Inspiration
Online platforms today struggle with moderating toxic content across multiple languages. Most existing systems are either English-centric or fail to understand cultural nuances, slang, and mixed-language (Hinglish, Spanglish, etc.) conversations. We wanted to build something that goes beyond basic filtering — a system that understands context, detects multiple toxicity types simultaneously, and works across languages.
What it does
NeuroRock is a multilingual, multi-label toxicity classification system that:
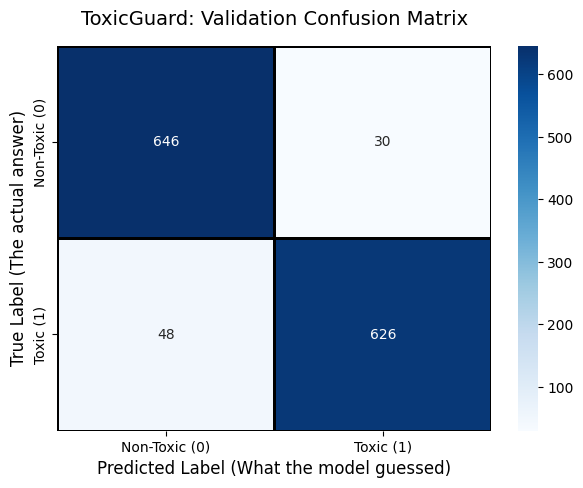
Detects multiple toxicity categories in a single comment (e.g., insult, threat, hate) Works across multiple languages, including mixed-language text Handles real-world noisy input such as slang, emojis, and code-mixed text Outputs probability scores for each toxicity type using Mean ROC-AUC optimization How we built it Data Processing Cleaned multilingual dataset, removed noise, and normalized text. Used language detection and token normalization for mixed inputs. Model Architecture Used transformer-based models like mBERT and XLM-R. Fine-tuned them for multi-label classification. Applied sigmoid activation since labels are not mutually exclusive. Training Strategy Used Binary Cross-Entropy loss. Evaluated using Mean ROC-AUC across all toxicity classes. Addressed class imbalance using weighted loss and focal loss. Pipeline Input text → Tokenization → Transformer → Dense layer → Multi-label output. Deployed as an API for real-time moderation use cases. Challenges we ran into Handling code-mixed language (e.g., Hindi + English in the same sentence) Class imbalance, especially for rare categories like threats Detecting sarcasm and indirect toxicity Loss of nuance in regional slang within multilingual embeddings Balancing model accuracy with inference speed Accomplishments that we're proud of Built a multilingual multi-label system instead of relying on translation-based approaches Achieved strong Mean ROC-AUC performance across toxicity categories Successfully handled noisy, real-world inputs Designed a scalable pipeline that can be extended to additional languages What we learned Multilingual NLP requires understanding context and cultural nuances, not just translation Transformer models are powerful, but fine-tuning strategy is critical Handling class imbalance significantly impacts performance Real-world data is messy, and preprocessing plays a major role in model success What's next for NeuroRock Improve detection of sarcasm and implicit toxicity using contextual reasoning models Expand support to more low-resource languages Optimize inference speed for large-scale deployment Integrate with social platforms for real-time moderation Explore explainable AI to make predictions more transparent

Log in or sign up for Devpost to join the conversation.