-
-
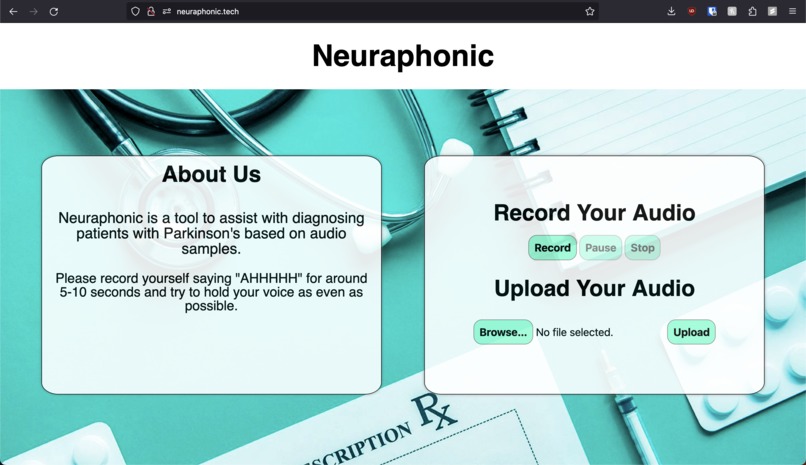
Neuraphonic Home Page
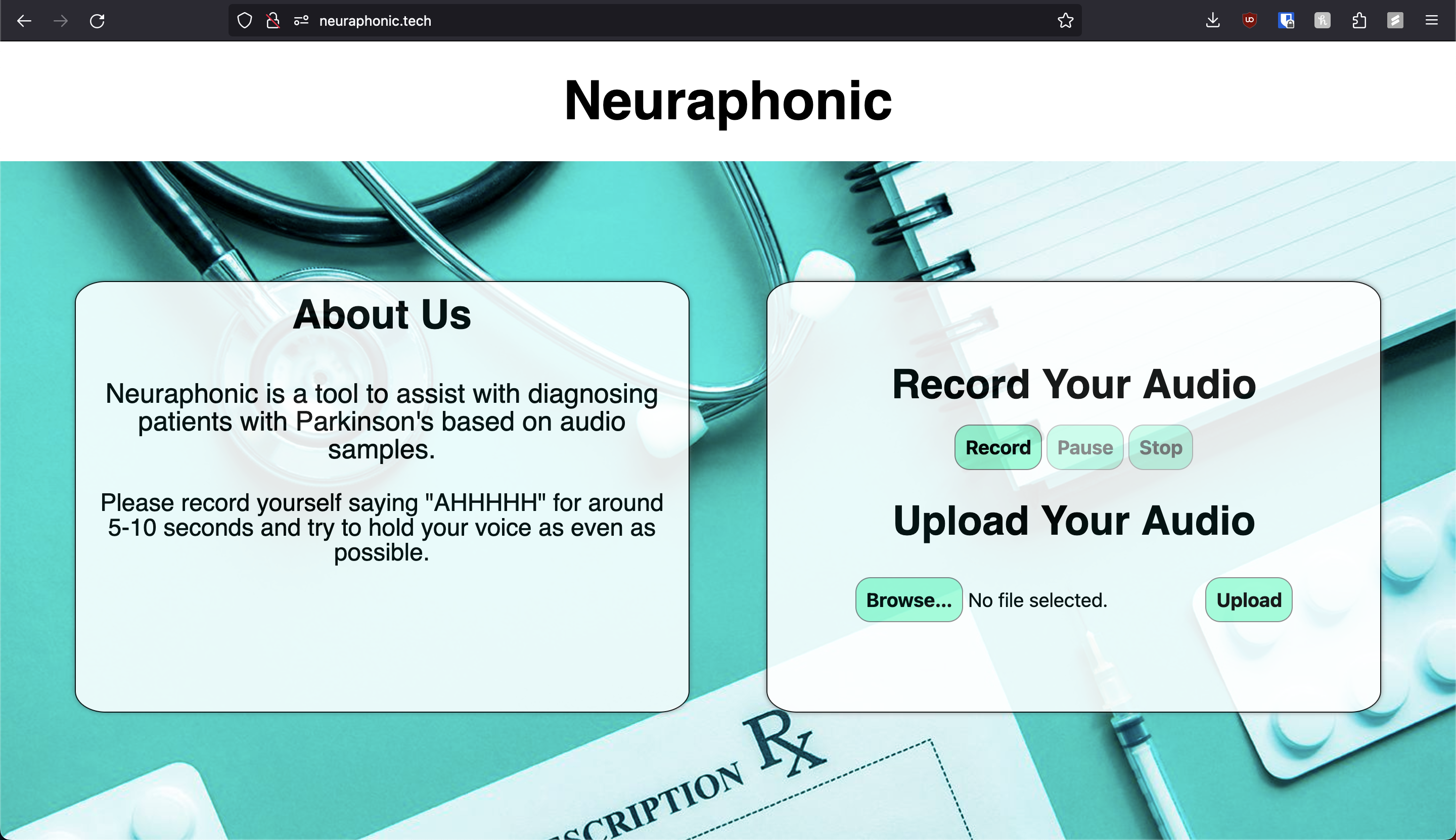
Neuraphonic
Inspiration
Diagnoses for neurological disorders are riddled with delays, high costs, and unintuitive instructions for people that are most vulnerable. Specifically, we've found that Parkinson's Disease diagnoses are highly expensive and lengthy, and may not always be necessary for everyone who fears that they have Parkinson's. Furthermore, GP (general practice) centers in the US and EU have been backed up due to many patients' speculation on having Parkinson's. Thus, we built Neuraphonic to act as a middleman on the road to a Parkinson's diagnosis; it can serve as a first test to see if a patient should seek further testing for Parkinson's Disease.
What it does
Neuraphonic is a voice sample based Parkinson's Disease predictor. The system is sent an audio sample via phone call or web upload, and the custom-built two staged audio processing pipeline interprets the audio signal and detects features in the signal that may signify Parkinson's Disease.
How we built it
The core of Neuraphonic's web interface is a Flask application deployed on Google Cloud and hosted via .tech's hosting service. The Flask application has a record and upload interface to allow the user to record a voice sample, or upload one of their own. Once the voice sample is recorded it is sent to the execution pipeline, which contains a signal processing pipeline and an ensemble model.
The signal processing pipeline decomposes the audio file into an image representation, as well as a tabular representation of its key features and metrics. The signal processing pipeline was prototyped in MATLAB, and was later deployed using the Praat Algorithm in Python.
The image and the tabular representation are sent into the ensemble model, that sends the image into a fine-tuned Vision Transformer (ViT) model, and the tabular representation into a Random Forest. The two models execute independently, and their results are probabilistically interpolated and sent as a majority-rules vote. The Flask application receives the response via an HTTP endpoint, and formats it into a user-friendly format, which is displayed to the user, along with actionable feedback.
The model is stored in a Google Cloud Storage bucket, which is a long-term persistent storage region to store the pre-trained Vision Transformer and Random Forest model.
To allow for greater accessibility for patients, we implemented phone-call API through the Twilio API. This allows for patients to call a specified phone number and have their voice be recorded and told over the phone on their chances of having Parkinson's. This may be easier for elderly patients than visting an unfamiliar website. The Twilio API is done through attaching webhooks to our webapp and linking it to a specified Twilio phone number. Once the phone number is called, the Twilio webhooks execute, record the audio, and then run it through the same ML model as the website to get the final results for the patient.
Challenges we ran into
One of the biggest challenges we ran into was deploying the system on Google Cloud, as its storage and compute limitations were rather significant, so we had to rework the way we trained, stored, and executed the machine learning models to ensure they could fit in Google Cloud's limitations. These limitations were significantly outweighed by the benefits of Google Cloud, which included the ability to universally deploy our model. Implementing the phone call API was also very difficult as none of us had worked with anything similar before and most of the available solutions (including Twilio) were intended for enterprise customers.
In addition, due to the limitations of only being able to train the model in 36 hours, we could not gather as large a dataset as we would have liked to ensure the model did not overfit on specific types of microphones or audio formats.
Accomplishments that we're proud of
We had three major accomplishments that we were proud of: training a Vision Transformer completely, implementing various famous Signal Processing algorithms by hand, and successfully deploying the model to Google Cloud and having it universally work. These were three major challenges that had troubled us in previous projects, and overcoming these difficulties was very satisfying. Additionally, we were very happy to get the phone call API working at a basic level.
What we learned
This project involved a wide variety of technologies that we had minimal to no experience in, including signal processing algorithms in python, Transformers, Google Cloud deploying, security, and backend routing.
What's next for Neuraphonic
- Make the phone call interface more robust - ensure the same information that is conveyed on the website is conveyed via phone call.
- Establish an SSL certificate so that the Neuraphonic website uses HTTPS instead of HTTP. Once established, the user can record their voice in real time and send their voice for processing instead of pre-recording a file.
- Our datasets are comparatively small for the sheer size of the models, and because we only had 36 hours on limited hardware, we could not train the model to the extent we desired. With more time, we would significantly optimize the models and perhaps use it for multi-class classification.
- As the target audience of this feature is people who may need accessibility features, we plan to add significant accessibility improvements to the website.
Built With
- css
- deep-learning
- flask
- google-cloud
- harmonic-analysis
- html
- machine-learning
- matlab
- praat
- python
- pytorch
- random-forest
- signal-processing
- sklearn
- transformers
- twilio








Log in or sign up for Devpost to join the conversation.