-
-
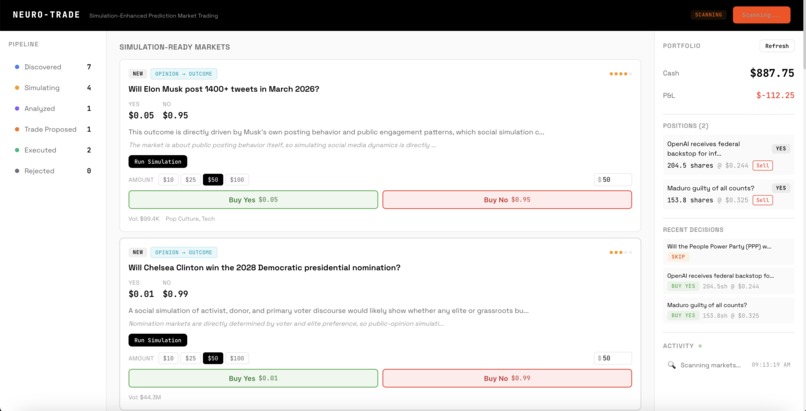
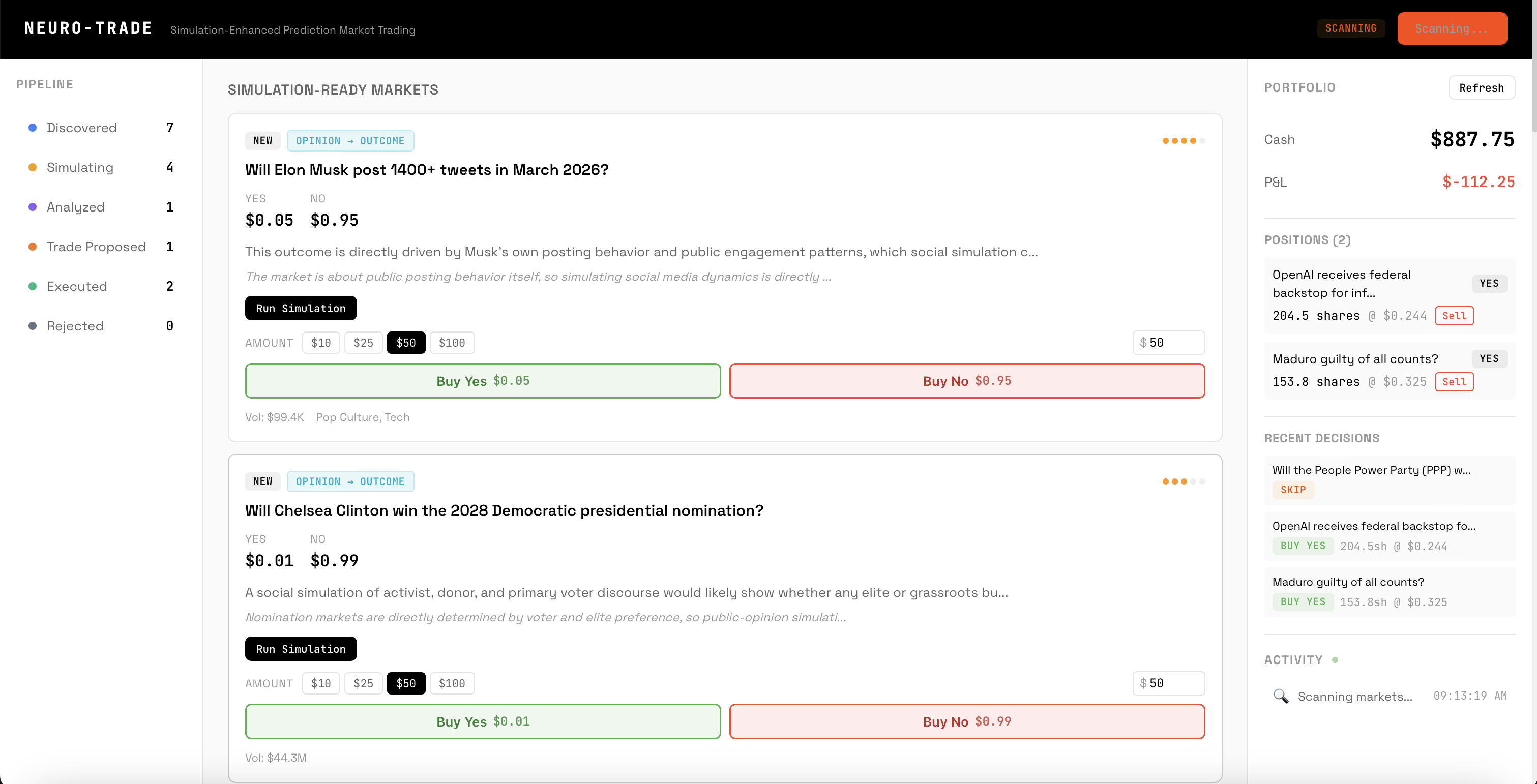
landing page with bets scanned by the platform
-
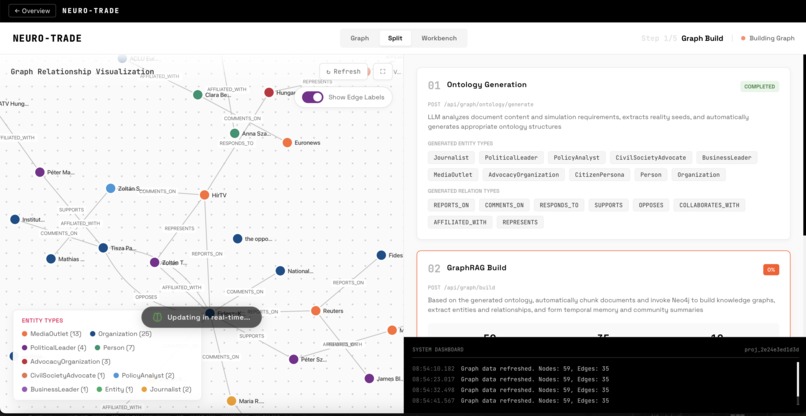
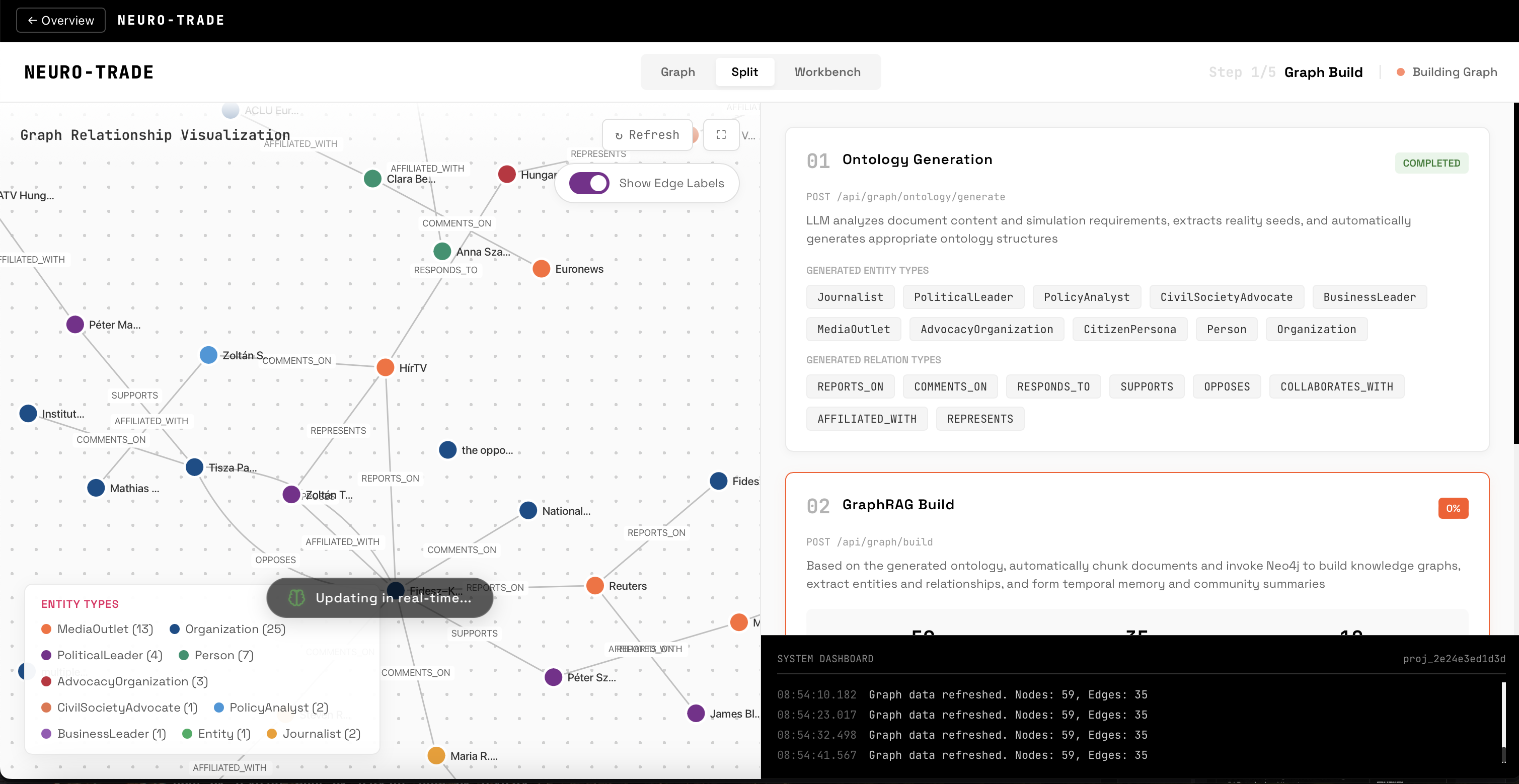
preparing simulation graph
-
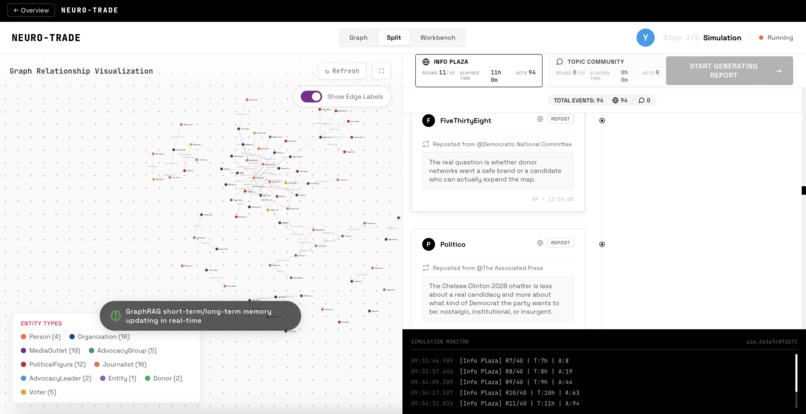
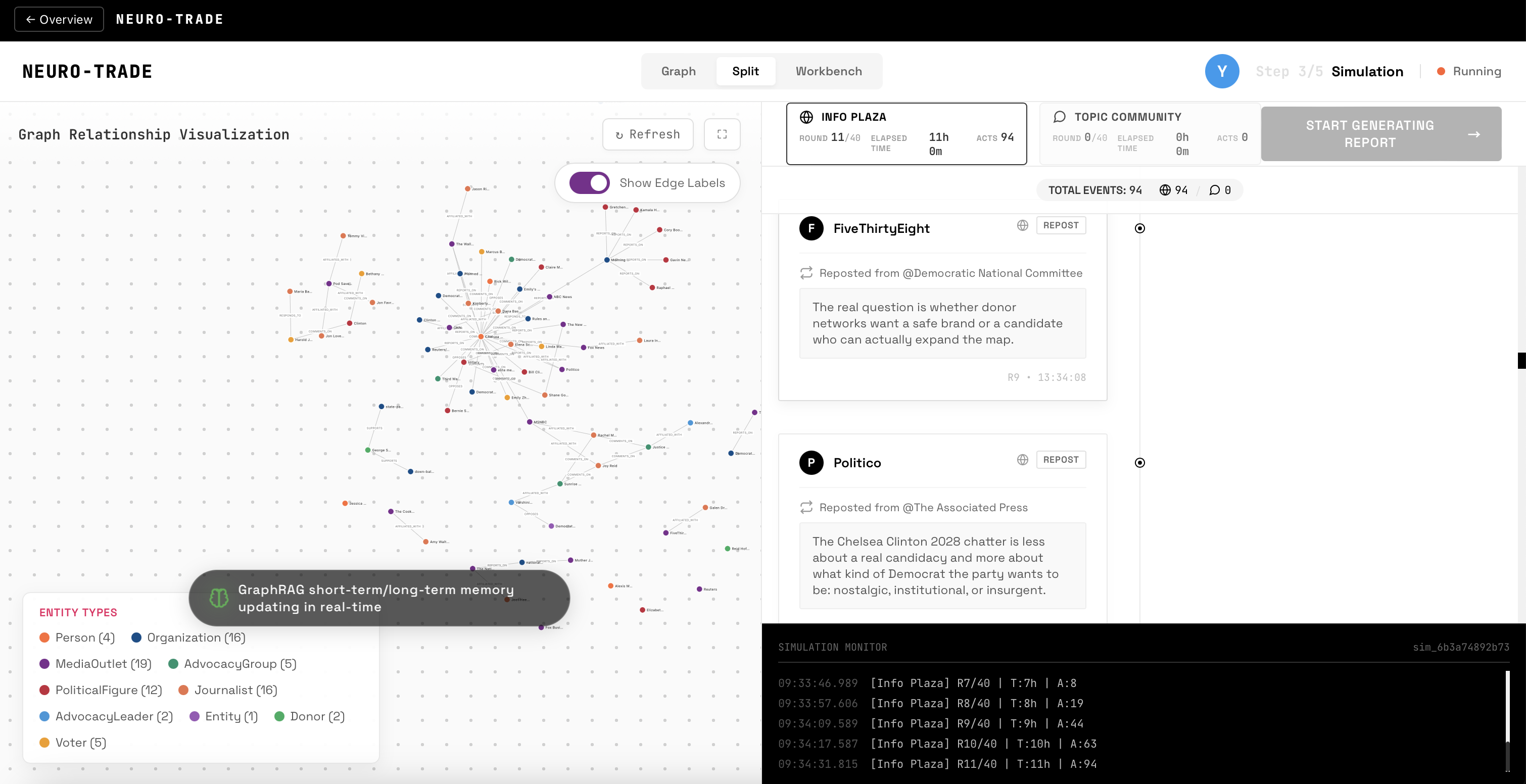
agents interacting in the simulation - they can repost, like, comment, etc.
-
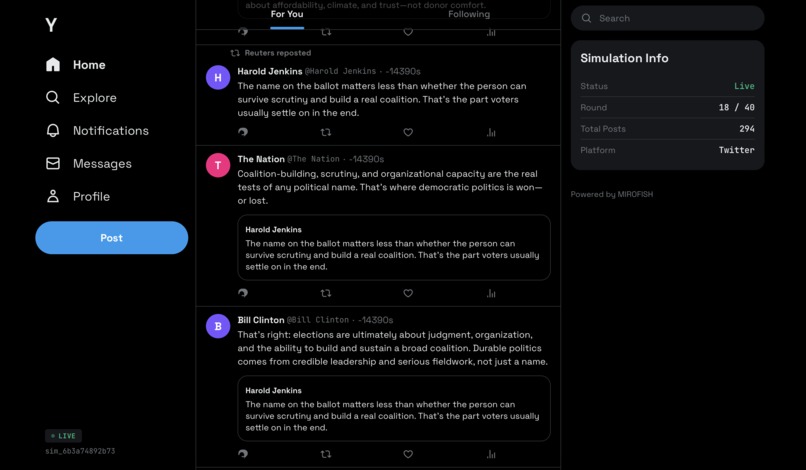
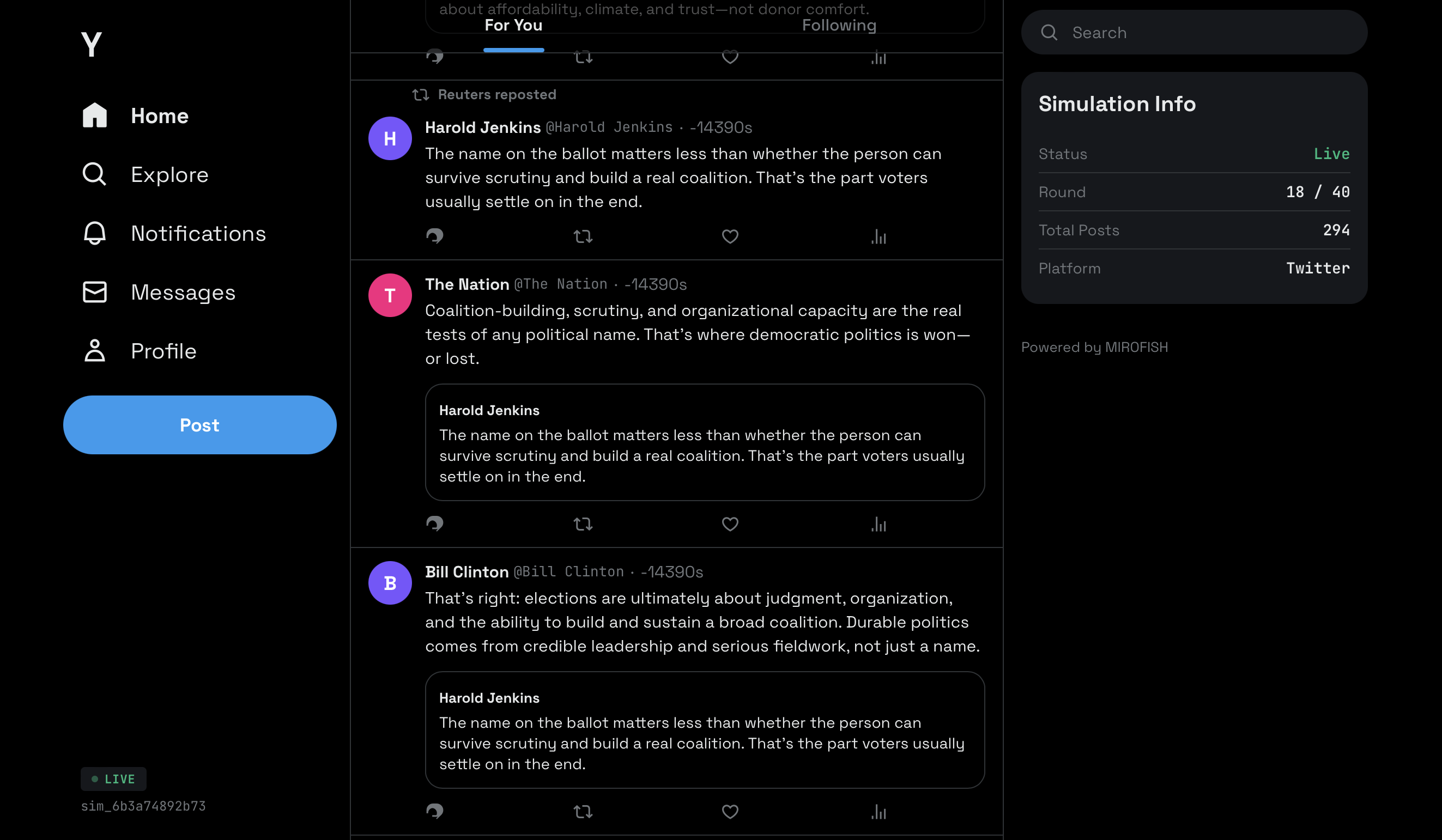
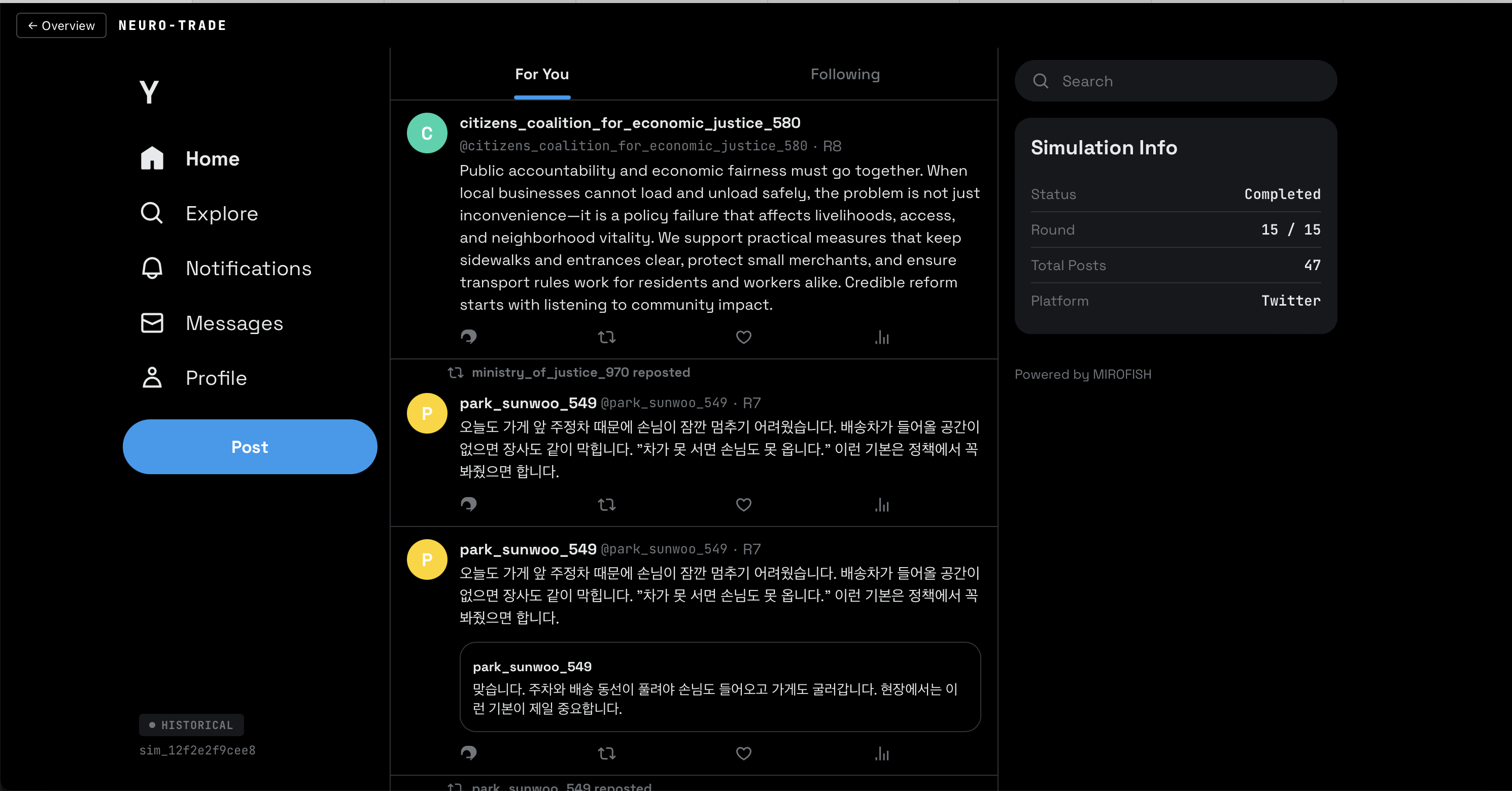
Y.com - our simulated social media
-
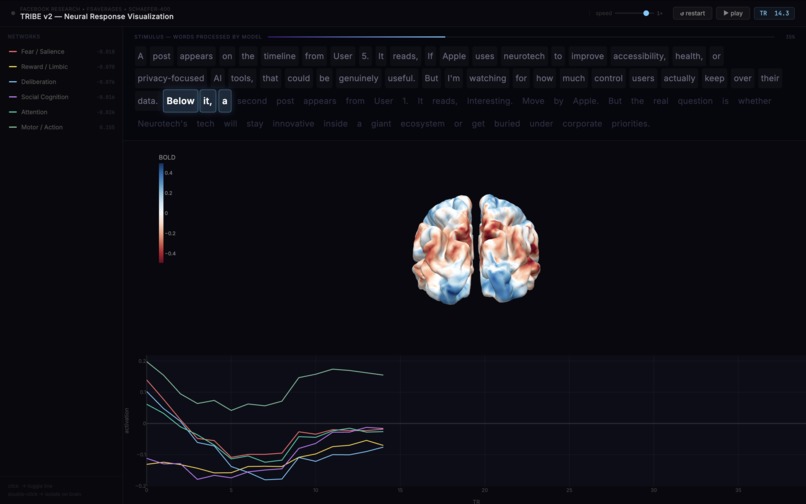
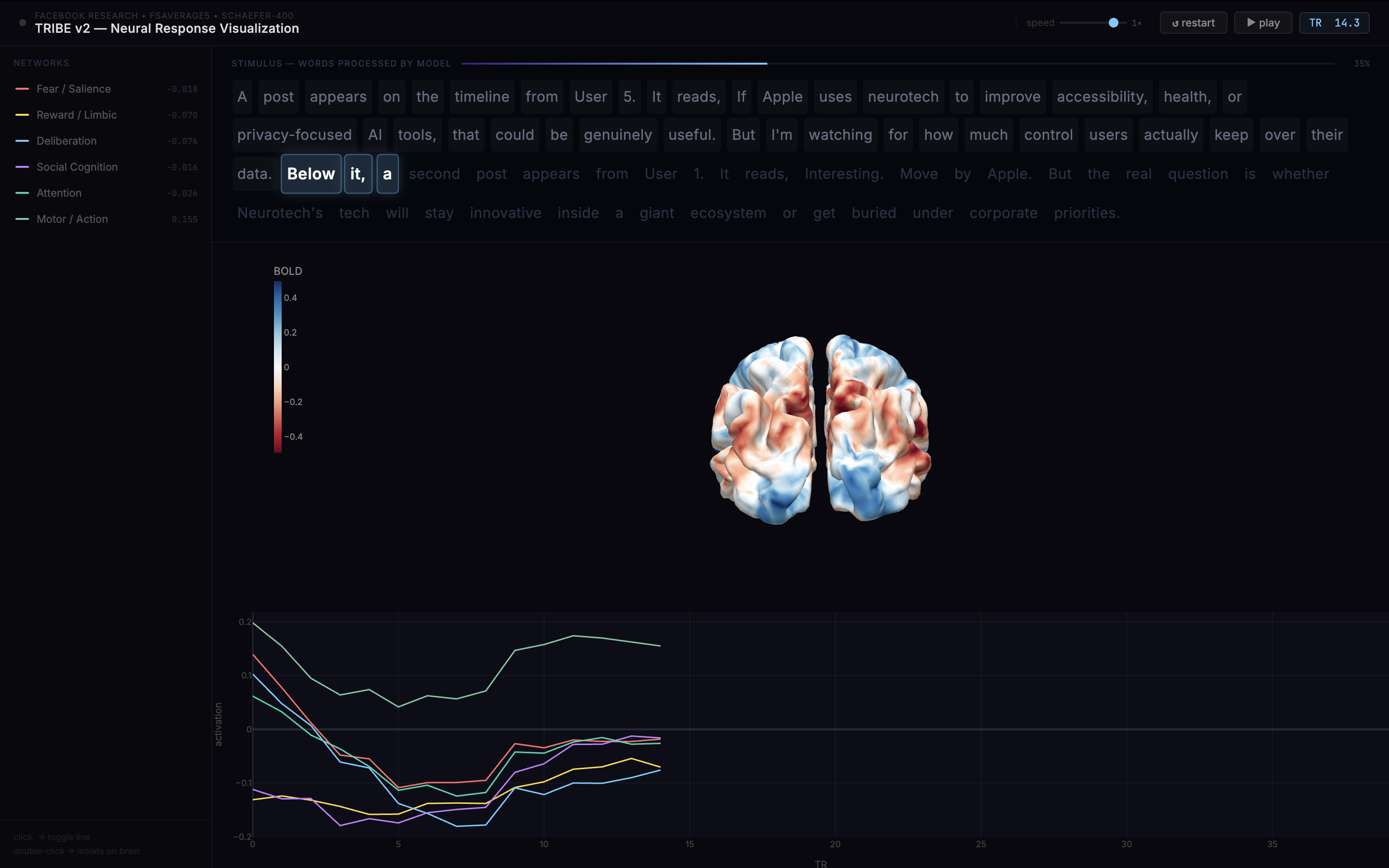
predicting fMRI activity for user reading Twitter feed
-
Y.com supports multiple languages!
-
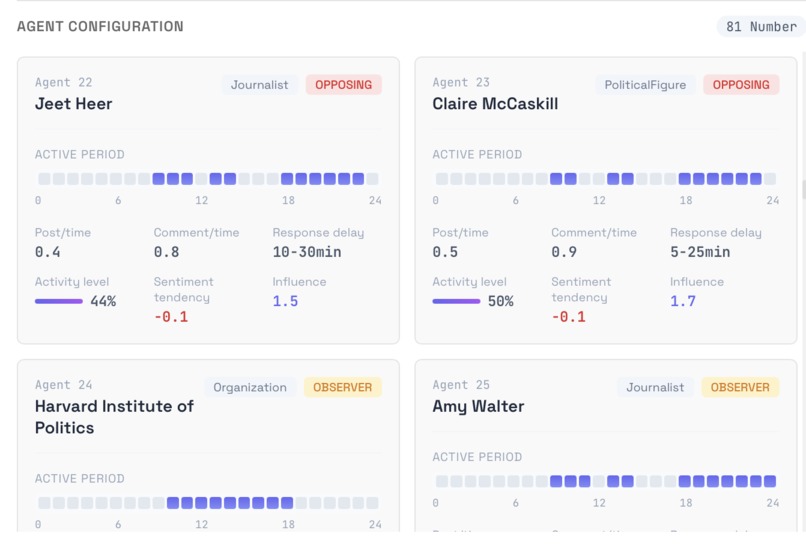
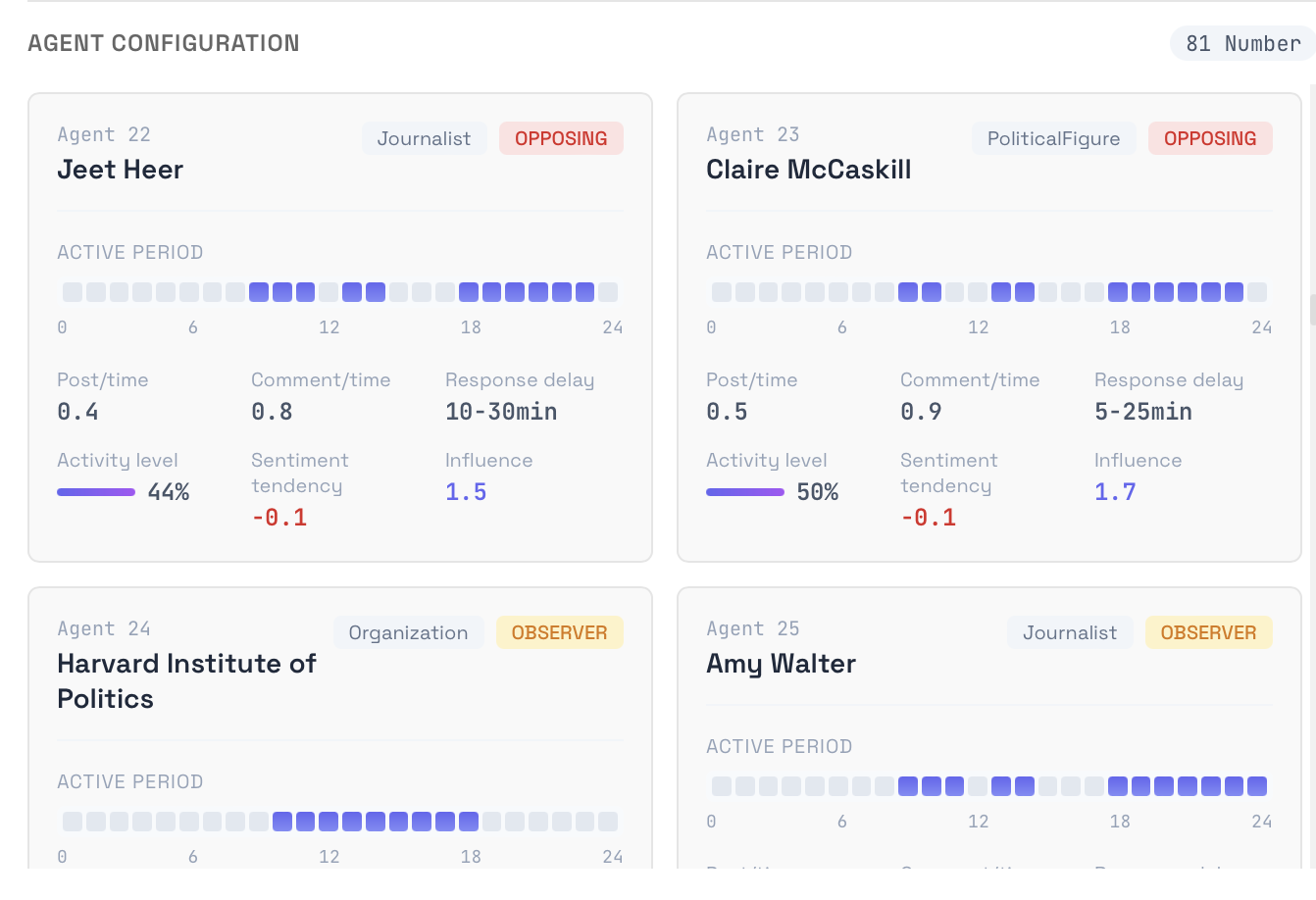
simulation agents time schedule and configuration
-
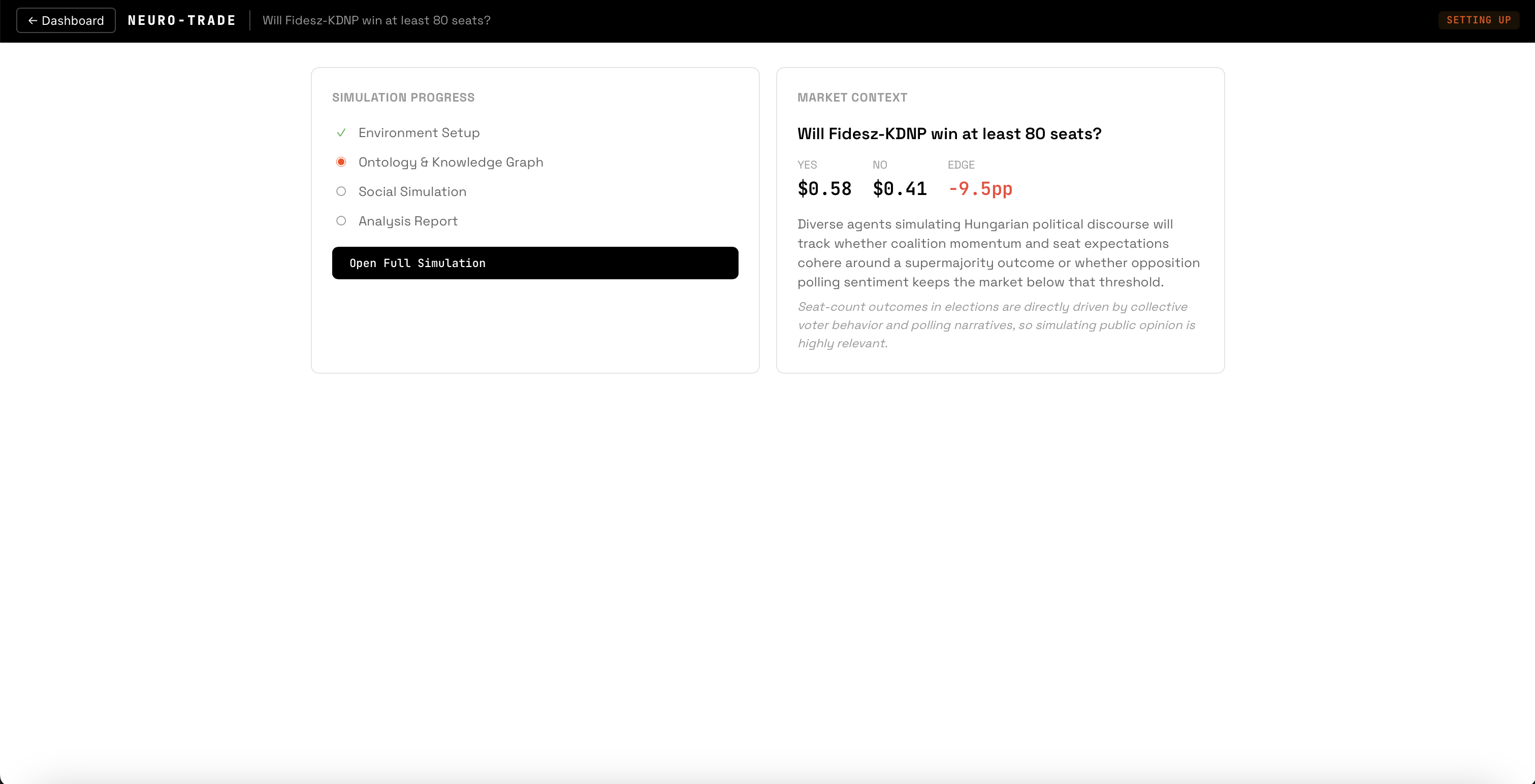
market page while simulation is loading
Neuro-Trade: Brain-Enhanced Swarm Intelligence for Prediction Markets
What if you could run a focus group of 100 neurologically-realistic people before placing a bet related to human behavior? By actually simulating their brains. That's what Neuro-Trade does.
The Problem
A huge share of Polymarket volume sits in markets that are fundamentally sentiment-driven—elections, approval ratings, boycotts, policy battles, cultural moments. The outcome depends on what people believe, how they react, and how opinion cascades through the public.
Existing approaches to sentiment analysis—scraping Twitter, running polls, prompting an LLM for a vibes check—capture what people are already saying. Just a very few of them simulate how a population would react to an event that hasn't fully played out yet. But even swarms of LLMs show divergent behaviour. We are the first to ground the agents in realistic neural cognitive states using predicted fMRI brain activations, making the simulation closer to how real humans actually process information and form opinions—not just how LLMs role-play them.
Concretely, before each agent decides what to post or engage with, a neuroscience model predicts how their brain would respond to the content they've been reading—which regions activate, how strongly, and how they interact—and that cognitive state silently shapes their next action.
We distinguish two categories where this gap creates edge:
- Direct sentiment markets — Public opinion literally IS the outcome. Elections, approval ratings, boycotts, policy referendums. If you can simulate the crowd, you're simulating the resolution mechanism itself.
- Indirect sentiment markets — The outcome is determined by external factors, but the price moves on shifting perceived likelihood. A market sitting at $0.04 doesn't need to resolve YES to generate alpha—if simulation reveals belief momentum building before the market prices it in, you capture the move. The edge isn't in predicting the outcome; it's in predicting the crowd's conviction before they get there.
Both categories are underserved by existing tools. Neuro-Trade is built specifically for them.
The Solution
Neuro-Trade is a prediction market trading system that simulates public reaction to real-world events using AI agents grounded in neuroscience—then trades on the signal.
Three layers of intelligence in a single pipeline:
- Multi-Agent Social Simulation — A simulated Twitter ("Y.com") where AI personas debate, react, and form opinions about real Polymarket events
- Neural Brain Encoding — Meta's TRIBE v2 model (released March 2025) predicts fMRI brain responses to what agents are reading, injecting neurologically-grounded cognitive states into their decision-making
- Autonomous Trading Agent — Scans Polymarket for sentiment-dependent opportunities, triggers simulations, and paper-trades against real order books

Workflow
Scan — The trading agent crawls Polymarket for sentiment-dependent markets and classifies each as direct or indirect. Markets are scored 1-5 on simulation potential and filtered by volume (>$10K), liquidity, and expiry (>24h).
Build — For high-potential markets, MiroFish constructs a knowledge graph from the event description—extracting entities (senators, companies, advocacy groups) and their relationships. A synthetic population of 5-100 diverse personas is generated to represent the general public.
Simulate — All agents are dropped into Y.com. Over multiple rounds, they post, like, repost, and quote-tweet based on their personas and feed. Each round, TRIBE v2 processes each agent's feed through a full neuroscience pipeline—predicting cortical surface activations across 20,484 brain vertices, extracting ROI timeseries, computing connectivity between brain regions, and condensing it into composite cognitive scores. These neural states silently shape agent behavior the way mood shapes your next tweet.
Analyze — A ReportAgent examines the full simulation discourse: net sentiment shifts, key opinion drivers, influence dynamics, and how neural priming cascaded through the population.
Trade — The trading agent compares the simulation's sentiment signal against the current market price on Polymarket's real CLOB order book. If the market is mispriced, it executes a paper trade with realistic slippage against actual bids and asks.

How We Built It
The Trading Agent
Built on the OpenAI Agents SDK with MCP (Model Context Protocol) tool servers:
- Polymarket Server — 7 tools wrapping Gamma API (market discovery, tags, search) and CLOB API (order books, live prices, token resolution)
- Paper Trading Server — 8 tools for portfolio management, market buy/sell with realistic slippage simulation, P&L tracking, and trade journaling
- MiroFish Tool — Drives the full 7-step simulation lifecycle (create project → build graph → generate personas → run simulation → generate report)
- Web Search — Supplements simulation with real-time news context
Paper trading uses real Polymarket CLOB data—actual bids, asks, and liquidity. Only the money is simulated ($1,000 starting balance, $100 max position).
MiroFish Social Simulation
MiroFish is built on top of OASIS (by CAMEL-AI), which is an established multi-agent social simulation framework used in academic research for modeling information propagation and opinion dynamics on social platforms. MiroFish extends OASIS with a knowledge graph layer, entity extraction, and a guided simulation workflow.
We forked MiroFish and added the following:
- Cloud LLM support — Replaced local Ollama/Qwen-Plus with OpenAI GPT-4o/4o-mini via cloud API, translating all system prompts to English for US-centric Polymarket scenarios
- Neo4j AuraDB migration — Moved from local Neo4j Community Edition to cloud-hosted AuraDB with proper
neo4j+s://URI and database name support - Synthetic population generation — A new module that generates 5-100 diverse personas (students, engineers, parents, retirees) via a single LLM call, writes them to Neo4j with a
:Syntheticlabel andINTERESTED_INedges, and feeds them through the same profile pipeline as document-extracted entities. This is critical—real public sentiment isn't just institutional voices. - Y.com live feed — A full Twitter/X-styled dark theme frontend (500+ lines of Vue.js) with live polling mode (3-second intervals during active simulations with animated tweet entry), historical infinite scroll, deterministic avatars, engagement buttons with X.com hover colors, quoted tweets, and repost headers

- Posts-feed API — New backend endpoint joining posts with user data and original post resolution for the Y.com display
- TRIBE v2 neural injection — Monkey-patching of OASIS
SocialAgent.perform_action_by_llm()to inject neural states into agent prompts before each decision, with clean prompt restoration afterward - Feed narrative builder — Converts OASIS JSON feeds (posts, likes, shares, engagement metrics) into ~250-word naturalistic narratives suitable for TRIBE v2 input
- Docker simplification — Removed Ollama and Neo4j containers, cloud-only deployment
TRIBE v2 Neural Module
This is what makes Neuro-Trade fundamentally different from "just another LLM simulation."
The problem with pure LLM role-play: When you tell GPT-4 to "act like an anxious voter reading bad polling numbers," it generates plausible-sounding text, but it doesn't model what actually happens cognitively. Real humans reading three fear-laden posts in a row don't rationally decide to feel afraid—their threat-detection circuitry activates, biasing subsequent processing before conscious evaluation kicks in. LLMs skip this entirely. They produce coherent personas but miss the subconscious priming effects that drive real opinion cascades.
TRIBE v2 (Text-to-fMRI Brain Interpretations through Embeddings, v2) is a ~3.8B parameter model from Meta/Facebook Research, released just days ago (March 2025). It predicts whole-brain fMRI activation patterns from naturalistic text—the same cortical surface data you'd get from putting someone in a scanner while they read. This is genuinely novel: no prior model predicts vertex-level cortical activations from text at this resolution.
We built a standalone FastAPI server that wraps TRIBE v2 in a 6-step neuroscience pipeline:
TRIBE v2 Forward Pass (2-5s on GPU) — Text is converted through TTS, forced alignment, LLaMA 3.2 text embeddings, and Wav2Vec-BERT audio features, then fused through a transformer and projected onto the cortical surface. Output:
(n_TRs, 20484)— predicted BOLD signal amplitudes across 20,484 cortical vertices (10,242 per hemisphere) at ~1.5-second temporal resolution.ROI Timeseries Extraction — A 3-layer approach reduces 20,484 vertices to 6 meaningful brain region signals: Schaefer 400-parcel functional atlas (binary masks from Yeo's 7 canonical networks), NiMARE meta-analytic weights (continuous weights from Neurosynth's ~14,000 study database), and nltools pre-trained neural signatures (VIFS for fear, PINES for negative emotion, with validation-gated fallback). The 6 ROIs: threat/fear response (salience network), analytical thinking (control network), social awareness (default mode), reward/opportunity (limbic), uncertainty/vigilance (dorsal attention), and motor readiness (somatomotor).

Summary Statistics — Each ROI timeseries is reduced to 11 interpretable features: peak activation, mean, area under curve, onset timing, time-to-peak, rise slope, full width at half maximum, sustained activation flag, trajectory direction, coefficient of variation, and decay slope. 66 statistics total.
Pairwise Connectivity — Pearson correlations between 7 predefined ROI pairs capture processing mode: is fear suppressing deliberation or reinforcing it? Is social awareness driving reward-seeking or independent of it? Single-region statistics can't capture these dynamics.
Composite Scores — 66 statistics + 7 connectivity values are condensed into 8 interpretable dimensions: valence, arousal, dominance (emotional vs. rational control), approach/avoid bias, reactivity speed, regulation trajectory, herding susceptibility, and signal confidence. Each computed via weighted formulas grounded in the neuroscience literature.
LLM-Readable Formatting — Everything is formatted into a ~30-line, ~500-token string with plain-language ROI names, inline scales, temporal curves with direction arrows, and a closing instruction: "Interpret the above as your internal experience right now. Do not reference these measurements in your response."
The formatted neural state is injected into each agent's system prompt before their action decision. The agent never sees "you are afraid"—it receives activation patterns and composite scores that implicitly shape its reasoning. After the decision, the original prompt is restored. If the TRIBE v2 server is unavailable, simulation continues without neural injection—each layer degrades gracefully.
Why this matters for trading: A simulation where agents process content through neurologically-grounded cognitive states—where fear primes threat responses that cascade through the social network, where reward activation biases approach behavior—produces fundamentally different sentiment dynamics than pure role-play. This is closer to how real public opinion actually forms.
Tech Stack
Backend (Python)
- OpenAI Agents SDK + MCP — Autonomous trading agent with Model Context Protocol tool servers for Polymarket, paper trading, and simulation orchestration
- FastAPI — Trading agent API server and TRIBE v2 neural processing server
- Flask — MiroFish social simulation backend with REST API
- Polymarket Gamma API + CLOB API — Market discovery, live pricing, and real order book data
- Neo4j AuraDB — Cloud-hosted knowledge graph for entity relationships and agent memory
- SQLite — Simulation data storage (posts, actions, engagement) and paper trading portfolio/trade history
- OpenAI GPT-4o / GPT-4o-mini — LLM backbone for agent personas, entity extraction, report generation, and synthetic population creation
- OpenAI text-embedding-3-small — Vector embeddings for hybrid semantic + BM25 search across the knowledge graph
Frontend (Vue 3 + TypeScript)
- Vue 3 + Vite — Component-based dashboard and MiroFish simulation interface
- D3.js — Knowledge graph visualization and sentiment analysis charts
- Y.com Feed UI — Custom Twitter/X-styled dark theme interface with live polling, animated tweet entry, deterministic avatars, and engagement interactions
AI/ML Pipeline
- Meta TRIBE v2 (~3.8B params) — Predicts whole-brain fMRI cortical surface activations from naturalistic text, released March 2025
- Nilearn — Schaefer 400-parcel functional atlas and fsaverage5 surface operations for ROI extraction
- NiMARE + Neurosynth — Meta-analytic weights from ~14,000 neuroimaging studies for evidence-based brain region weighting
- nltools (VIFS/PINES) — Pre-trained multivariate neural signatures for fear and negative emotion detection, with validation-gated fallback
- OASIS (CAMEL-AI) — Multi-agent social simulation framework powering the turn-based Twitter environment
- MiroFish — Knowledge graph-driven simulation workflow built on OASIS, heavily modified for cloud deployment and English-language US market scenarios
Neural Processing Pipeline
Text narrative → TRIBE v2 forward pass (TTS + LLaMA 3.2 + Wav2Vec-BERT → cortical surface) → ROI extraction (Schaefer + NiMARE + signatures → 6 brain regions) → summary statistics (11 features × 6 ROIs) → pairwise connectivity (7 region pairs) → composite scores (valence, arousal, dominance, approach/avoid, reactivity, regulation, herding, confidence) → LLM-readable neural state string → injected into agent prompt
Sponsor Integrations
Lava Network — Multi-Provider Ensemble Voting for Trade Proposals
In quantitative trading, a well-known technique for reducing model risk is to query multiple independent models and vote on the result. We use Lava Network's multi-provider API forwarding to do exactly this for our trade proposals.
When the trading agent is ready to decide on a position, it constructs a trade proposal prompt and sends it concurrently through Lava to three providers: OpenAI GPT-4.1, Anthropic Claude Opus, and DeepSeek V3.2. Each provider independently returns a trade side (buy/sell/skip), outcome, probability estimate, edge calculation, position size, and reasoning. Our ensemble module (ensemble.py) then aggregates:
- Trade side and outcome — Majority vote (defaults to skip on tie)
- Numeric fields (probability, edge, amount) — Median across providers
- Reasoning — Concatenated with provider tags for transparency
- Agreement metric — Percentage consensus, tracked per opportunity
This means no single model's hallucination or blind spot can drive a trade. If two out of three providers agree on a direction with consistent edge estimates, the signal is meaningfully stronger than any one model alone. The system falls back gracefully to single-provider analysis if Lava is not configured.
Nous Research Hermes — Humanistic Persona Generation
The quality of our social simulation lives or dies on how realistic the agent personas are. Generic LLM-generated personas tend to be flat—they hit demographic checkboxes but lack the internal contradictions and authentic voice that make real people's opinions unpredictable.
Nous Research's Hermes 3 (LLaMA 3.1 70B) is specifically tuned for natural, humanistic text generation. We route all persona creation through Hermes via OpenRouter:
- Synthetic population generation — When MiroFish needs 5-100 everyday personas for a simulation, Hermes generates them with genuine diversity: age 18-75, varied ethnicities, professions ranging from blue-collar to white-collar, political leanings from conservative to apolitical, tech-savviness from barely-uses-social to extremely-online, and location spread across urban, suburban, and rural America.
- OASIS agent profile enrichment — Hermes builds full agent profiles (age, gender, MBTI, profession, interests) enriched with knowledge graph context from hybrid vector + BM25 search, producing personas that feel like real people with specific perspectives rather than demographic templates.
All generated profiles are tagged with generated_by="hermes" for traceability. Falls back to the default LLM if Hermes is not configured.
K2 by MBZUAI — Deep Reasoning for Analysis and Orchestration
Neuro-Trade's pipeline produces two high-stakes analytical outputs: the simulation sentiment report (synthesizing hundreds of agent posts into actionable trading intelligence) and the trade proposal itself (deciding whether a market is mispriced and which direction to bet). Both require multi-step reasoning over complex, ambiguous inputs.
K2, MBZUAI's thinking model, excels at exactly this kind of extended reasoning. We integrate it at two points:
- Report generation — After a simulation completes, K2 (at high reasoning effort) analyzes the full discourse: interviewing focus-group agents, searching the knowledge graph for evidence, synthesizing sentiment shifts, identifying key opinion drivers, and producing a structured report. The extended thinking chain lets K2 work through contradictory signals rather than defaulting to surface-level summaries.
- Trade analysis — K2 evaluates the simulation report against current market pricing, reasoning through probability estimates, edge calculations, and position sizing. Its thinking blocks (stripped before JSON parsing) provide an auditable reasoning trace for every trade decision.
Challenges We Ran Into
1. Making MiroFish Work for US Markets
MiroFish was built for Chinese social media simulation (Weibo, Zhihu). We had to rearchitect it: swap Qwen-Plus for GPT-4o, translate all system prompts to English, switch from local Ollama to cloud APIs, replace Neo4j Community Edition with AuraDB, and rewrite the Docker setup. The "Americanization" touched almost every service file.
2. Neural State Injection Without Breaking Agent Behavior
Naively appending brain data to prompts caused agents to explicitly reference their "neural state" in tweets ("As someone experiencing high amygdala activation..."). We solved this by framing the injection as an implicit cognitive context—agents never see emotion labels, just activation patterns that subtly prime their reasoning. The monkey-patching also had to cleanly restore original prompts after each decision to prevent state leakage between rounds.
3. Building a Neuroscience Pipeline on a Model Released Days Ago
TRIBE v2 dropped this week. There are no tutorials, no community examples, no Stack Overflow answers. We built the entire 6-step pipeline—ROI extraction with three atlas layers, meta-analytic weighting from Neurosynth, signature validation with fallback, composite scoring—from scratch based on the model's output format and neuroscience fundamentals. The validation-gated signature transfer (testing whether VIFS/PINES patterns trained on real fMRI transfer to TRIBE v2 predictions) was especially tricky to get right.
4. Market Classification at Scale
Not every Polymarket bet benefits from social simulation. A market on "Will ETH hit $5K?" is fundamentally different from "Will the public support a TikTok ban?" We built a classification system (direct vs. indirect sentiment dependency, simulation potential 1-5) that filters thousands of markets down to the handful where our approach has genuine edge.
5. Real-Time Simulation + Live UI
Keeping the Y.com feed synchronized with an actively running simulation required careful polling design. We settled on 3-second polling with animated tweet insertion, which gives the feel of watching a real Twitter timeline unfold—without the complexity of true WebSocket state synchronization across multiple browser tabs.
Accomplishments We're Proud Of
First system to combine multi-agent social simulation with neural brain encoding for prediction market trading — we couldn't find anything like this in the literature or in production
Built a full neuroscience processing pipeline on a model that's days old — 6-step pipeline from raw cortical predictions to LLM-injectable cognitive states, with meta-analytic weighting, signature validation, and graceful fallback
End-to-end pipeline from market discovery to trade execution — scan Polymarket, classify opportunities, simulate public reaction, generate sentiment report, execute paper trade against real order books
Synthetic population generation — one LLM call produces dozens of diverse, realistic personas that sample general public sentiment, not just institutional voices
Y.com live feed — watching AI agents argue about politics in real-time on a Twitter clone is genuinely compelling, and makes the simulation legible to non-technical viewers
Direct vs. indirect trading strategies — not just "is sentiment positive?" but "does simulation show belief momentum shifting enough to move the market price before resolution?"
What We Learned
Simulation quality depends more on persona diversity than agent count. 50 carefully generated personas with distinct backgrounds produce richer discourse than 200 generic ones. The synthetic population generator was a bigger unlock than we expected.
Neural injection works best when invisible. Early versions where agents were told "your brain state suggests anxiety" produced stilted, self-conscious responses. Making the neural context implicit—like a mood you can't name but that colors everything—produced dramatically more natural behavior.
The hardest markets to trade are the most valuable to simulate. Sentiment-dependent markets are underserved by existing tools precisely because they're hard to model. That's the edge.
Integration engineering dominates. Getting OpenAI Agents SDK, MiroFish, Neo4j, TRIBE v2, Polymarket APIs, SQLite, Vue.js, and D3 to work together smoothly was harder than any individual component.
Prediction markets need behavioral tools, not just financial tools. The Polymarket ecosystem is full of price charts and order book visualizers. What's missing is tools that help traders reason about the human dynamics that drive prices in sentiment-dependent markets. That's the gap Neuro-Trade fills.
What's Next
- fMRI-RAG Emotion Mapping — Replace raw neural state injection with retrieval-based emotion profiling using the Stanford SEND dataset as a reference database, avoiding the neuroscience pitfall of naive reverse inference
- Brain Activity Visualization — Cortical heatmaps and emotion distributions in the Y.com sidebar, showing which brain regions are "lighting up" across the simulation population
- Benchmarking Against Reality — Validate simulation predictions against real-world sentiment data (TED-S dataset, USA Today Ad Meter) to prove neurological grounding improves accuracy
- Multi-Market Correlation — Simulate how sentiment in one market (e.g., "TikTok ban") cascades into related markets (e.g., "Meta stock price", "ByteDance valuation")



Log in or sign up for Devpost to join the conversation.