
Inspiration
- Addressing Data Scarcity: The fundamental need to overcome limitations of insufficient real-world data for robust AI training, especially for rare events or new scenarios.
- Enhancing Data Privacy & Compliance: The critical requirement to use data safely without exposing sensitive information, adhering to regulations like GDPR and HIPAA.
- Improving AI Model Quality & Fairness: The drive to build more robust, generalizable, and unbiased AI models by providing diverse and balanced training data.
- Accelerating Development & Reducing Costs: The desire to significantly speed up AI development cycles, reduce manual data efforts, and lower associated expenses.
- Enabling Scalability & Innovation: The vision for a system capable of generating data at the massive scale required for large AI applications, fostering continuous testing and new feature development.
What it does
- Generates Billions of Synthetic Data Points: Creates vast quantities of artificial data to overcome real-world data limitations for ML projects.
- Fills Data Gaps: Synthesizes data for rare events, niche domains, or hypothetical scenarios where real data is scarce.
- Ensures Privacy & Confidentiality: Produces data safe for use without exposing sensitive personal or proprietary information, aiding regulatory compliance.
- Mitigates Bias & Enhances Fairness: Corrects inherent biases in real data and balances datasets for more equitable AI outcomes.
- Improves Model Performance & Generalization: Provides diverse training examples, including edge cases, to build more robust and generalizable AI models.
- Accelerates Development & Testing: Speeds up AI model prototyping, iteration, and rapid testing by providing on-demand, automatically labeled data.
- Reduces Costs & Time: Significantly lowers expenses and time associated with collecting, preparing, and anonymizing real datasets.
- Supports Scalability: Enables the generation of test data at the massive scale required for large-scale AI applications.
How we built it
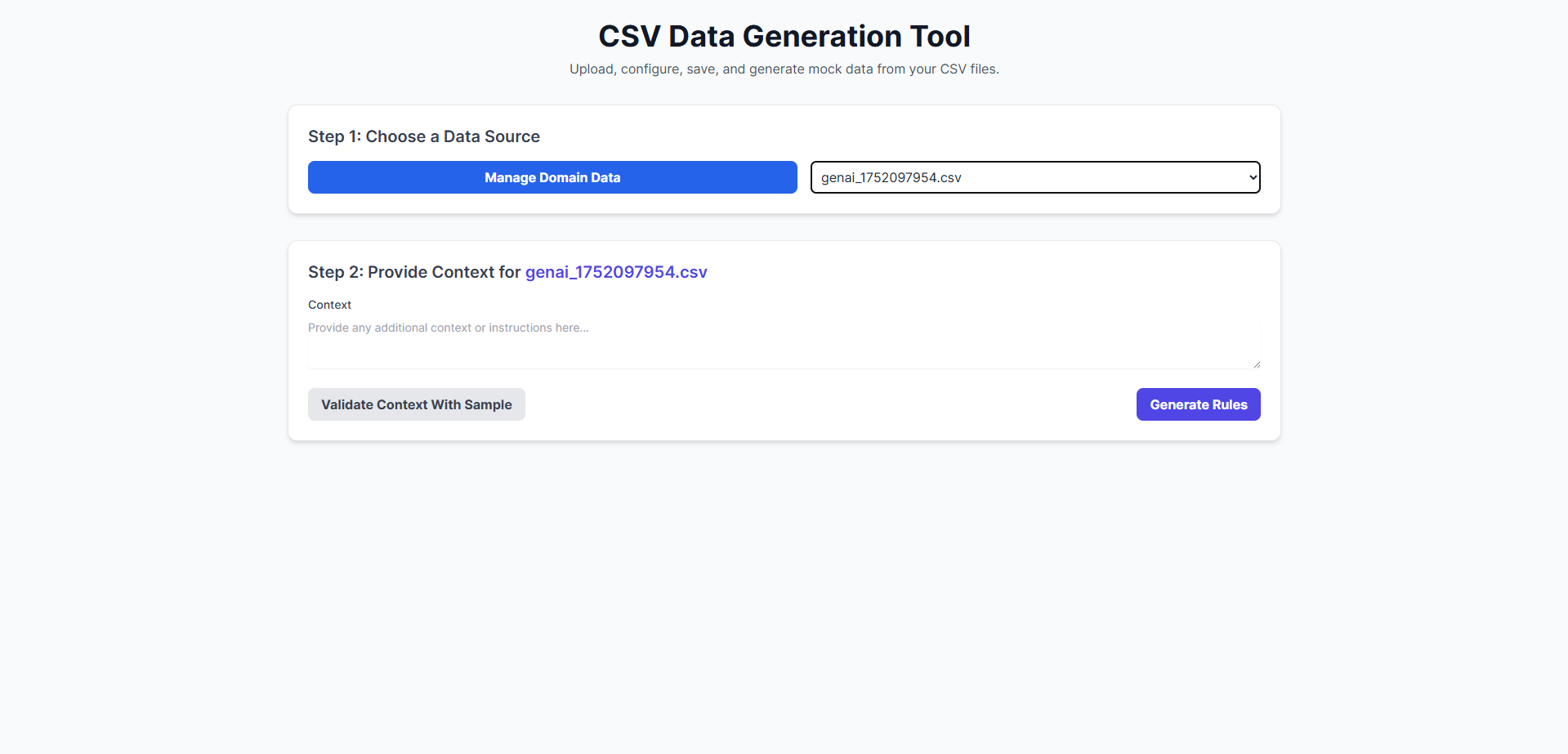
- Architected as an End-to-End Pipeline: It was designed with a complete workflow in mind, starting from connecting to data sources and ending with validated, production-ready synthetic data.
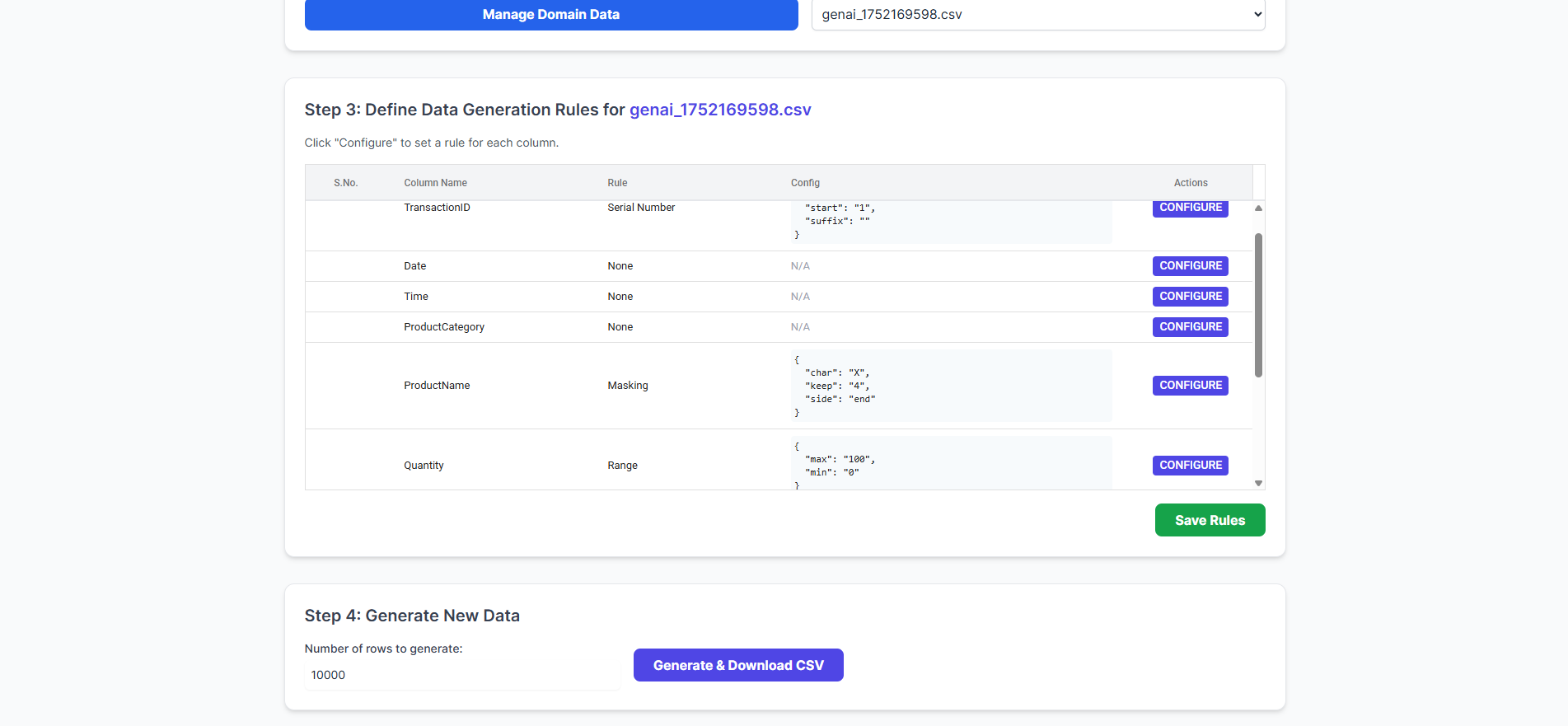
- Integrated with Profiling & Configuration Tools: Mechanisms like HTML-based schedulers were incorporated for profiling existing data and configuring the synthetic data generation rules.
- Incorporated Data Transformation Techniques: Sensitive data handling was built in, utilizing methods such as masking, encryption, and obfuscation to ensure privacy and compliance.
- Developed with a Robust Generation Engine: A core engine was created to produce data in desired volumes and formats (e.g., JSON, CSV, Parquet), capable of handling billions of records.
- Utilized a Cloud-Native AWS Tech Stack: The infrastructure was built on various AWS services, including S3 for storage, Fargate/Lambda for compute, DynamoDB/RDS for databases, and Glue for ETL, ensuring scalability and efficiency.
Challenges we ran into
- Ensuring Synthetic Data Quality and Realism: The biggest hurdle is generating synthetic data that accurately mirrors the statistical properties, correlations, and complexities of real-world data, including rare events and edge cases, to be truly useful for robust ML model training.
- Achieving Massive Scalability and Performance: Handling the generation, storage, and management of billions of data points efficiently requires a highly optimized and scalable architecture, posing challenges in distributed computing, I/O performance, and cost management on cloud platforms like AWS.
- Implementing Robust Privacy-Preserving Techniques: Developing and integrating advanced masking, encryption, and obfuscation methods that effectively protect sensitive information without compromising the utility of the synthetic data, while ensuring compliance with evolving regulations (GDPR, HIPAA, etc.).
- Mitigating Bias and Ensuring Fairness in Generation: Actively identifying and correcting inherent biases from real-world data, or preventing the introduction of new biases during the synthetic generation process, is a complex ethical and technical challenge.
- Defining Comprehensive Data Generation Rules and Automation: Establishing precise and exhaustive rules for generating diverse data across various schemas and data types, and automating the labeling process, can be incredibly complex and time-consuming, especially for nuanced or unstructured data.
Accomplishments that we're proud of
- Successfully Generating Billions of High-Quality Synthetic Data Points: Achieving the core goal of producing vast quantities of realistic and statistically representative data, effectively overcoming real-world data scarcity.
- Establishing a Scalable, Cost-Efficient Cloud Infrastructure: Designing and implementing an architecture on AWS that can handle immense data generation and processing loads while optimizing resource utilization and minimizing operational costs.
- Pioneering Advanced Privacy-Preserving Data Synthesis: Developing and deploying sophisticated techniques that enable safe data utilization and sharing, setting a new standard for privacy compliance in AI development.
- Demonstrating Significant Improvements in AI Model Performance: Proving that models trained on NeuroFabric's synthetic data achieve superior generalization, robustness, and fairness compared to those trained on limited or biased real data.
- Revolutionizing AI Development Cycles: Drastically reducing the time and effort traditionally required for data acquisition and preparation, thereby accelerating prototyping, testing, and deployment of AI solutions.
- Enabling Innovation in Data-Scarce Domains: Providing a vital tool that allows for the development and testing of AI applications in niche or emerging areas where real-world data is inherently difficult to obtain.
What we learned
- Deep Understanding of Synthetic Data Methodologies: Gaining expertise in various synthetic data generation techniques (e.g., GANs, VAEs, statistical modeling, rule-based generation) and their strengths/weaknesses for different data types.
- Scalable Cloud Architecture Design & Implementation: Hands-on experience with designing, deploying, and managing highly scalable, cost-optimized solutions on cloud platforms (specifically AWS services like S3, Fargate, Lambda, DynamoDB, Glue) for large-scale data processing.
- Advanced Data Privacy & Security Engineering: Learning to implement robust data masking, encryption, obfuscation, and de-identification strategies to ensure compliance with global privacy regulations (GDPR, HIPAA, CCPA).
- Bias Detection and Mitigation in AI Systems: Developing critical skills in identifying and addressing inherent biases in data, and designing algorithms that generate fairer and more representative datasets.
- Complex Data Modeling & Schema Management: Mastering the art of understanding diverse data schemas, defining intricate generation rules, and ensuring high fidelity between synthetic and real-world data structures.
- Performance Optimization for Big Data Workloads: Acquiring knowledge in optimizing data pipelines, storage, and compute resources to handle billions of records efficiently and minimize latency.
- Full-Stack AI/ML MLOps & DataOps Practices: Understanding the end-to-end lifecycle of AI model development, from data generation and preparation to model training, deployment, and continuous integration/delivery (CI/CD) with automated data pipelines.
- Problem-Solving for Data Scarcity & Quality Issues: Developing innovative solutions to overcome common challenges like insufficient data, imbalanced datasets, and the need for diverse training examples.
What's next for NeuroFabric
NeuroFabric is already quite advanced, but the field of synthetic data and AI is evolving rapidly. Here's "what's next":
- Enhanced Realism and Fidelity for Complex Data Types: Moving beyond tabular data to generate highly realistic synthetic images, videos, audio, and unstructured text that accurately capture nuances, context, and semantic meaning, especially for highly sensitive domains like medical imaging or autonomous driving simulations.
- Active Learning and Feedback Loops for Synthesis: Integrating continuous feedback from ML model performance back into the synthetic data generation process, allowing NeuroFabric to intelligently adapt and generate data specifically to address model weaknesses, biases, or underrepresented edge cases.
- Integration with Explainable AI (XAI) and Interpretability: Developing methods to not only generate data but also to provide insights into why certain synthetic data points were created, and how they contribute to model decisions, enhancing trust and transparency.
- Federated and Decentralized Synthetic Data Generation: Exploring architectures where data synthesis can occur closer to the data source (e.g., on edge devices or in distributed environments) without centralizing raw sensitive data, further bolstering privacy and compliance for diverse organizations.
- Industry-Specific Synthetic Data Platforms: Specializing NeuroFabric's capabilities and pre-trained generation models for specific industries (e.g., finance for fraud detection, healthcare for drug discovery, retail for customer behavior simulation) to offer tailored, high-value solutions.

Log in or sign up for Devpost to join the conversation.