-

Introductory
-
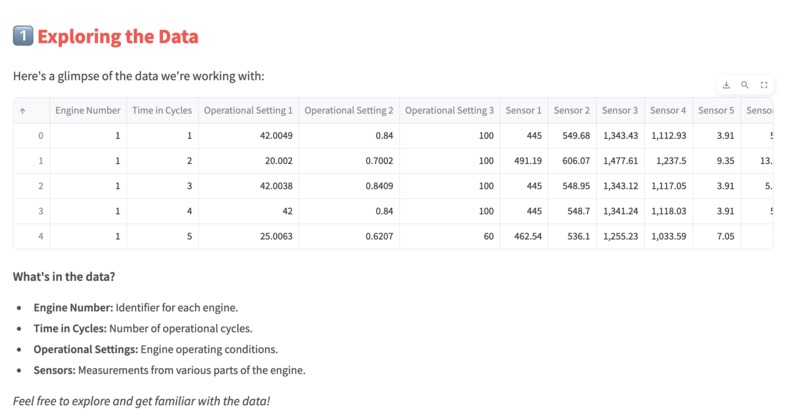
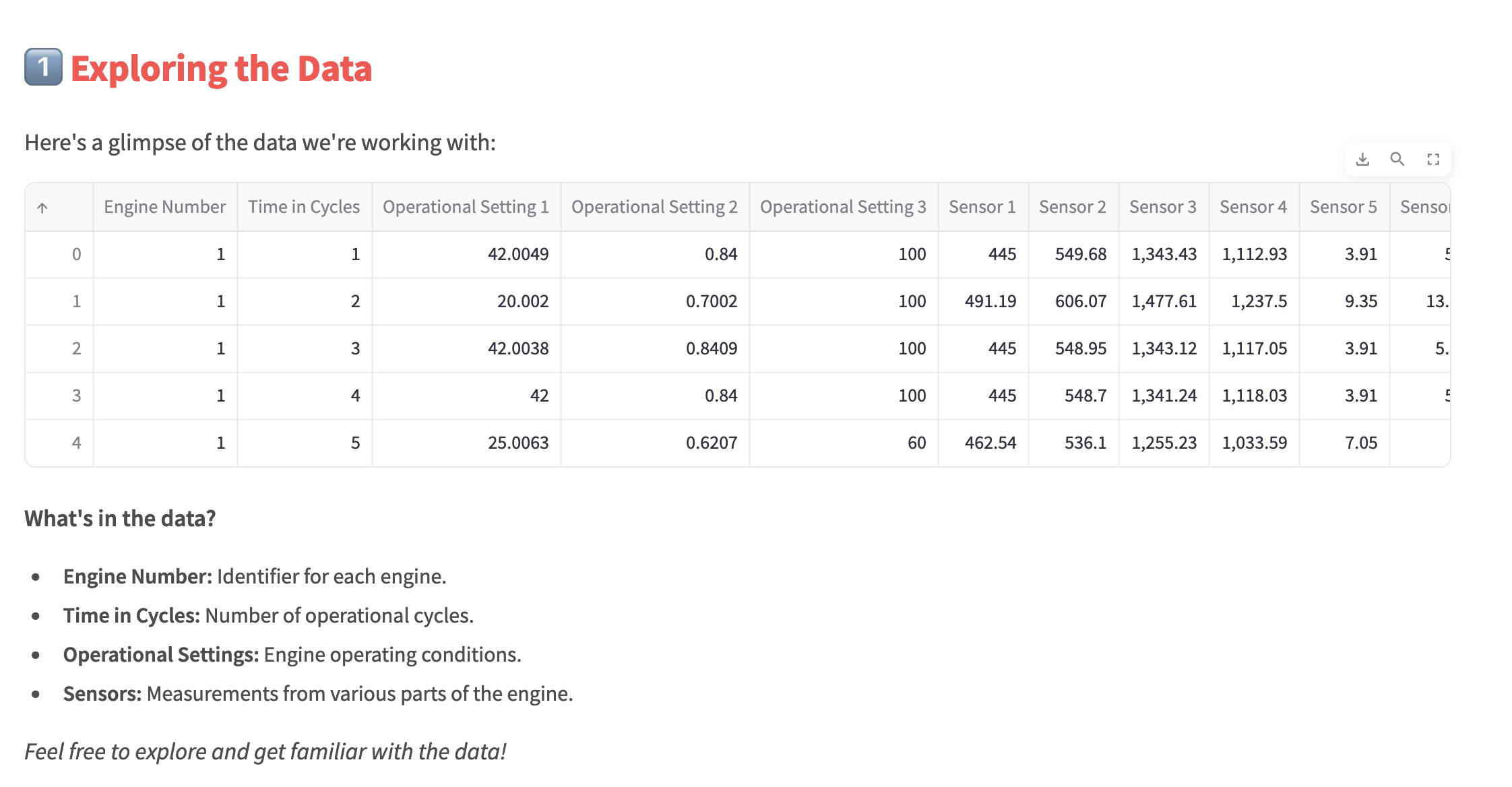
Educating user more about data we're using
-
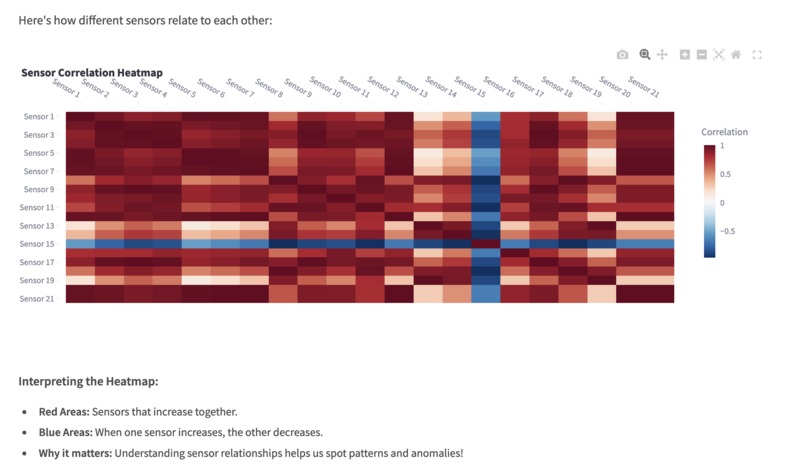
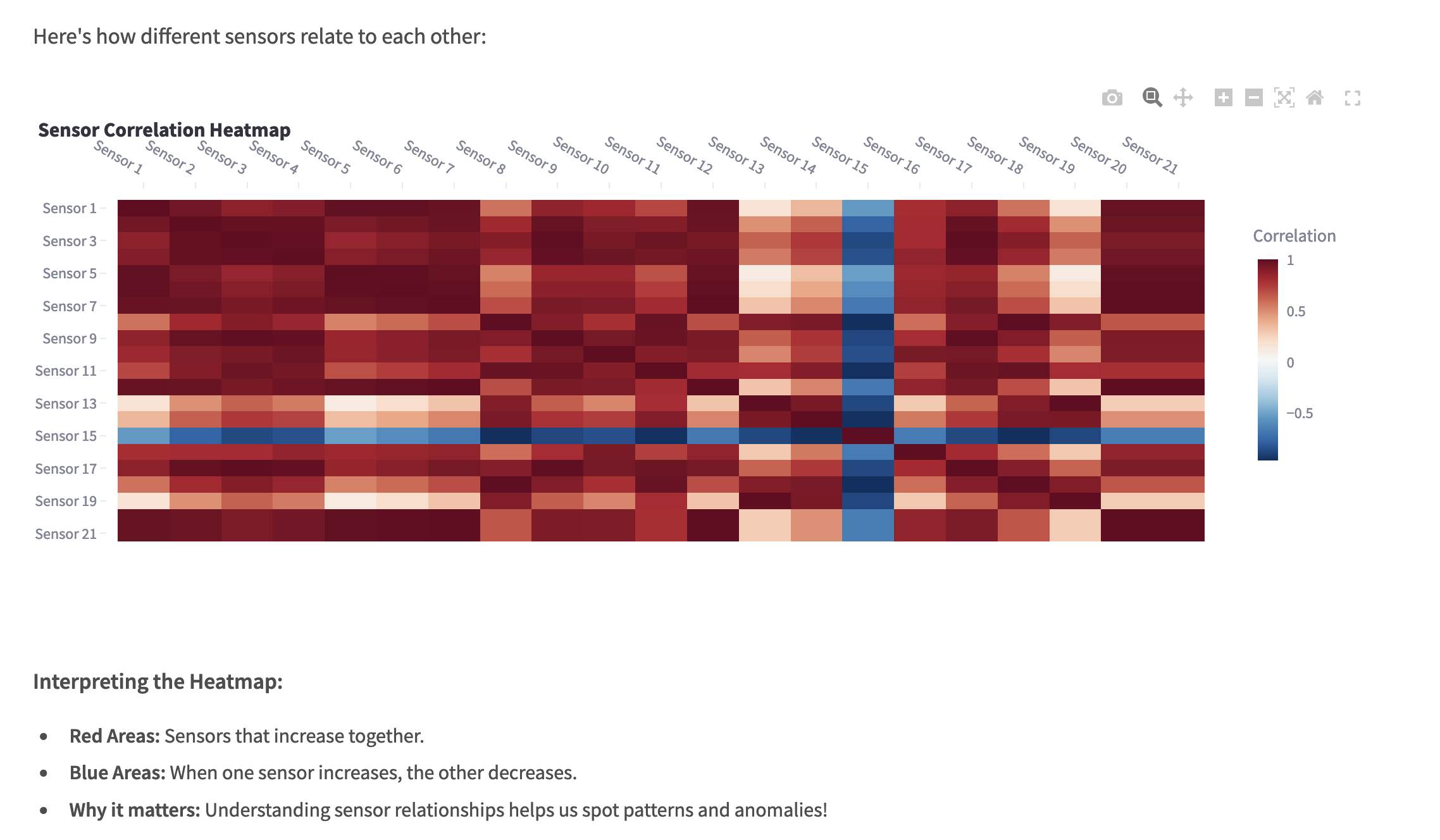
How sensor in our Jet engine co-relate
-

Real-time data processing updates
-
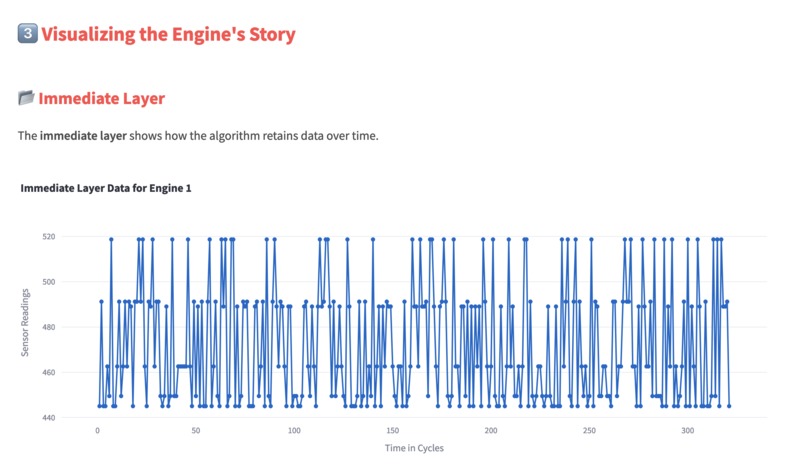
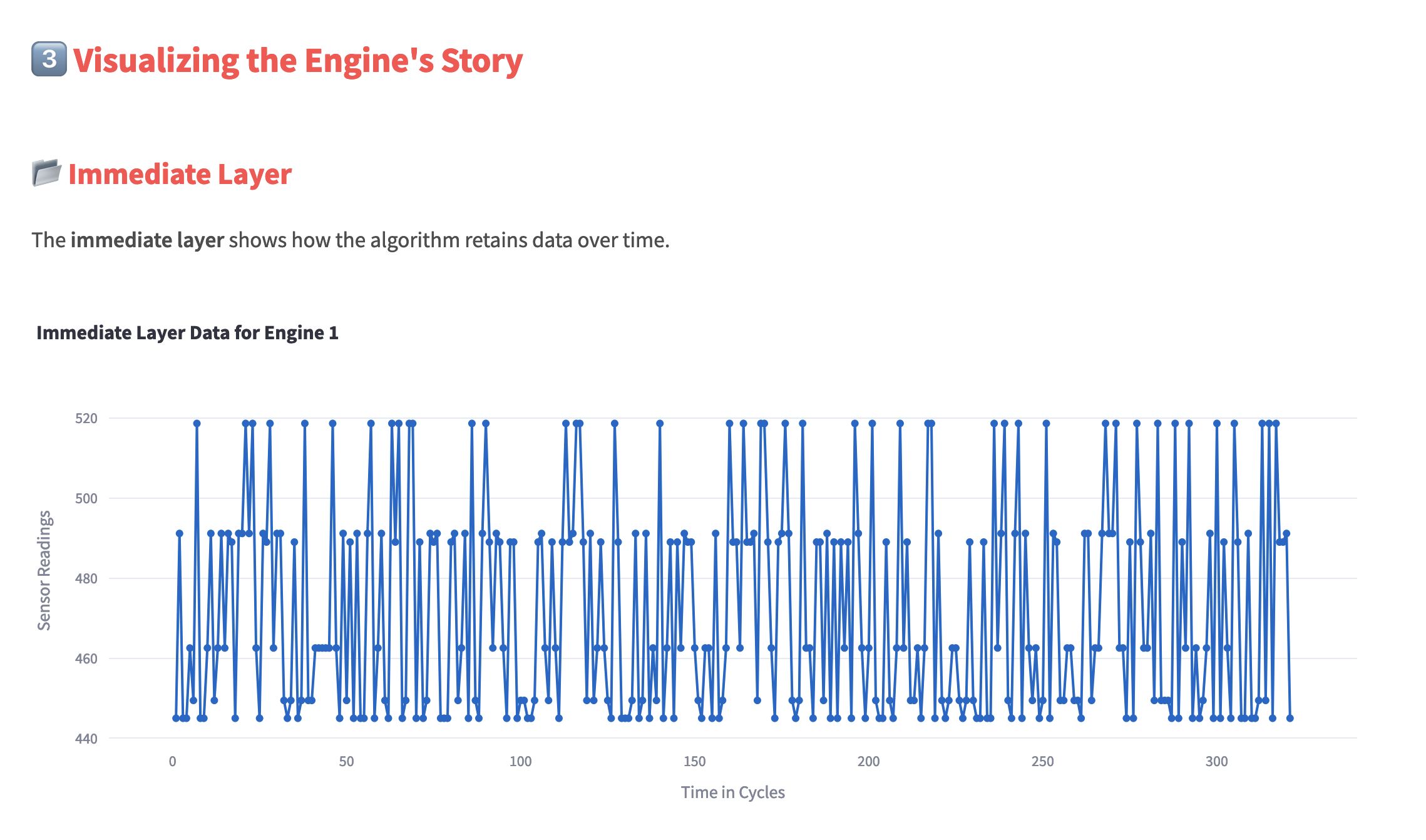
A visual of how immediate memory stores key points
-
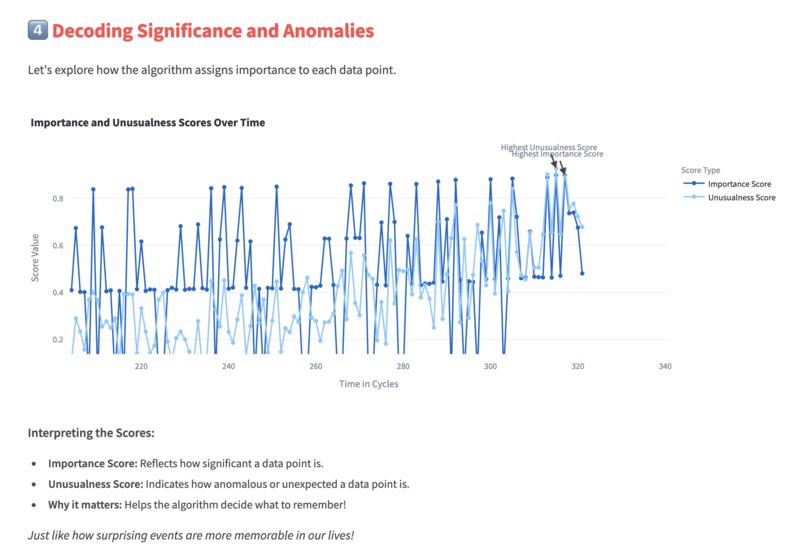
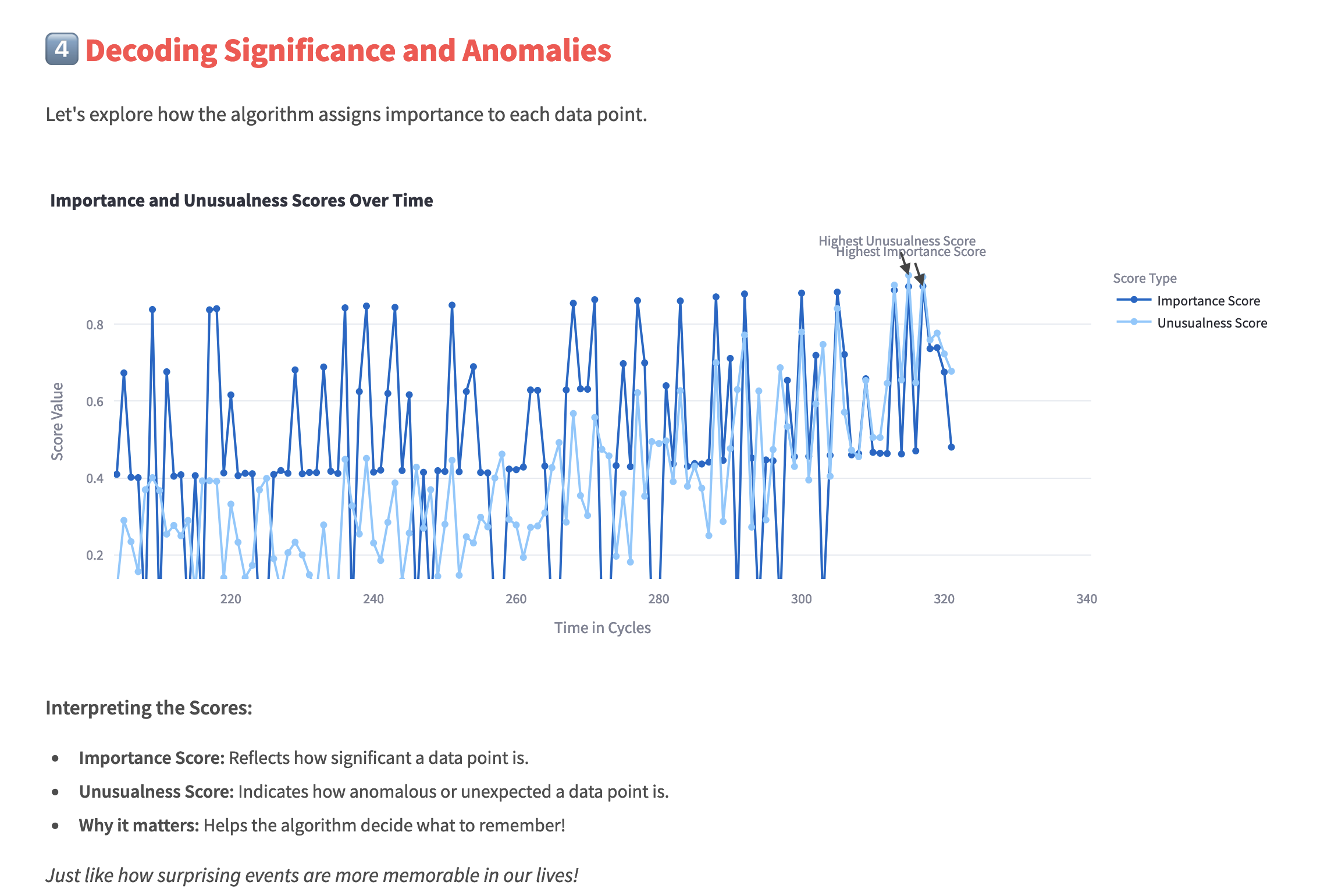
Converting anomlies
-
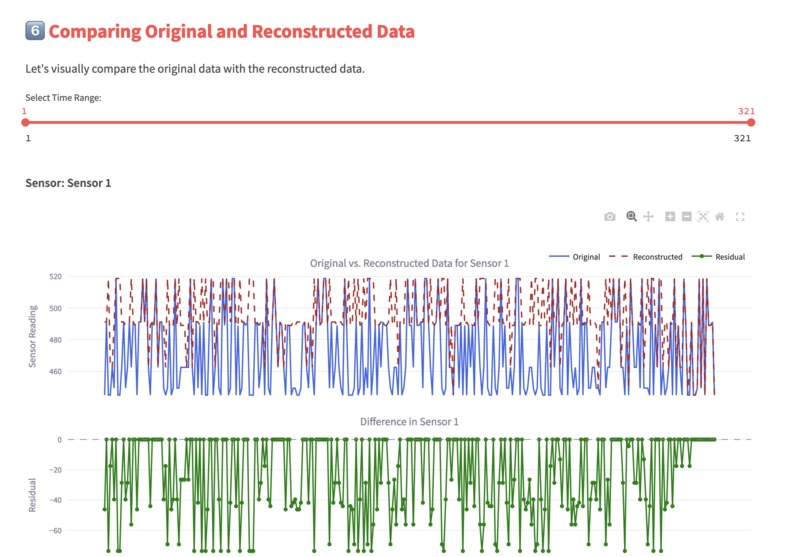
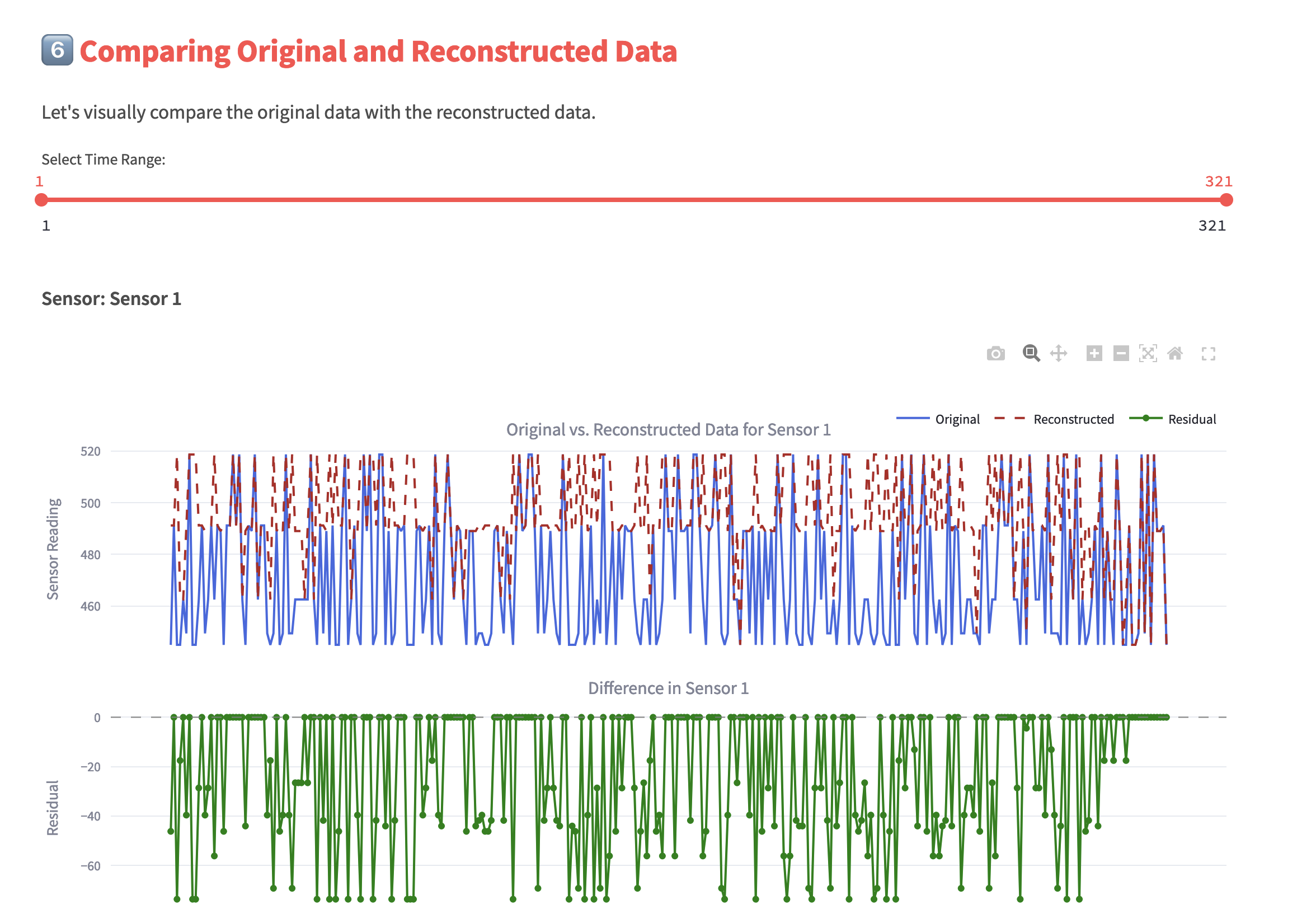
Allow our user to see difference between Original memories and reconstructed memories
-

A really educating and fun quiz to teach more about concept
-
FAQs and our footer



Inspiration
I've always been fascinated by how our world is drowning in data. What really caught my attention was how our brains handle information - they're incredibly efficient at keeping what matters and letting go of what doesn't. This got me thinking: what if we could create an algorithm that works like our brain to handle time-series data? That's how NTSC-BMP was born.
What it does
Think of NTSC-BMP as your brain's approach to handling data, but in algorithm form. It works in three layers, just like our memory:
A "right now" layer that keeps recent data in crystal clear detail A middle layer that's like your brain summarizing what happened last week A long-term layer that only holds onto the really important stuff
It's pretty clever - it can figure out what data is worth keeping in detail and what can be compressed, kind of like how you remember your first day at a new job but not what you had for lunch three weeks ago.
How I built it
We dove deep into neuroscience first, trying to understand how our brains actually process memories. Then we translated all that brain science into code using Python, with some help from NumPy and Pandas for the heavy lifting. We used scikit-learn's Isolation Forest to spot the important patterns - like your brain noticing something unusual. To make it user-friendly, we wrapped it all in a Streamlit app with some fancy Plotly visualizations. We wanted anyone to be able to play with it and see their data being compressed in real-time.
Challenges I ran into
The trickiest part? Finding that sweet spot for what counts as "important" data. Set the bar too high, and you might lose crucial information. Too low, and you're basically not compressing anything. I also had to wrestle with making the code run smoothly with huge datasets - it's like trying to fit an elephant through a keyhole while keeping it happy!
Accomplishments that I'm proud of
Our biggest win was successfully mimicking how the brain handles memories in code - that's no small feat! We built something that not only works but also helps people understand how intelligent data compression works. Plus, the compression results were actually pretty impressive across different types of data.
What I learned
This project was a crash course in neuromorphic computing - basically, making computers think more like brains. I levelled up our Python skills big time, especially with data processing and machine learning. But maybe the biggest lesson was about user experience - even the coolest algorithm is useless if people can't figure out how to use it.
What's next for Neuromorphic Time-Series Compression
I've got big plans! I'm looking to: Add some serious machine learning muscle to make it even smarter Get it working in real-world situations, like healthcare and finance Make it run smoothly on smaller devices Share it with the world as an open-source project
I'm excited to see where this goes and how it might help tackle real-world data challenges!

Log in or sign up for Devpost to join the conversation.