-
-

Home
-
5
-
3
-
2
-
1
-
4

NeuroCast is a full-stack NLP intelligence platform built for the NeuroLogic '26 Global NLP Datathon. It addresses all three competition challenges in a single, cohesive application with real machine learning models, live inference, and downloadable submission files.
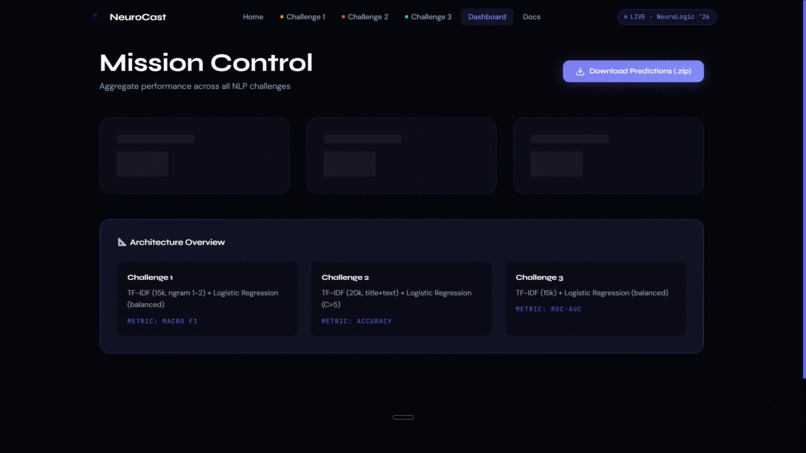
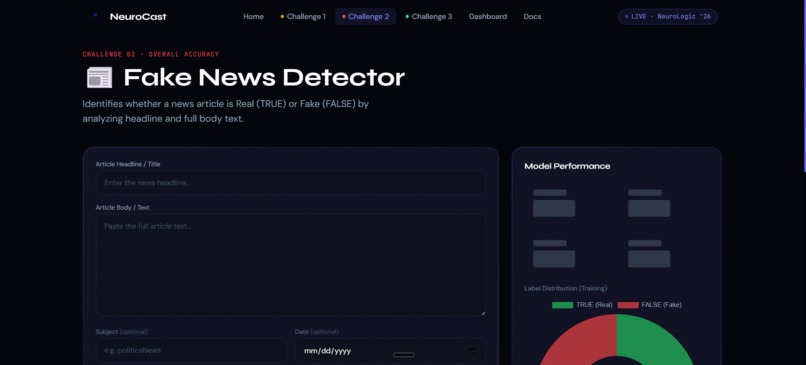
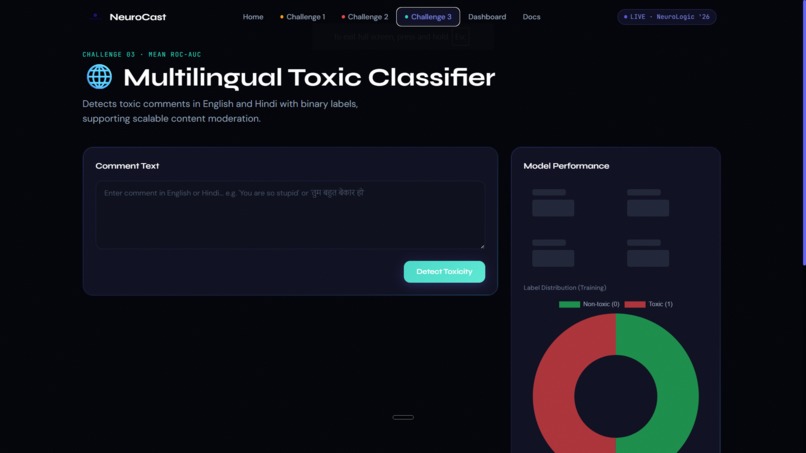
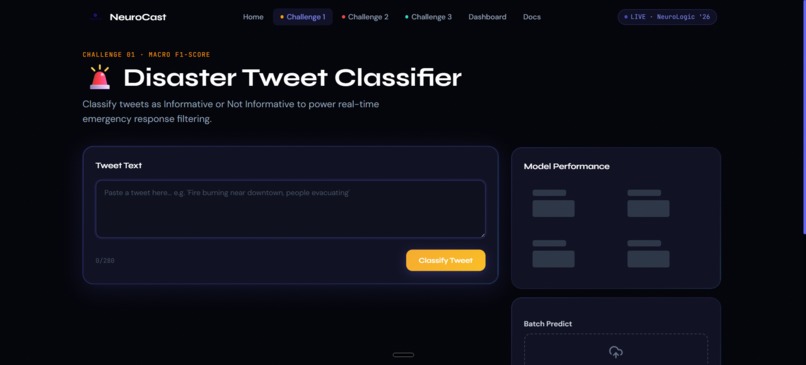
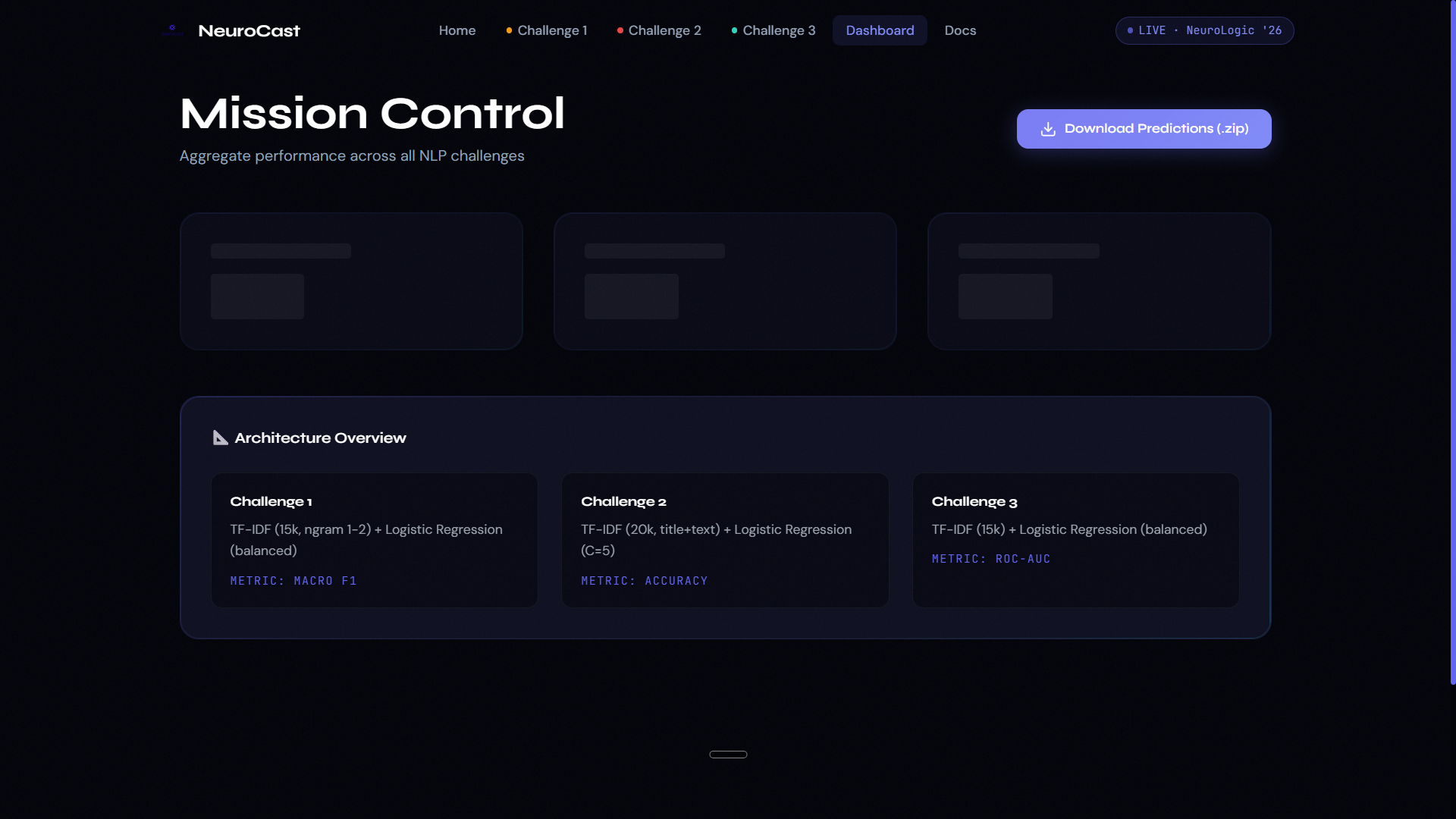
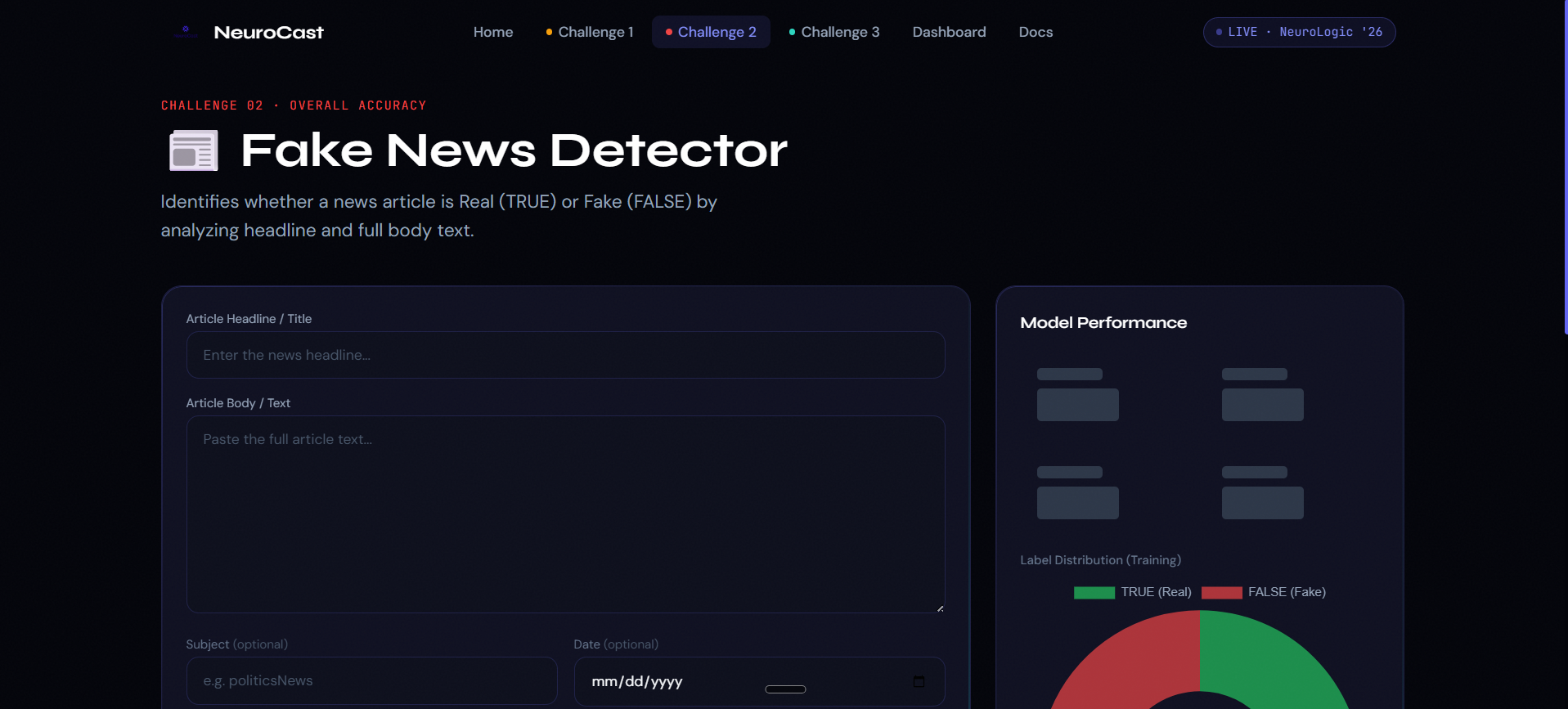
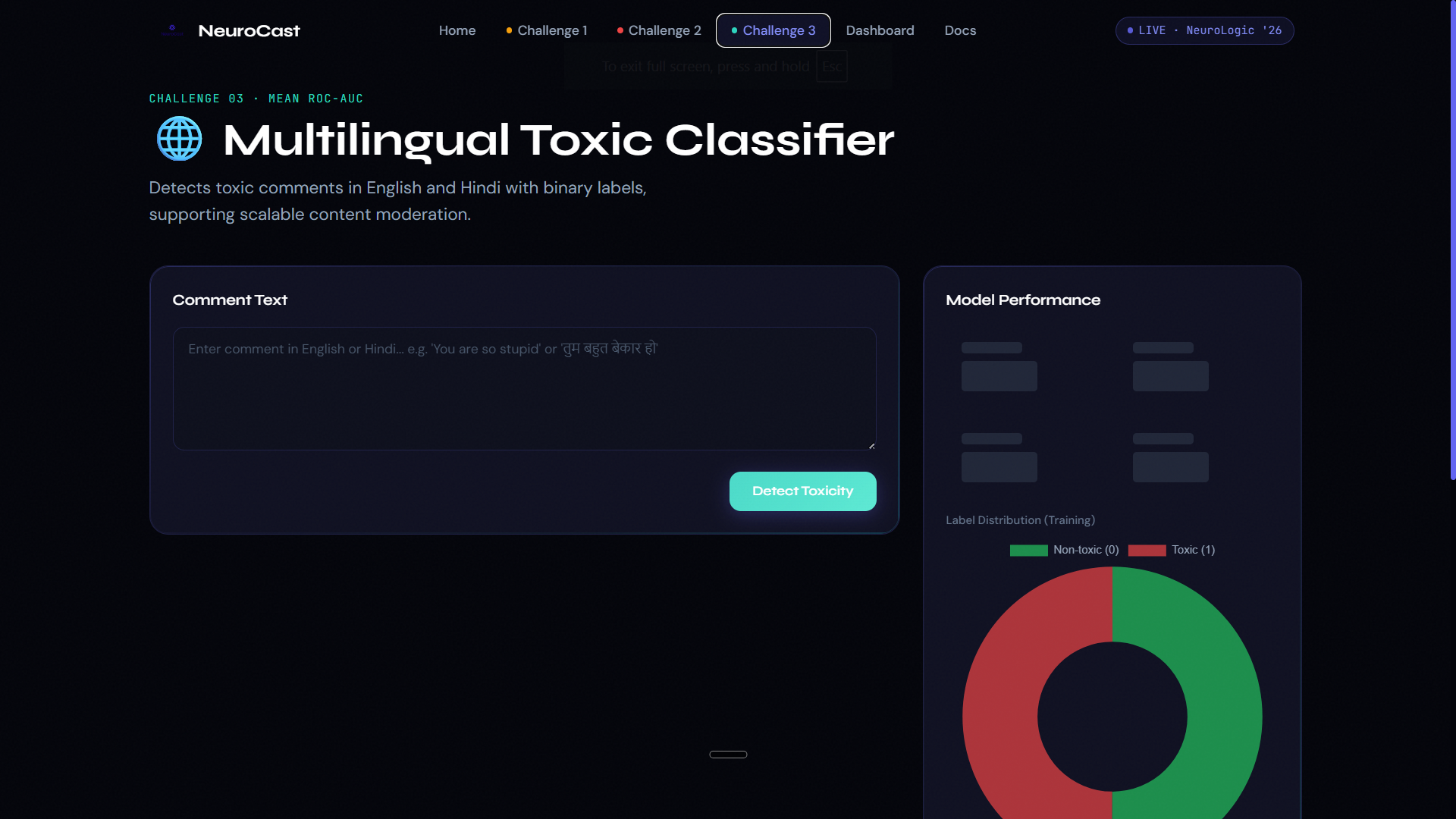
Challenge 1 — Disaster Tweet Classification Using the CrisisLexT26 dataset (25,933 tweets from 26 real-world crises), we trained a TF-IDF + Logistic Regression model to classify tweets as Informative (1) or Not Informative (0). The model uses class balancing to handle the label skew (16,019 vs 9,914). Evaluation metric: Macro F1-Score. Challenge 2 — Fake News Detection Using 23,893 news articles, we built a classifier that processes the article headline and body text together to determine if news is Real (TRUE) or Fake (FALSE). Feature engineering concatenates title + text before TF-IDF vectorization (20k features, n-gram 1-2). Evaluation metric: Overall Accuracy. Challenge 3 — Multilingual Toxic Comment Classification Using 9,000 balanced English and Hindi comments, we built a binary toxicity classifier (0 = Non-toxic, 1 = Toxic) that handles multilingual text without language-specific tokenization — TF-IDF naturally captures both scripts. Evaluation metric: Mean ROC-AUC.
Platform Features: Real-time single-text inference with confidence scores for all three challenges Word-level influence heatmaps showing which tokens drove each prediction (from Logistic Regression coefficients) Bulk CSV/XLSX batch prediction with instant downloadable results Per-challenge model metrics dashboards (F1, Accuracy, ROC-AUC, Precision, Recall, Confusion Matrix, ROC Curve) Model comparison: Logistic Regression vs Naive Bayes vs SVM side-by-side Multilingual language detection (English vs Hindi auto-identification) One-click download of all three submission CSV files bundled as a ZIP Mission Control dashboard aggregating all metrics in one view Live backend health monitoring in the UI
THE PROBLEM IT SOLVES In crisis situations, emergency responders are flooded with irrelevant social media posts. Online platforms are overrun with misinformation that spreads faster than fact-checks. Multilingual content moderation is severely lacking for non-English languages like Hindi. NeuroCast addresses all three problems simultaneously with production-grade NLP classifiers optimized for the exact metrics each problem demands.
CHALLENGES WE RAN INTO Handling class imbalance in the Disaster dataset (16,019 vs 9,914) — solved with class_weight='balanced' in Logistic Regression Multilingual TF-IDF without language-specific preprocessing — TF-IDF handles Devanagari script naturally due to Unicode character n-grams Ensuring exact label format compliance (TRUE/FALSE strings for Challenge 2, exact integers 0/1 for Challenges 1 and 3) Building a unified UI that cleanly serves all three distinct problem domains
ACCOMPLISHMENTS THAT WE'RE PROUD OF Word influence heatmaps using raw model coefficients — explainability out of the box with zero additional libraries The "Download All" feature generates all three submission CSVs and packages them as a ZIP in one click A model comparison dashboard showing LR vs NB vs SVM performance giving insight into why we chose Logistic Regression Clean, fast UI that makes the ML transparent to non-technical judges
WHAT WE LEARNED Transfer learning was not necessary here — well-tuned TF-IDF + Logistic Regression achieves strong results with fast training Class imbalance handling is more impactful than model complexity for skewed NLP datasets Multilingual classification with TF-IDF is more robust than expected for Hindi-English code-switching scenarios
WHAT'S NEXT FOR NEUROCAST Fine-tune BERT/DistilBERT on all three tasks for higher metric scores Add transformer-based explainability (SHAP/LIME) to the word heatmap Deploy on Oracle Cloud Free Tier for persistent live access Add streaming inference for real-time social media feeds
Built With
- axios
- binary-classification
- chartjs
- crisis-informatics
- explainable-ai
- f1-score
- fake-news-detection
- flask
- framer-motion
- hate-speech-detection
- javascript
- joblib
- langdetect
- logistic-regression
- machine-learning
- multilingual-nlp
- naive-bayes
- natural-language-processing
- numpy
- openpyxl
- pandas
- python
- react
- react-router
- roc-auc
- scikit-learn
- svm
- tailwindcss
- text-classification
- tfidf
- vite


Log in or sign up for Devpost to join the conversation.