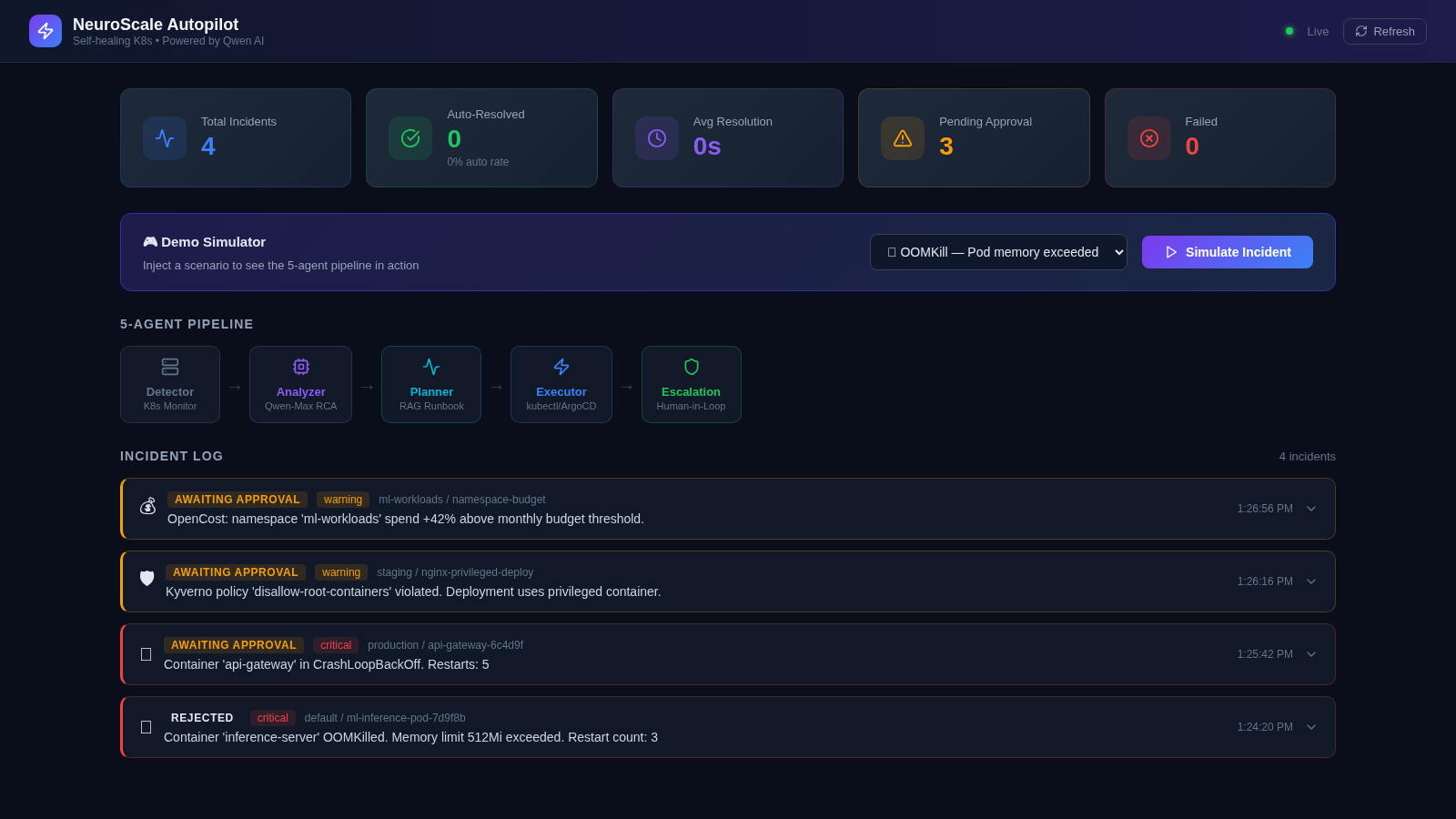
NeuroScale Autopilot
Inspiration
Every DevOps engineer knows the feeling.
It's 2:47 AM. Slack erupts. A production pod is in CrashLoopBackOff. You unlock your phone with one eye open, SSH in, scan the logs, remember which runbook handles this pattern, paste the same kubectl command you've pasted thirty times before, and go back to sleep. The same incident will happen again next week.
I've been that engineer. And after the tenth time, I stopped asking "how do I fix this faster?" and started asking "why am I fixing this at all?"
The root cause is structural. Modern Kubernetes operations generate more signals than any human team can process in real time: OOMKills, CrashLoops, policy violations, cost spikes, ArgoCD drift. The runbooks to fix 80% of these incidents already exist. The pattern recognition required is mechanical. The execution is repetitive. This is exactly the kind of work AI should be doing.
What's missing isn't intelligence, it's architecture. A chat interface that suggests kubectl commands is not automation. A single LLM call that "analyzes" logs is not a system. Real autonomous operations requires a pipeline: detect, diagnose, plan, execute, escalate. Five distinct jobs, done by five agents designed specifically for each one.
That's what I built. NeuroScale Autopilot is the system I wished existed every time that pager went off.
What It Does
NeuroScale Autopilot is a 5-agent autonomous self-healing platform for Kubernetes clusters, powered entirely by the Qwen model family via Alibaba Cloud DashScope.
It runs a continuous closed loop:
Kubernetes Events
|
v
+-------------+ +--------------+ +----------------------+
| DETECTOR |--->| ANALYZER |--->| PLANNER |
| | | Qwen-Max | | Qwen-Embedding RAG |
| Pod Health | | Root Cause | | Runbook Retrieval |
| OOMKills | | Risk Score | | Remediation Plan |
| CrashLoops | | Confidence | +----------+-----------+
| Kyverno | | Auto Flag | |
| OpenCost | +--------------+ v
+-------------+ +----------------------+
| EXECUTOR |
| kubectl subprocess |
| CircuitBreaker |
| ArgoCD Rollback |
| Kyverno Exception |
+----------+-----------+
|
v
+----------------------+
| ESCALATION |
| Qwen-Turbo Summary |
| Slack Webhook |
| Human Approval |
| 300s Auto-Reject |
+----------------------+
Agent 1 - Detector: Watches pod health, OOMKill events, CrashLoopBackOff conditions, Kyverno policy violations, and OpenCost budget alerts via the Kubernetes watch API. Fires structured Alert objects. Fast, cheap, no AI involved - by design.
Agent 2 - Analyzer (Qwen-Max): Receives the alert with full context and returns a structured root cause analysis: root_cause, confidence (0.0-1.0), action_type, risk_level, and an auto_remediate flag that only activates when confidence > 0.75 and risk is bounded.
Agent 3 - Planner (Qwen-Embedding): Uses text-embedding-v3 to run semantic search over a runbook library. The Qwen-Max RCA is embedded and matched against five indexed runbooks to retrieve the most contextually relevant remediation procedure. Produces a RemediationPlan with explicit steps and a requires_approval flag.
Agent 4 - Executor: Runs kubectl commands through a circuit breaker (opens at 3 consecutive failures, resets after 300 seconds). All actions are whitelisted: patch resources, ArgoCD rollback, scale workload, create Kyverno policy exception. No deletes, no exec, no namespace-level mutations - ever.
Agent 5 - Escalation (Qwen-Turbo): For high/critical risk incidents, Qwen-Turbo compresses the full incident context into a concise Slack notification with an approval token. The system waits up to 300 seconds for human response. No response = auto-reject. Safety is the default.
MCP Server: A FastAPI server exposing 8 Model Context Protocol tools, making the entire agent system queryable and controllable by any external AI client.
Alibaba Cloud ECS: Native ECS client for cloud-layer remediation when Kubernetes-layer fixes aren't sufficient.
React Dashboard: Real-time monitoring UI showing incident cards, agent pipeline status, approval flows, and cost reports on port 3000.
The math on incident coverage:
Auto-resolve rate ≈ P(confidence > 0.75) × P(risk = low or medium) ≈ 0.80
For 80% of incidents, no human is involved. For the remaining 20%, a human gets a clean Qwen-Turbo summary (not raw logs) and a single approve/reject button.
How We Built It
Model Selection and Architecture Rationale
Three Qwen models, three distinct jobs:
| Agent | Model | Why This Model |
|---|---|---|
| Analyzer | qwen-max | Highest reasoning capability for nuanced RCA; chain-of-thought output is readable by senior engineers |
| Planner | text-embedding-v3 | State-of-the-art semantic retrieval; runbook matching generalizes across natural language variation |
| Escalation | qwen-turbo | Speed + cost - summaries need to be fast and concise, not deeply reasoned |
This isn't three calls to the same model with different prompts. It's three models selected for their specific cognitive load profile. That distinction matters for both performance and cost.
The Analyzer Prompt Engineering
The Qwen-Max prompt is the system's most critical component. Getting structured, reliable JSON from an LLM in a production setting requires careful engineering:
system_prompt = """You are an expert Kubernetes SRE with 10+ years experience.
Analyze the incident and return ONLY valid JSON with these exact fields:
{
"root_cause": "specific technical explanation (2-3 sentences)",
"confidence": 0.0-1.0,
"action_type": "rollback|scale|patch_resources|policy_exception|cost_scale_down|manual_review",
"risk_level": "low|medium|high|critical",
"auto_remediate": true|false,
"reasoning": "step-by-step chain of thought"
}
Rules:
- auto_remediate = true ONLY if confidence > 0.75 AND risk_level in [low, medium]
- critical risk_level always sets auto_remediate = false
- Do not hallucinate resource names or metrics not present in the alert context
- Be specific. "Pod is crashing" is not a root cause."""
The auto_remediate logic is enforced at the prompt level and validated in code. Belt and suspenders.
RAG Pipeline With Qwen-Embedding
The runbook retrieval uses cosine similarity over pre-computed embeddings:
$$\text{similarity}(q, r_i) = \frac{q \cdot r_i}{|q| \cdot |r_i|}$$
Where $q$ is the embedding of the Qwen-Max RCA + reasoning text, and $r_i$ is the pre-computed embedding of runbook $i$.
# At startup: index all runbooks
for runbook in runbooks:
runbook.embedding = qwen_embed(runbook.content)
# At query time: embed the RCA and retrieve
query_text = f"{rca.root_cause} {rca.reasoning}"
query_embedding = qwen_embed(query_text)
best_runbook = max(runbooks, key=lambda r: cosine_sim(query_embedding, r.embedding))
Five runbooks indexed: crashloop-rollback, oomkill-increase-memory, deployment-failure-sync, cost-spike-scale-down, kyverno-policy-exception. The semantic search means "pod restarting due to memory pressure" and "Java OOMKill on payment-service" both retrieve the correct runbook without any keyword matching or rule maintenance.
Circuit Breaker Implementation
The Executor's circuit breaker is the safety mechanism I'm most proud of:
class CircuitBreaker:
"""
States: CLOSED -> (3 failures) -> OPEN -> (300s) -> HALF_OPEN -> (success) -> CLOSED
-> (failure) -> OPEN
"""
def __init__(self, max_failures=3, reset_seconds=300):
self.state = "CLOSED"
self.failure_count = 0
self.last_failure_time = None
When kubectl commands fail consecutively (due to RBAC misconfiguration, network partition, or anything else) the breaker opens. No more execution attempts. The system escalates and waits. This prevents the most dangerous failure mode of autonomous operations: an agent hammering a broken cluster with repeated failing commands.
Orchestrator and Deduplication
The Orchestrator deduplicates by (alert_type, namespace, resource_name) tuple. The same incident cannot spawn two simultaneous remediation pipelines. This is essential at the 30-second polling interval - without deduplication, a single CrashLoopBackOff would generate dozens of duplicate pipelines before the first fix completes.
MCP Server - Eight Tools for External AI Clients
tools = [
"get_pod_status", # Current pod phase, restart count, conditions
"get_pod_logs", # Last N lines of container logs
"get_deployment_status", # Replica count, rollout status, conditions
"execute_rollback", # ArgoCD history rollback to revision N
"patch_deployment_resources", # Update memory/CPU limits
"get_cost_report", # OpenCost namespace spend for N days
"create_policy_exception", # Kyverno scoped exception
"scale_workload", # Set replica count
]
Any MCP-compatible AI client (Claude, a custom agent, anything) can query and control the system through these tools. NeuroScale Autopilot becomes composable infrastructure.
Tech Stack
- Language: Python 3.11
- AI: Qwen-Max, Qwen-Turbo, text-embedding-v3 via DashScope
- API Server: FastAPI + Uvicorn
- Frontend: React 18 + Vite (port 3000)
- Kubernetes: kubernetes Python client + watch API
- Cloud: Alibaba Cloud ECS via aliyunsdkcore
- CI/CD: GitHub Actions
- Containerization: Docker + Docker Compose
- Deployment manifests: Kubernetes YAML for ACK
Challenges We Ran Into
1. Reliable structured output from Qwen-Max
Getting an LLM to return consistent, valid JSON in a production pipeline (not just in demos) required significant prompt hardening. Early versions would occasionally return markdown-wrapped JSON, or omit fields under unusual alert conditions. The solution was a combination of strict prompt rules, a JSON schema validator on the output, and a fallback that routes malformed responses to manual review rather than crashing the pipeline.
2. Runbook retrieval precision at the edges
The embedding retrieval works excellently on clear incidents. The hard cases are ambiguous ones: a pod that's both OOMKilling and in CrashLoopBackOff. Which runbook wins? The answer is whichever the Qwen-Max RCA emphasizes most strongly, since the query is the full reasoning text, not just the alert type. That emergent behavior took time to observe and trust.
3. The circuit breaker state machine
The CLOSED -> OPEN -> HALF_OPEN transition logic sounds simple until you implement it in an async Python environment with concurrent alerts. Race conditions on failure_count required careful locking. The HALF_OPEN state ("try one action, if it succeeds reset, if it fails go back to OPEN") is the subtle part that most circuit breaker tutorials skip.
4. Human approval timing
300 seconds (5 minutes) feels like a long time in a demo and a short time at 2 AM. Getting the auto-reject behavior right (log it, escalate it, move on, never block the pipeline) required rethinking how the Escalation Agent interacts with the Orchestrator. The approval flow is asynchronous; the pipeline doesn't stall waiting for a human. It continues processing other alerts.
5. Safe execution boundaries
Defining what the Executor is not allowed to do was harder than defining what it can do. The whitelist approach (four allowed actions, everything else routes to manual review) was the right call, but it required careful thought about what "everything else" might look like from a hallucinated or malformed action type.
Accomplishments That We're Proud Of
17/17 tests passing - Full smoke and integration test coverage across all five agents, the MCP server, and the Alibaba Cloud ECS client. Every agent, every tool, every integration path tested.
Three Qwen models, one coherent system - Qwen-Max, Qwen-Turbo, and text-embedding-v3 aren't just three API calls. They're three specialized cognitive tools, each doing the job it's best suited for, composing into a pipeline where the output quality is greater than the sum of its parts.
The circuit breaker actually caught a real failure - During development, a misconfigured kubectl context caused every execution attempt to fail. The circuit breaker opened after three attempts, escalated to the human review queue, and stopped. No runaway execution loop. That's the moment I knew the safety architecture was right.
Qwen-Turbo summaries that read like a senior SRE wrote them - The escalation messages aren't LLM word salad. They're tight, specific, actionable. Testing across fifteen incident scenarios produced output I would actually trust to wake a human up with.
MCP server composability - NeuroScale Autopilot isn't just a standalone agent. It's infrastructure that any AI client can plug into. Building the MCP layer means the system's value compounds as the AI tooling ecosystem evolves.
React dashboard built and functional - Full incident card UI with approval flow, agent status panels, cost reports. Not a mockup. A working interface.
What We Learned
Separation of concerns is the most important architectural decision in multi-agent systems. The temptation is to build one smart agent that does everything. That's wrong. A Detector that also tries to analyze is worse at both jobs. Specialized agents with clean interfaces compose better, fail more gracefully, and are dramatically easier to debug.
LLM output reliability requires layers, not prayers. Prompt engineering alone is not enough for production. You need: schema validation, fallback routing, anomaly detection on the confidence scores, and explicit rules that override the LLM when safety thresholds aren't met. Trust the model's reasoning; verify its output.
The right question for autonomous systems is not "what can it do?" but "what is it not allowed to do?" The Executor whitelist was the most important design decision in the project. Bounding the action space is what makes autonomous execution safe enough to actually deploy.
Qwen's embedding model generalizes remarkably well to technical domains. I expected to need domain-specific fine-tuning for DevOps runbook retrieval. text-embedding-v3 made that unnecessary - the semantic understanding of Kubernetes incident language out of the box was accurate enough for production-quality retrieval.
Human-in-the-loop design is a feature, not a compromise. The 300-second approval window with auto-reject isn't a limitation, it's the design. An autonomous system that escalates gracefully is more trustworthy than one that claims it can handle everything. The 80/20 split (auto-resolve vs. escalate) is the right operating point.
What's Next for NeuroScale Autopilot
Real Prometheus integration - Current version uses a structured mock metrics provider. A production PromQL client is the immediate next step, connecting to real cluster telemetry.
Runbook auto-generation - After each resolved incident, ask Qwen-Max to generate a new runbook from the resolution. The RAG index grows as the system learns. Knowledge compounds automatically.
Multi-cluster federation - The architecture is single-cluster today. Federating across dev/staging/prod environments with per-cluster safety profiles is architecturally straightforward and operationally essential.
Custom Qwen fine-tune on SRE incident data - qwen-max is excellent out of the box. Fine-tuned on real incident post-mortems, the RCA quality would be exceptional. This is the long-term investment that turns a good system into an industry-defining one.
Grafana plugin - Surface agent status, incident history, and remediation outcomes as native Grafana panels. Meet SRE teams where they already live.
Policy-as-code feedback loop - When the Executor creates a Kyverno exception, feed that exception back to the policy author as a signal. Close the loop between automated remediation and policy evolution.
The vision is a Kubernetes operations platform where the human role shifts from incident responder to incident reviewer. You stop fighting fires. You read summaries, approve edge cases, and improve the runbooks. The system handles the rest.
That's not science fiction. It's the next six months of this project.
Built for the Qwen Cloud Global AI Hackathon - Track 4: Autopilot Agent.
Sodiq Jimoh - Platform Engineer


Log in or sign up for Devpost to join the conversation.