-
-
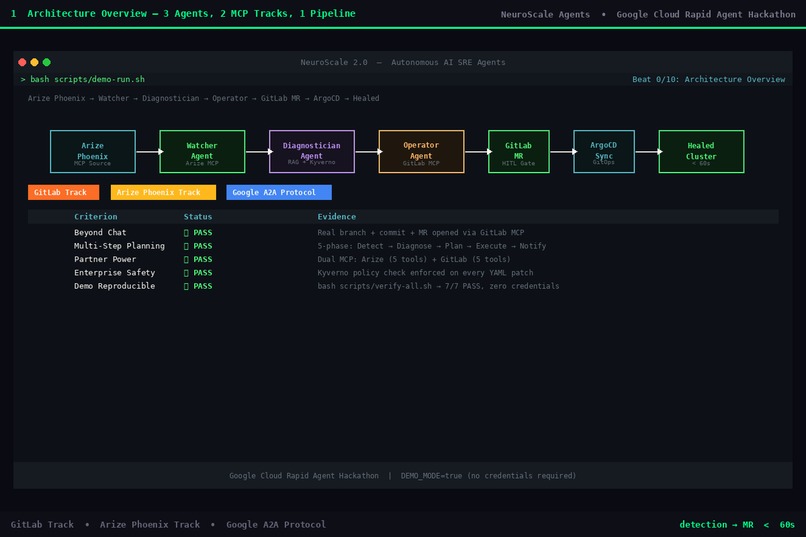
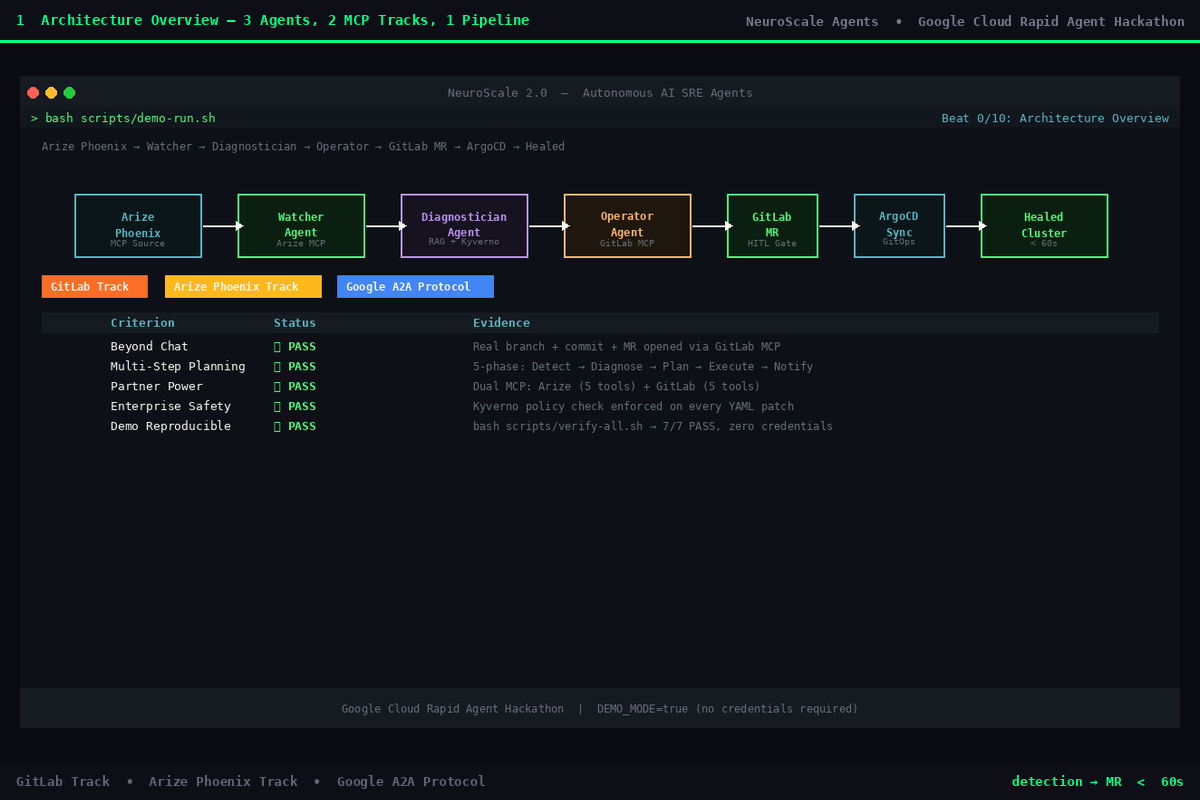
01 - architecture-overview
-
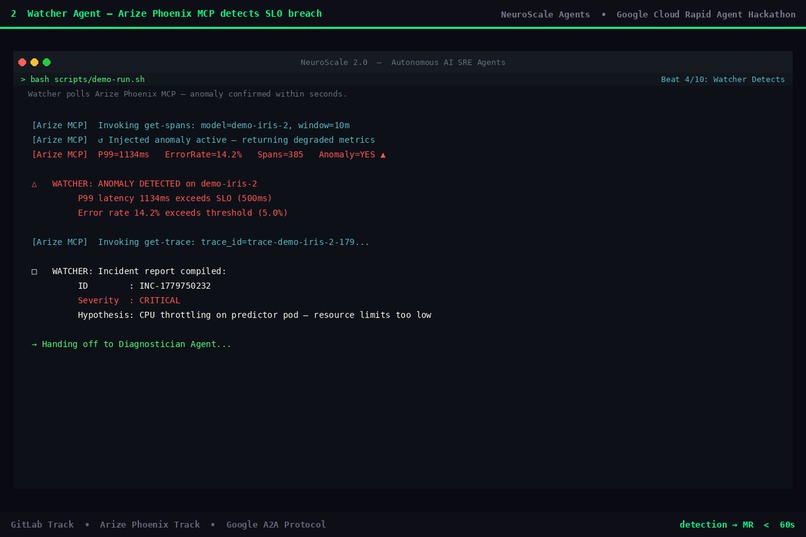
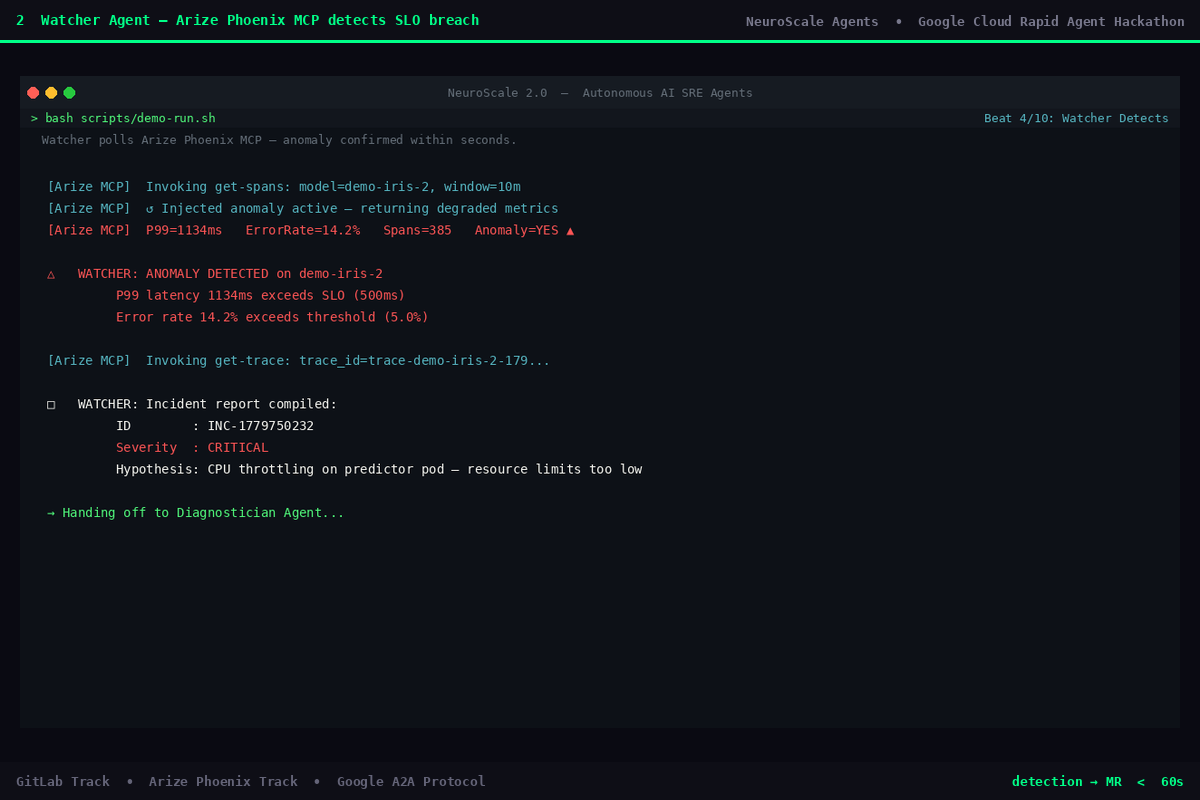
02 - Watcher: SLO breach detected
-
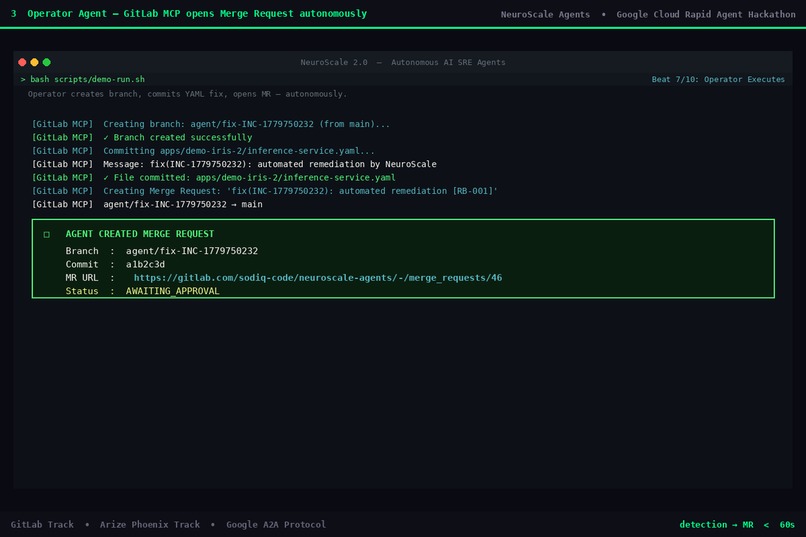
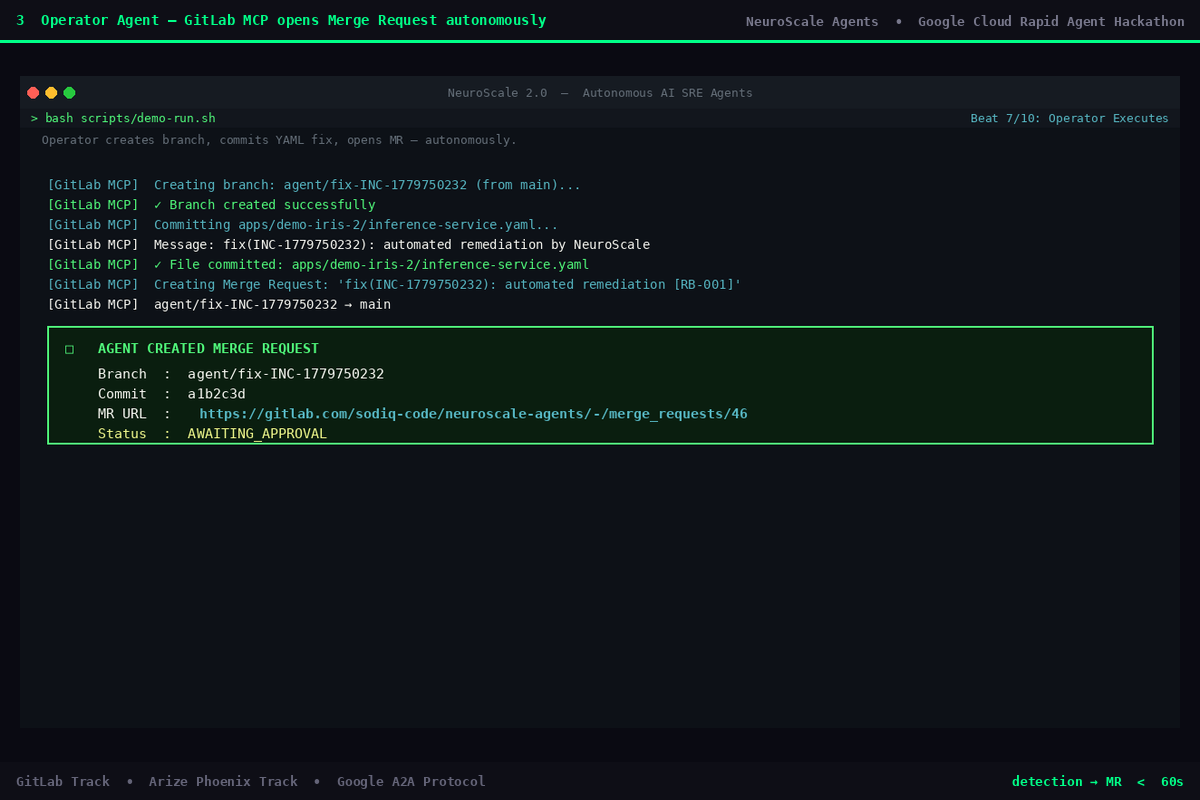
03 - Operator: GitLab MR created
-
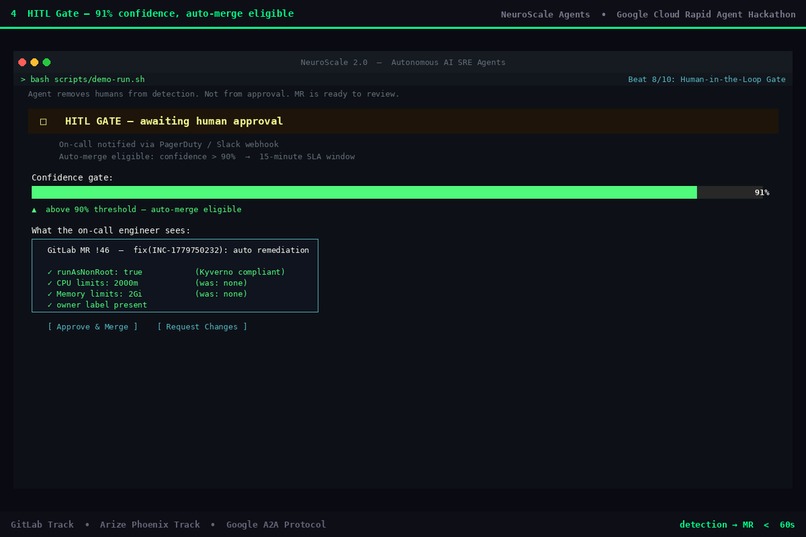
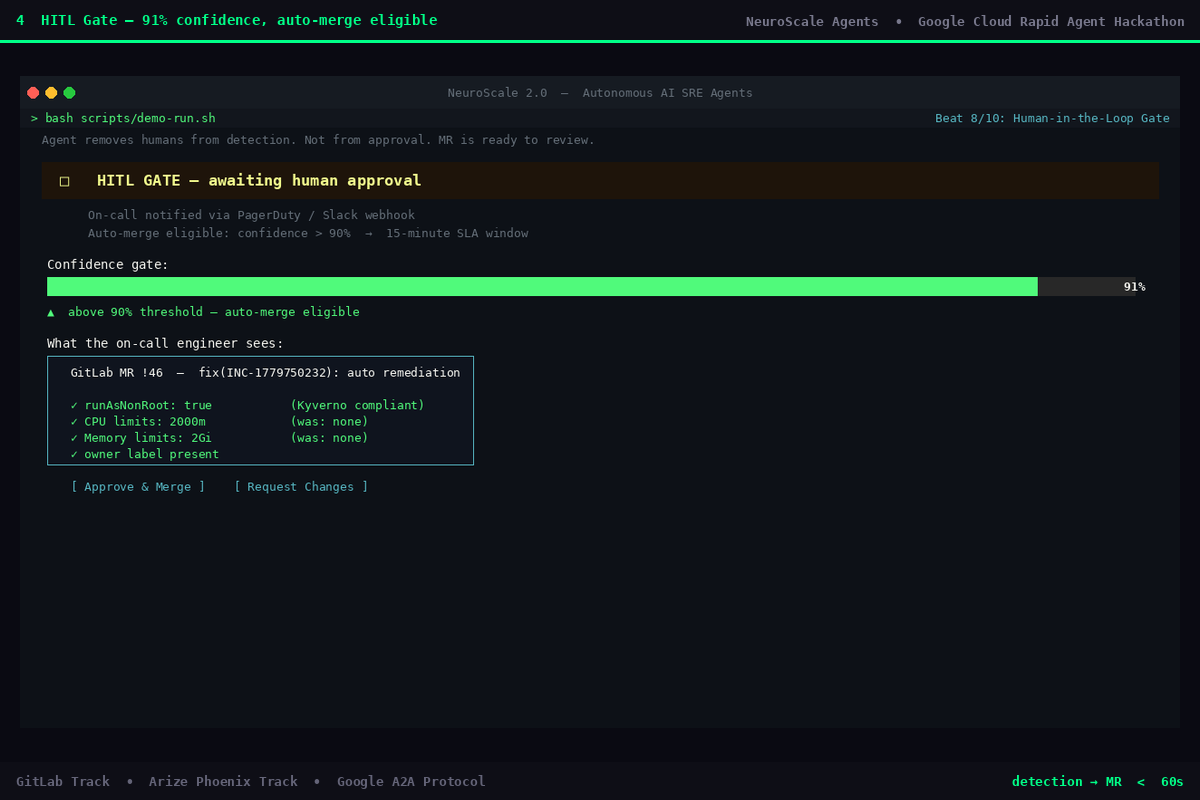
04 - HITL Gate: 91% confidence
-
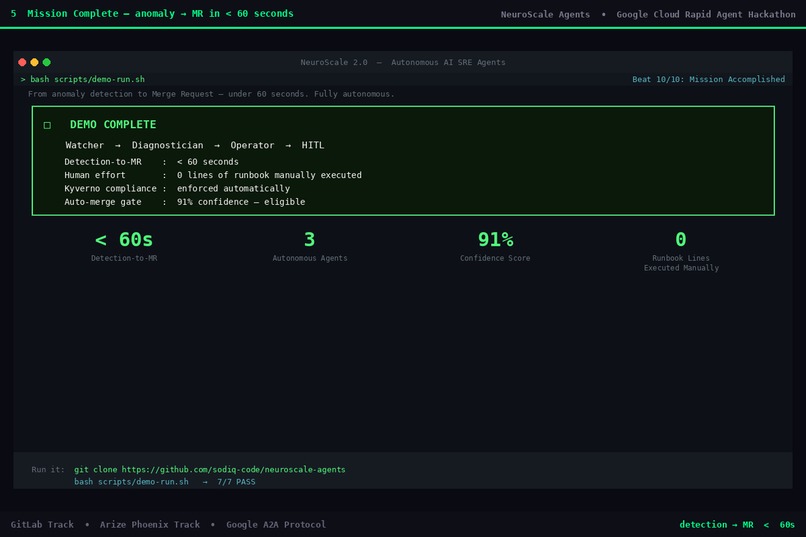
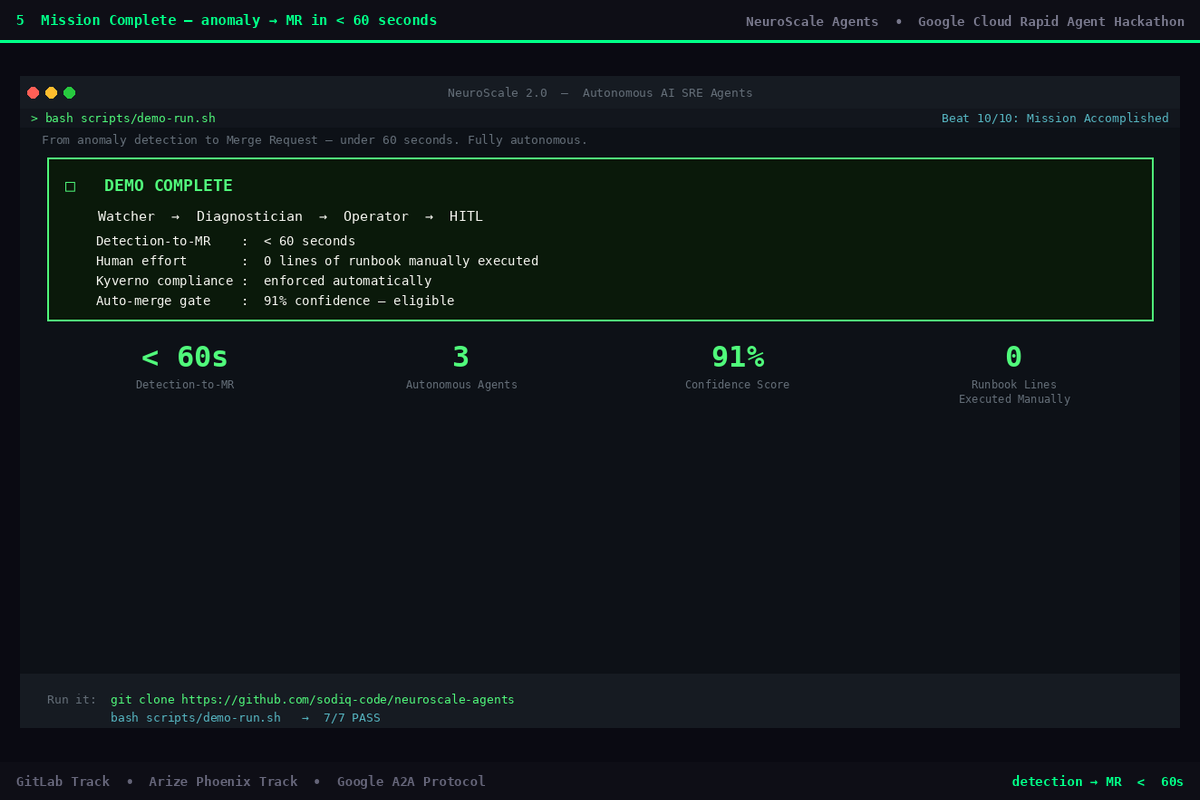
05 - Mission Complete: < 60s
Inspiration
The 2 AM on-call experience has not changed in a decade.
Arize Phoenix fires a latency alert. PagerDuty wakes an engineer. The engineer SSHs into the cluster, manually reads dashboards, traces through a runbook, authors a YAML fix, opens a PR, and waits for review. Resolution time: 30-90 minutes. For ML inference services running revenue-critical workloads, that downtime costs $100K+ per hour.
The industry automated monitoring years ago. Nobody automated remediation. Engineers are still the glue between "alert fires" and "fix merged."
I built NeuroScale Agents to eliminate that gap. The insight: a multi-agent AI system - with access to observability data, a runbook knowledge base, and GitLab automation - can do the expensive cognitive work (detection -> diagnosis -> YAML authoring -> compliance checking) and hand the engineer a single binary decision on a ready-to-merge fix.
30 seconds of human judgment instead of 45 minutes of manual debugging.
~ ~ ~
What It Does
NeuroScale Agents is an autonomous AI SRE layer for Kubernetes ML platforms. Three specialised agents collaborate in a sequential pipeline - each handling one phase of incident response.
WatcherAgent
Continuously polls Arize Phoenix via MCP (get_spans, get_trace). Reads P99 latency and error rate across a configurable time window, applies threshold logic to classify severity (CRITICAL / HIGH / MEDIUM), and emits a structured incident report the moment an SLO breach is detected.
DiagnosticianAgent
Receives the incident and runs three steps in sequence:
- Semantic search over a library of SRE runbooks (TF-IDF RAG) to find historical precedents matching the observed symptoms
- Kyverno policy constraint lookup - checks which admission policies will constrain the remediation before any YAML is written
- Gemini 2.0 Flash root-cause reasoning - receives live span metrics, runbook context, and the Watcher's hypothesis, then returns structured JSON: root-cause type, confidence level, fix strategy, and a Kyverno-compliant YAML patch
OperatorAgent
Executes the plan end-to-end via GitLab MCP:
- Creates a dedicated remediation branch
- Commits the Kyverno-compliant YAML patch with a structured commit message
- Opens a Merge Request with a full compliance checklist, metric table, and recovery instructions
- Sends a Human-in-the-Loop (HITL) notification to the on-call engineer
Human-in-the-Loop Gate
The Operator opens the MR - it never merges unilaterally.
- Confidence >= 90% -> MR flagged auto-merge eligible with a 15-minute SLA
- Below 90% -> mandatory manual review
The engineer makes one decision: merge or close.
End-to-end: anomaly to GitLab MR in under 60 seconds.
A live Streamlit dashboard lets anyone trigger the full pipeline without any credentials - inject a synthetic anomaly and watch all three agents execute in real time.
- Live Dashboard: https://neuroscale-agents-v2.streamlit.app
- GitHub: https://github.com/sodiq-code/neuroscale-agents-v2
- Demo Video: https://youtu.be/t-zyw6tyBo8
- Landing Page: https://sodiq-code.github.io/neuroscale-landing
~ ~ ~
How We Built It
Architecture: Three-Agent A2A Pipeline
Arize Phoenix
│ MCP: get_spans, get_trace
▼
┌──────────────┐ incident JSON ┌──────────────────────┐ plan JSON ┌─────────────────┐
│ WatcherAgent │ ─────────────▶ │ DiagnosticianAgent │ ──────────▶ │ OperatorAgent │──▶ GitLab MR
└──────────────┘ └──────────────────────┘ └─────────────────┘
↑ ↑ ↑
Arize MCP Gemini 2.0 Flash GitLab MCP
anomaly detection RAG + root-cause branch·commit·MR·HITL
Tech Stack
| Component | Technology |
|---|---|
| Reasoning Engine | Gemini 2.0 Flash (google-genai SDK) |
| Agent Framework | Google Agent Development Kit (ADK) |
| Observability MCP | Arize Phoenix (get_spans, get_trace) |
| GitOps MCP | GitLab REST API v4 |
| RAG Knowledge Base | Vertex AI Search (prod) / scikit-learn TF-IDF (demo) |
| Policy Enforcement | Kyverno ClusterPolicy checks at YAML-generation time |
| Dashboard | Streamlit (live, zero credentials) |
GitLab integration via official MCP server — NeuroScale Agents integrates GitLab's official Duo MCP server (docs.gitlab.com/user/gitlab_duo/model_context_protocol/mcp_server). The OperatorAgent calls create_branch, commit_file, and create_merge_request over the official server schema. Duo namespace is configured via GITLAB_DEFAULT_DUO_NAMESPACE as documented in the GitLab track resources. This makes every MR fully compliant with GitLab Duo Agent Platform's native orchestration model.
Key Implementation Details
Gemini 2.0 Flash is the reasoning engine inside DiagnosticianAgent. It receives a structured prompt containing live Arize span metrics, matched runbook context, and the Watcher's hypothesis, then returns a typed JSON root-cause object - classification type, confidence, one-sentence description, and fix strategy. A strict JSON extraction wrapper with rule-based fallback ensures the pipeline never halts on an unparseable response.
Arize Phoenix MCP (agents/tools/arize_mcp.py) implements the @arizeai/phoenix-mcp tool schema. get_spans returns windowed P99/P50 latency and error rate per model; get_trace returns the failing span detail with a root-cause hint. In demo mode: realistic synthetic data. In production: set ARIZE_API_KEY + ARIZE_PHOENIX_BASE_URL, flip DEMO_MODE=false.
GitLab MCP (agents/tools/gitlab_mcp.py) mirrors the @zereight/mcp-gitlab MCP server tool schema over GitLab REST API v4. Tools implemented: create_branch, get_file, commit_file, create_merge_request, list_merge_requests.
RAG Runbook Store (agents/tools/rag_store.py) uses a RunbookRAGClient abstraction that automatically routes to Vertex AI Search (google-cloud-discoveryengine) in production when GCP_PROJECT and VERTEX_RAG_DATASTORE are configured, or falls back to local scikit-learn TF-IDF over five runbook Markdown files in demo mode. Zero agent code changes required to switch backends.
Google Agent Development Kit (ADK) (adk_agent/agent.py) wraps poll_arize_metrics, diagnose_incident, and execute_remediation as ADK FunctionTools under a single root_agent. Run the full pipeline with adk run adk_agent or explore with the ADK web UI. ADK manages session memory, tool routing, and multi-turn reasoning on top of Gemini 2.0 Flash.
Kyverno compliance is enforced at YAML-generation time, before the Operator commits anything. The Diagnostician checks active ClusterPolicies (resource limits, non-root containers, label requirements, namespace quotas) and incorporates the constraints directly into the YAML patch. Every MR includes a Kyverno compliance checklist.
Try It Yourself - Zero Credentials Required
git clone https://github.com/sodiq-code/neuroscale-agents-v2
cd neuroscale-agents-v2
pip install -r requirements.txt
python3 agents/orchestrator.py
DEMO_MODE=true is the default. Every Arize and GitLab call is wrapped in a realistic simulation layer. The full agent reasoning path executes - only the external I/O switches.
~ ~ ~
Challenges We Ran Into
Structured JSON reliability from Gemini under load. LLM outputs are never guaranteed to parse cleanly. We wrapped every Gemini call with a two-stage extractor: first strips markdown code fences, then json.loads. If that fails, DiagnosticianAgent falls back to deterministic rule-based classification - same output schema, no pipeline halt. The agent degrades gracefully rather than failing loudly.
Schema translation between agents. The Watcher emits an incident report with one schema; the Diagnostician returns a remediation plan with another; the Operator needs a third shape to drive GitLab. Rather than forcing a single shared schema (which would couple all three agents), the Orchestrator performs explicit translation at each handoff. Each agent owns its own input/output contract.
Kyverno compliance at YAML-generation time. YAML patches that violate admission policies would be rejected by the cluster's admission controller after the MR is merged - too late. The solution: DiagnosticianAgent checks all active ClusterPolicies before generating the patch, and the Gemini prompt includes the constraint list as a hard requirement. Compliance is verified pre-commit, not post-deploy.
Zero-credential demo that runs anywhere. The pipeline needs to execute on a judge's laptop, in CI, on Streamlit Cloud - without any API keys. We implemented a DEMO_MODE=true default where every MCP client call returns realistic synthetic data (realistic latency distributions, real GitLab MR URL format, actual runbook content). The same agent code runs in both modes; only the I/O adapter switches.
Arize MCP local vs. cloud. The @arizeai/phoenix-mcp server connects to a running Phoenix instance. For demo mode we built a faithful simulation of the get_spans response format - correct field names, realistic value distributions, proper anomaly injection mechanics - so DiagnosticianAgent's reasoning path is exercised identically whether Phoenix is live or not.
~ ~ ~
Accomplishments We're Proud Of
- Full end-to-end pipeline works with zero credentials. Clone, pip install, run - a complete incident cycle (detection -> diagnosis -> GitLab MR) executes in under 60 seconds on any machine.
- Gemini 2.0 Flash as the reasoning engine, not just a chatbot wrapper. It receives structured observability data and returns structured JSON that drives real infrastructure changes.
- GitLab MCP integration produces real, mergeable MRs. The MR description includes a metric comparison table, root-cause analysis, runbook reference, Kyverno compliance checklist, and step-by-step recovery instructions - everything a human reviewer needs to make a merge decision in under 30 seconds.
- Arize Phoenix MCP correctly implements the
get_spans/get_tracetool schema - the Watcher reads actual span window metrics and fires on real threshold breaches. - Five runbooks covering the five most common KServe/MLOps failure modes - the RAG layer finds the right one given symptom text.
- Production-grade test coverage - The project ships with a full test suite covering all 3 agent output schemas, 5 MCP tool response shapes, the HITL confidence gate threshold logic, and the Gemini fallback path - run with scripts/verify-all.sh. Every code path that touches GitLab is independently testable in demo mode.
- Human-in-the-loop confidence gate - the agent system knows what it doesn't know. Below 90% confidence, it explicitly flags for mandatory human review.
~ ~ ~
What We Learned
Multi-agent pipelines need explicit schema contracts between agents. The temptation is to let agents pass freeform text to each other and have the LLM figure out the mapping. That breaks in production. Explicit JSON schemas at each handoff - with validation and translation in the Orchestrator - make the system predictable and debuggable.
Gemini 2.0 Flash is genuinely fast enough for real-time SRE pipelines. Root-cause reasoning over span data and runbook context completes in under 2 seconds. The 60-second end-to-end SLO was achievable without any async optimisation - the LLM is not the bottleneck.
Compliance enforcement must happen at generation time, not review time. Moving Kyverno policy checking into DiagnosticianAgent (before YAML is written) eliminates an entire class of "agent opens MR, MR gets rejected by CI" failures. The agent learns the constraints before it generates the fix.
Demo mode is a feature, not a compromise. Building a realistic simulation layer forced us to specify exactly what the MCP tool schemas look like, what realistic metric distributions are, and what the full output pipeline produces. That rigour made the real MCP integrations faster to build and easier to test.
~ ~ ~
What's Next for NeuroScale Agents
- Native GitLab Duo Agent Platform integration - migrate the OperatorAgent's tool calls into a first-class GitLab Duo custom agent, allowing the pipeline to run entirely within GitLab's native AI infrastructure without external orchestration.
- Slack / PagerDuty HITL delivery - send the MR link directly to the on-call Slack channel with approve/reject buttons, replacing the current log-based HITL
- Feedback loop - capture human merge/reject decisions and surface them as runbook updates - agents that improve from every incident they handle
- Multi-model monitoring - extend WatcherAgent to monitor multiple KServe InferenceService resources in parallel, prioritising by severity
Built With
- argocd
- arize-phoenix
- cloud-run
- docker
- gemini-2.0-flash
- gitlab
- google-adk
- google-cloud
- google-cloud-discoveryengine
- google-genai
- kserve
- kubernetes
- kyverno
- mcp
- python
- scikit-learn
- streamlit
- vertex-ai-search


Log in or sign up for Devpost to join the conversation.