-
-
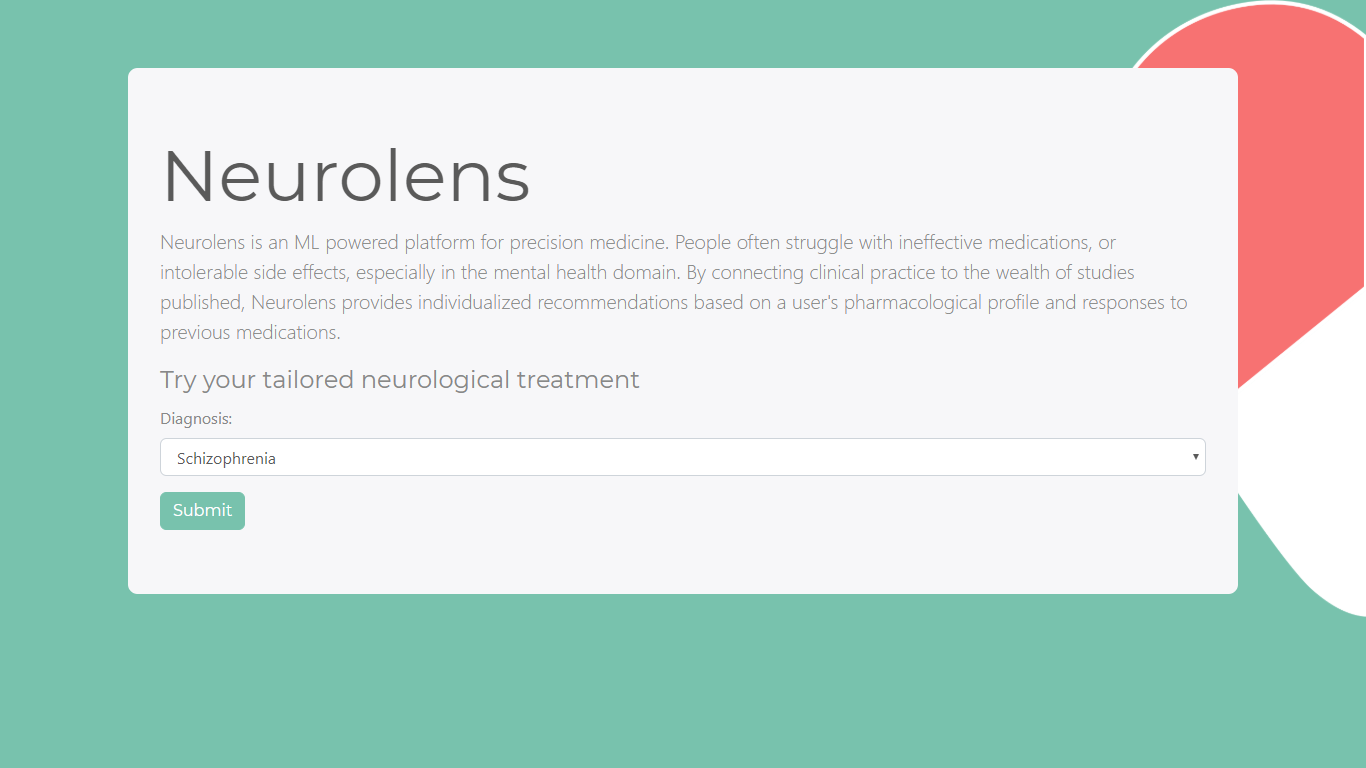
Landing page
-
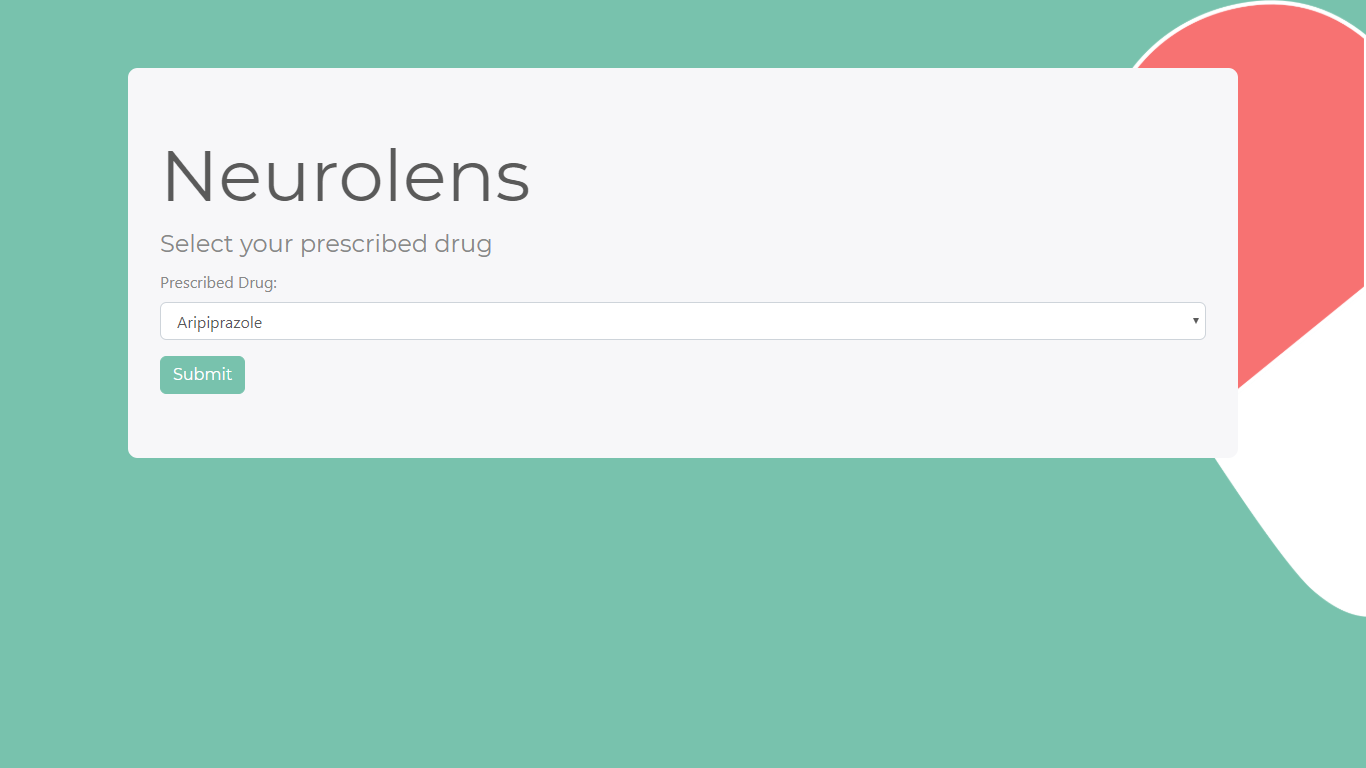
Select your prescribed drug
-
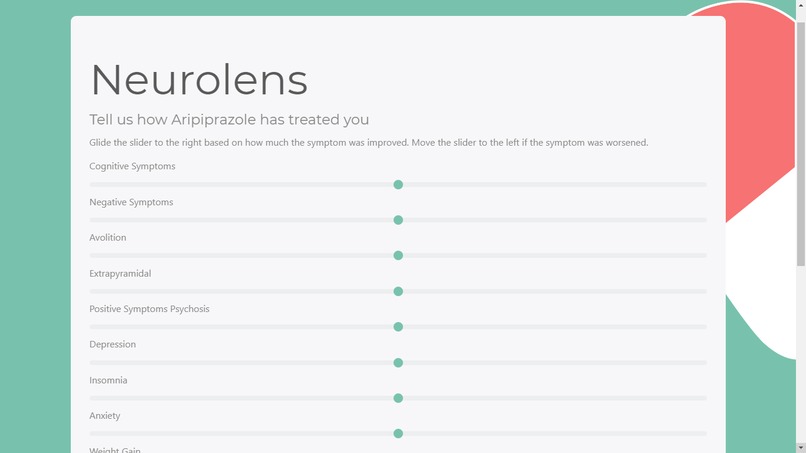
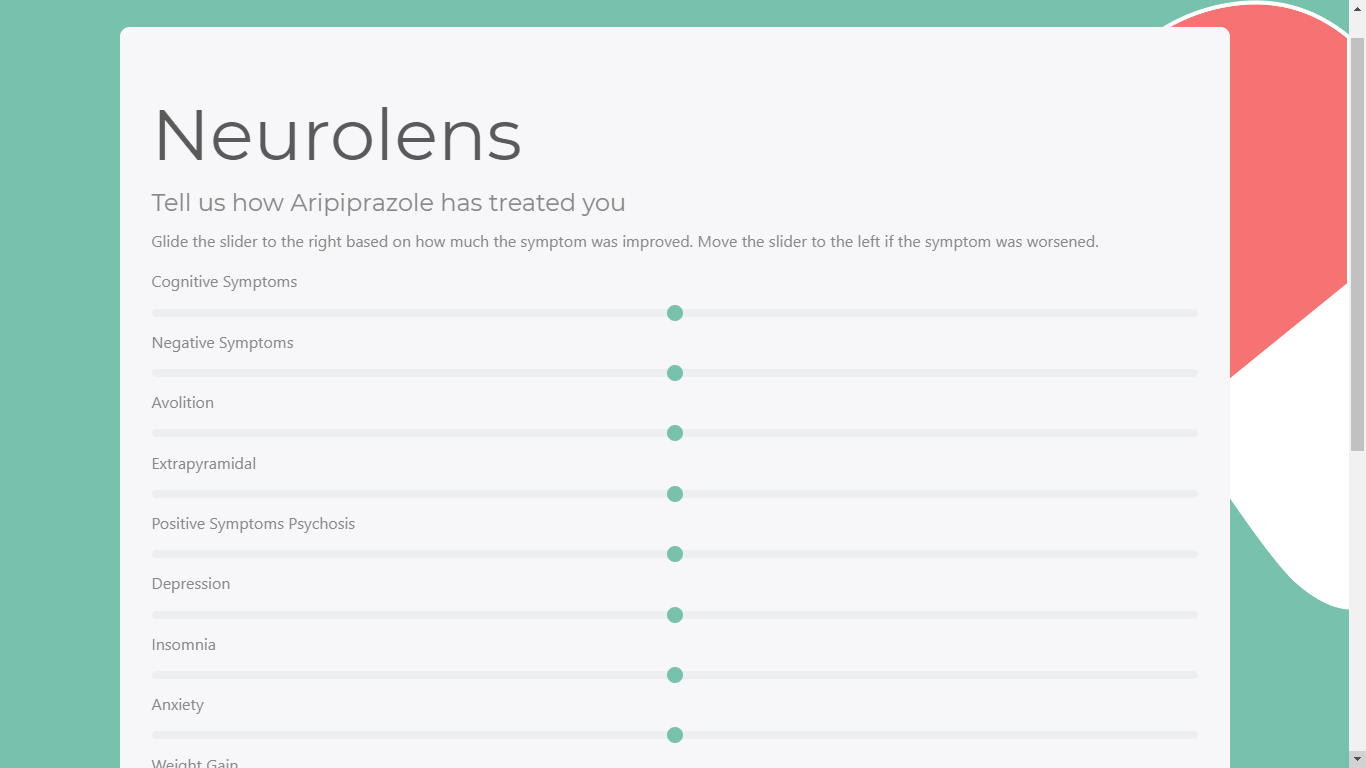
Tell us your responses to that drug to generate a pharmacological profile
-
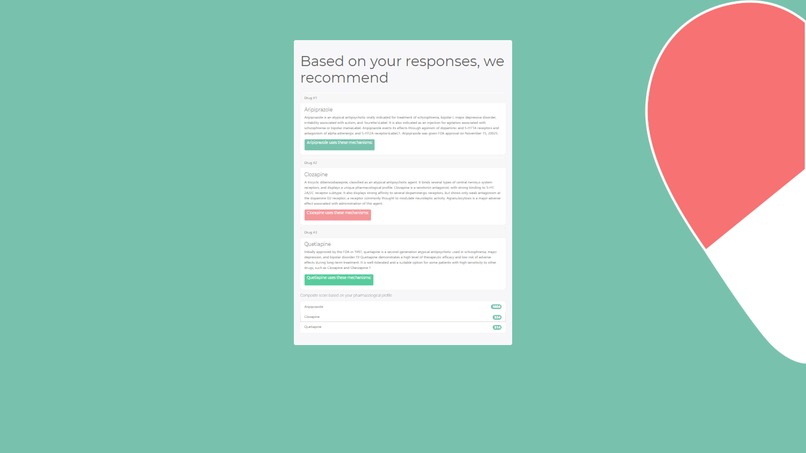
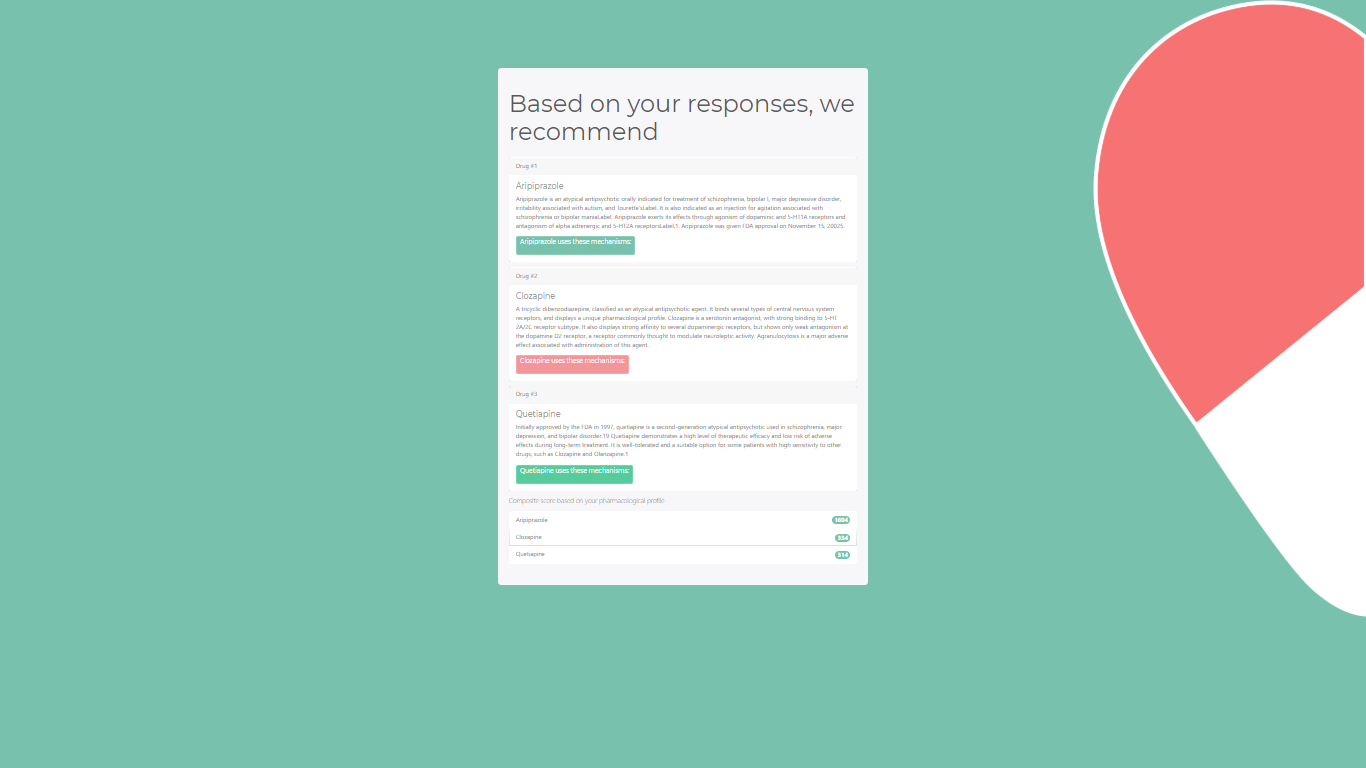
Zoomed out results page with collapsed mechanism lists for drugs
Inspiration
People often struggle with ineffective medications or intolerable side effects, especially in the mental health domain. By connecting clinical practice to the wealth of studies published, we can make better medication recommendations.
What it does
We use a patient’s medication history to identify ineffective and effective pharmacological profiles and search for new medications. After the patient inputs their previous medication and its effect on their symptoms, we calculate a composite score for each candidate medication based on the correspondence between its targets and the targets of the previous medication and the patient's response, as well as structural similarities on a molecular level between the previous and candidate medications. The top three medications are displayed along with links to the published articles supporting that decision so that the patient can discuss the results with a medical professional. This fully explainable process leverages the vast trove of freely available biomedical data while also providing evidence for its reasoning.
How we built it
We scraped over 35,000 articles from PubMed to build our dataset, which included associations between symptoms and targets, and targets and medications. By calculating a similarity score between articles and their related articles, we determined the strength of the correlation between symptoms and targets. We utilized sources of data, including DrugBank, to find the targets of each medication.
The chemical structure is used as an engineered feature with strong predictive power. Given its importance in drug design/discover as well as molecular target binding, it was a must-have in our model. We used the Tanimoto similarity metric to evaluate how close the graph structure of the drugs was in their descriptor space. We used this similarity to quantify a drug’s tendency to bind to the same targets as others.
Finally, we calculated a composite score that considers both structure similarities with the previous medication and the patient’s pharmacological profile to predict the efficacy of each candidate medication.
We use a Flask web app hosted on Google App Engine to make this service available to as many people as possible.
Challenges we ran into
Front-end and back-end development were particularly difficult to plan. Flask, as a web microframework, can be inflexible since it simply renders what will eventually be a static HTML document. We spent a lot of time working across the layers of static javascript files and Flask templates to create a fully responsive app. In the end, this paid off as the user interface can be extremely polished when you break with the framework to individually customize each component. However, in the early stages incompatibility between front-end and back-end led to complete do-overs of the user interface.
Accomplishments that we're proud of
We’re proud of our impressive data-wrangling rodeo. PubMed articles are very unstructured, heterogeneous data in the form of text. While natural language processing (NLP) tools make it easier to process, we were able to devise a method to accurately and efficiently extract information.
We’re also proud of our ability to combine our interdisciplinary backgrounds into an equally interdisciplinary project. Our group of former business students benefited from amazing project management and organization. Our teammates who are former chemical engineering students were able to leverage chemical structures as an additional feature in our machine learning model.
What we learned
We’ll definitely remember how to spell ‘schizophrenia’ after this hackathon!
Project management was very challenging because of the virtual nature of the hackathon. We learned efficient workflows for communication like communicating data flow using entity relationship diagrams (ERDs) and delegating tasks in swim lanes to ensure parallelism.
What's next for neurolens
Our current limitation is data and methods for the evaluation of our model. In the future, we’d like to extend the model to handle multiple drugs and other neurological disorders. While our scoring function makes use of chemical structure similarities between the drugs, other similarity measures should be explored. We’re considering, with additional data, using a variational autoencoder in order to represent chemical structures in a latent space with greater generative and predictive power. This could be leveraged to predict the side effects of understudied drugs and estimate the pharmacological profile of these drugs.
You can try it out by going to www.neurolens.tech or by cloning https://github.com/nathanielbd/neurolens and running
pip install -r requirements.txt
python3 main.py






Log in or sign up for Devpost to join the conversation.