-
image
Inspiration
A couple weeks prior to CitrusHack, some of our team participated in a dungeons and dragons game. After seeing the tracks released for citrus hack, it was only natural that a topic involving new technology, primarily generative AI models, came up. As such, we wanted to make a project that could bring this technology together with some of our hobbies: stories and games.
What it does
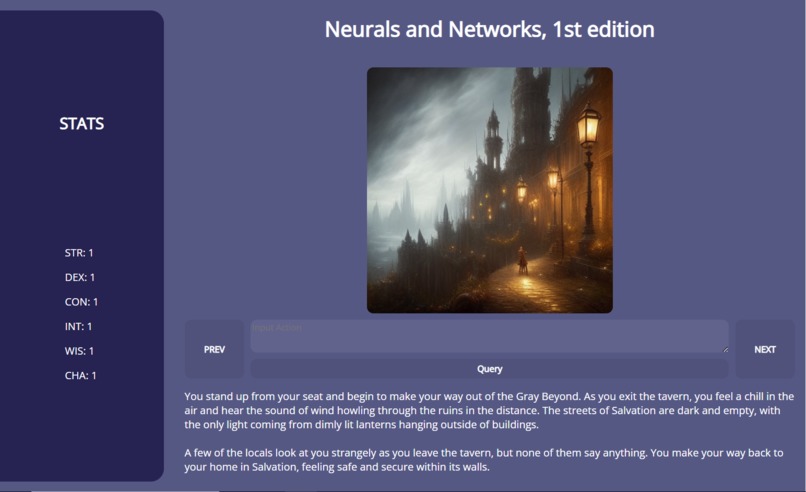
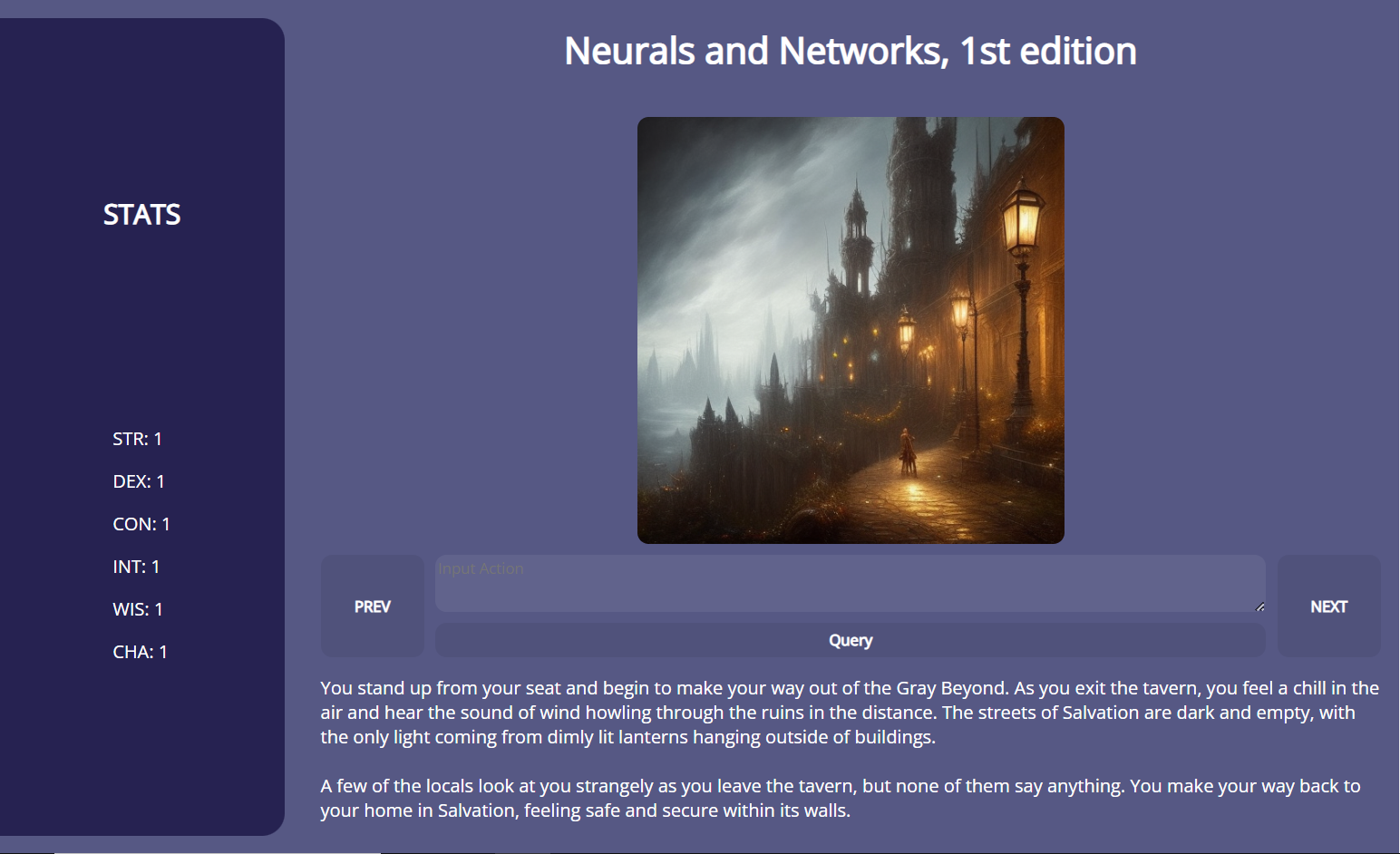
Neurals & Networks is a framework that uses a series of generative AI models (both natural language and image generation) in order to provide an immersive and reactive storytelling experience for the player, all in real time. Neurals & Networks has the ability to generate a story and images to back it up.
No more choosing from a set of options, or being limited by the creativity of the developers. Neurals & Networks gives the freedom of choice directly into the hands of the player. The world is shaped by the choices that the player makes, and they can see it directly reflected in not only the text narrative, but also the generated images.
How we built it
Neurals & Networks is built on a python backend, which networks our models together, and a javascript-css-html frontend that allowed us to create a user-friendly interface. We started off by testing the AI models separately in order to make sure they fit our standards. After verifying that, we networked them together to generate image generation prompts using our natural language model. Finally, we implemented all this into a client-server model to allow connected clients to request narration and images.
Challenges we ran into
The product journey we embarked on today was filled with ups and downs, and we managed to have a lot of fun when we let other hackers try out our product. We’ll go over a couple of things we were challenged by.
- NLP/Gen Limitations: When considering a storytelling AI, one of the primary concerns is continuity. In the beginning, we struggled to make the model provide continuous output that would make logical sense when chained together with previous prompts and outputs. In the end, with some prompt engineering and output history moderation, we were able to extend the duration of continuity to an appropriate amount.
We learned that while the models can be very powerful, they also have many weaknesses that need to be accounted for. (Touched on later)
- Stable Diffusion Prompts: In order to get our image generation model to work properly, we had to get the language model to generate prompts that would allow for a descriptive image to be generated.
One of the reasons this is a major challenge is that language models work with text data and lack a direct link from text to visual data. The language model needs to be able to generate a description that is both precise and informative in a way that the image model can parse effectively.
Request Length Limits: When making API calls to the model, we got capped on our maximum character/word count when reaching around 20 to 30 posts, so we had to trim the output to allow for the model to keep generating without problems.
API Rate-Limits: When we were testing our API calls for the natural language model, we exceeded the maximum rate of calls many times, and were strongly inhibited by it. However, we switched to a similar alternate model to continue testing.
Formatting the Output: Sometimes, it can be difficult to get the language model to cooperate with your formatting needs. It took a lot of work to engineer a precise prompt that would almost always generate the correctly formatted output.
Testing is Hard!: Not a lot of the system testing could be automated, since this is a user-oriented system that relies almost solely on user input to function. This meant that our team had to spend an inordinate amount of time testing.
Making a Nice Website: We found that after having our initial demo site set up, it was difficult to convert it into a more professional and modern aesthetic. We decided to keep the site simple for the demo.
Accomplishments that we're proud of
Throughout the development of our product, we hit a couple of key milestones that I’d say we’re proud to have made.
Categorizing Results
In order to make the outcome decision-making of the language model more standardized, we created a prompt that would allow us to get well-formatted and responses that could be parsed with string processing to get a value we could digitally work with.
Processing Using Language Model
One of the key factors in our success of creating an event-success system using the language model was taking output from the model, and feeding it into another ‘thread’ or ‘convo’ of the model in order to process the output for a more programmatic response.
Conversation History Manipulation
We used specific prompt suffix/prefixes to help guide the language model, but this would make the conversation history very long (running into the size limit issue). Since using the API would always ask for the entire conversation for the model to then respond to, we could remove the prompt suffix/prefix from previous messages and only on the most recent to reduce duplicate text, reducing overall conversation length.
Chaining Together Prompts
While we originally had a many-stage prompt processing pipeline for player input, we switched over to a more compressed two-stage processing pipeline, which first determines if the player is conducting an action, and then decides the outcome of the action. Overall, we streamlined the process to cut down on API calls and generation time.
Built With
- ai
- css
- html
- javascript
- natural-language-processing
- python
- scrum
- stable-diffusion




Log in or sign up for Devpost to join the conversation.