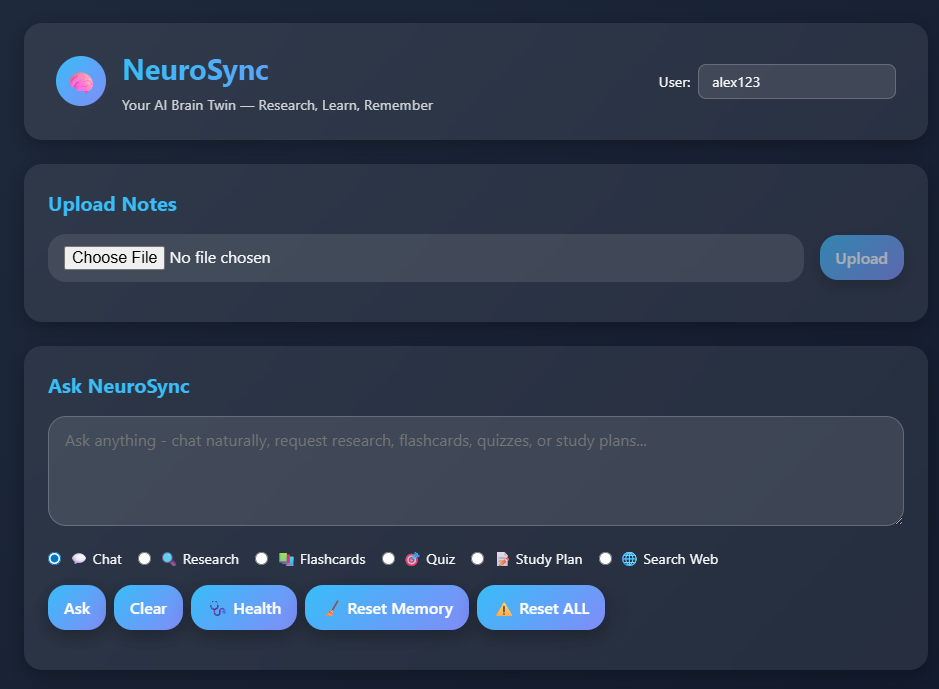
Inspiration
We were inspired by the fundamental limitations of human memory and the fragmented nature of modern learning. Despite living in an information-rich era, we constantly face:
The forgetting curve: We lose approximately 50% of new information within hours of learning
Knowledge fragmentation: Our learning is scattered across notes, books, apps, and digital files with no central intelligence
Research overhead: Every new topic requires starting from scratch, even if we've studied related concepts before
Stateless AI: Current AI tools treat each conversation as independent, forgetting everything about you and your knowledge base
We imagined: What if you had an AI twin that grew with you? A persistent companion that remembers everything you learn, connects concepts across time, and evolves as you evolve. That's NeuroSync.
What it does
NeuroSync is your lifelong AI memory companion that:
🧠 Remembers Everything: Stores and recalls every conversation, uploaded file, and research session
🔗 Connects Knowledge: Builds semantic relationships between concepts across your entire learning journey
🔍 Researches in Real-Time: Augments your existing knowledge with current web information and Wikipedia
📊 Visualizes Understanding: Displays your knowledge as an interactive, explorable memory graph
🎓 Adapts to Your Learning: Provides flashcards, quizzes, and study plans based on your accumulated knowledge
💬 Maintains Context: Engages in natural conversations while remembering your entire history
How we built it
Frontend: React + Vis.js + Custom CSS Backend: FastAPI + Python + Uvicorn AI Pipeline: Google Gemini 2.5 Flash + Sentence Transformers Memory Storage: Pinecone Vector Database Real-time Research: Wikipedia API + DuckDuckGo Search File Processing: PyPDF + Image Analysis Key Technical Components:
Memory Ingestion Engine
Chunks and embeds text/PDFs/images into 384D vector space
Smart paragraph segmentation with noise filtering
Multi-modal content processing (text, PDF, images)
Real-time Research Layer
Dual-source research (Wikipedia + Web Search)
Context-aware query augmentation
Fallback mechanisms for robust information retrieval
Conversational Memory System
Persistent chat history with vector-based recall
Context window management
Personality-consistent responses
Interactive Knowledge Graph
Real-time graph rendering with Vis.js
Context menu operations (quiz, delete, explore)
Dynamic node creation and relationship mapping
Challenges we ran into
- Memory-Research Integration
Finding the optimal balance between recalling personal knowledge and fetching new information without overwhelming context windows or creating response conflicts.
- Vector Database Optimization
Ensuring efficient similarity search across thousands of memory embeddings while maintaining sub-second response times and handling concurrent user sessions.
- Real-time Graph Performance
Managing dynamic graph updates without browser lag, especially with complex node relationships and frequent memory additions.
- API Reliability & Fallbacks
Building robust fallback mechanisms when external APIs (Wikipedia, search) fail or return incomplete data.
- Context Management
Handling the token limitations of LLMs while maintaining rich conversational context and comprehensive memory recall.
Accomplishments that we're proud of
Technical Achievements:
Built a fully functional memory-augmented AI system in 48 hours
Created seamless integration between vector search and real-time web research
Developed an intuitive visual interface for complex knowledge relationships
Implemented robust error handling and user-friendly fallbacks
User Experience Wins:
Zero-learning-curve interface that feels instantly familiar
Natural conversation flow that remembers everything
Meaningful visual feedback through the interactive memory graph
Multiple interaction modes catering to different learning styles
Innovation Highlights:
True persistent memory that grows with the user
Automatic knowledge gap identification and filling
Multi-modal content understanding (text + images + research)
Real-time knowledge visualization
What we learned
Technical Insights:
Vector databases require careful dimensionality and similarity metric selection
LLM context windows demand strategic prompt engineering and memory prioritization
Real-time graph visualization benefits from incremental updates rather than full re-renders
Hybrid search strategies (vector + keyword) often outperform single-approach systems
Product Insights:
Users value "memory" more when they can visually see their knowledge growing
The ability to have natural conversations without "uploading first" is crucial for adoption
Learning tools (flashcards, quizzes) are significantly more valuable when personalized to existing knowledge
Visual feedback on AI "thinking" and "researching" dramatically improves perceived intelligence
Team Insights:
Clear separation of concerns between memory, research, and conversation layers enables faster iteration
User testing early reveals critical workflow gaps that technical demos miss
Balancing feature richness with interface simplicity is an ongoing challenge
What's next for NeuroSync
Short-term (Next 3 Months):
Mobile app with offline capability
Voice interface for natural conversations
Collaborative memory spaces for study groups
Advanced graph analytics showing knowledge growth over time
Medium-term (Next 6 Months):
Multi-modal memory (audio notes, video summaries)
Automated knowledge gap detection and proactive learning suggestions
Integration with popular learning platforms (Coursera, Khan Academy)
Advanced research capabilities with academic paper analysis
Long-term Vision:
Predictive learning paths based on career goals
Cross-user knowledge sharing (anonymized insights)
AR/VR integration for immersive learning experiences
Enterprise version for organizational knowledge management
Core Philosophy:
We believe learning should be continuous, connected, and cumulative. NeuroSync represents the next evolution of personal AI - not as a tool you use, but as a companion that grows with you, ensuring that no insight is ever lost and every piece of knowledge builds toward greater understanding.
Built With
- amazon-web-services
- apis
- architecture
- async
- await
- base64
- build
- bundling
- chunking
- cloud
- compilation
- components
- context
- cors
- css
- dark
- database
- debugging
- dependencies
- deployment
- development
- documentation
- download
- duckduckgo
- embeddings
- endpoints
- engineering
- environment
- error
- events
- exports
- fallbacks
- fastapi
- fetch
- filesystem
- gemini
- glassmorphism
- gradients
- graphs
- handling
- hooks
- hosting
- imports
- integration
- javascript
- json
- libraries
- limits
- logging
- management
- memory
- middleware
- modular
- modules
- monitoring
- network
- optimization
- packages
- performance
- pinecone
- prompt
- props
- pydantic
- pypdf
- python
- react
- real-time
- recall
- research
- restful
- routing
- safety
- scaling
- search
- semantic
- serverless
- similarity
- state
- streaming
- testing
- theme
- tokens
- tools
- transformers
- transpilation
- types
- typescript
- upload
- uvicorn
- validation
- variables
- vector
- visualization
- websockets
- wikipedia



Log in or sign up for Devpost to join the conversation.