-
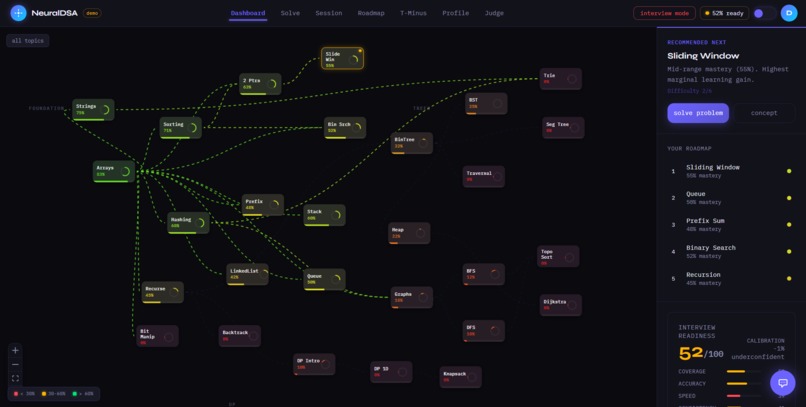
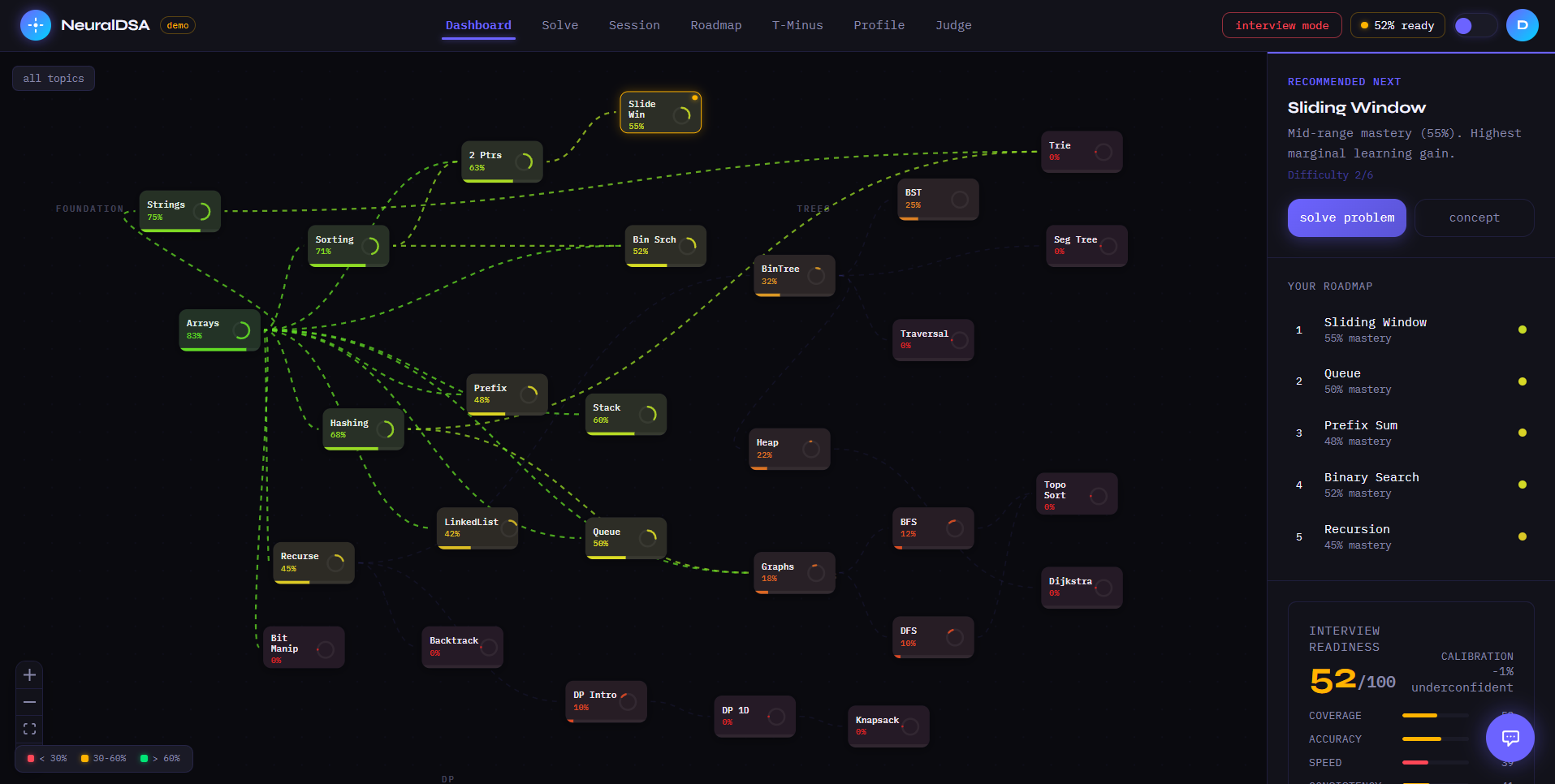
home page with main graph view
-
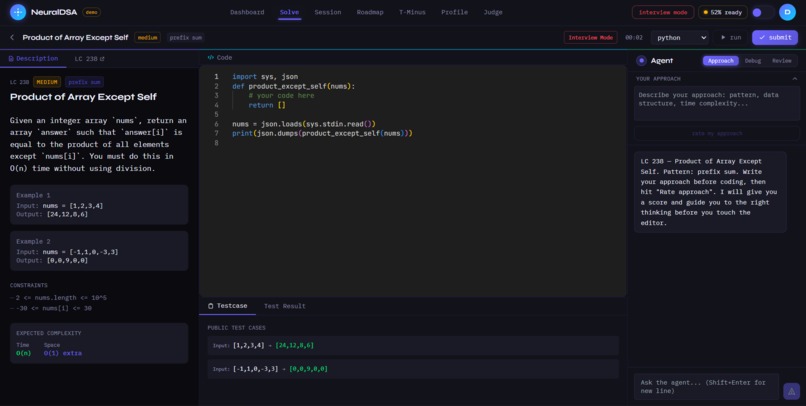
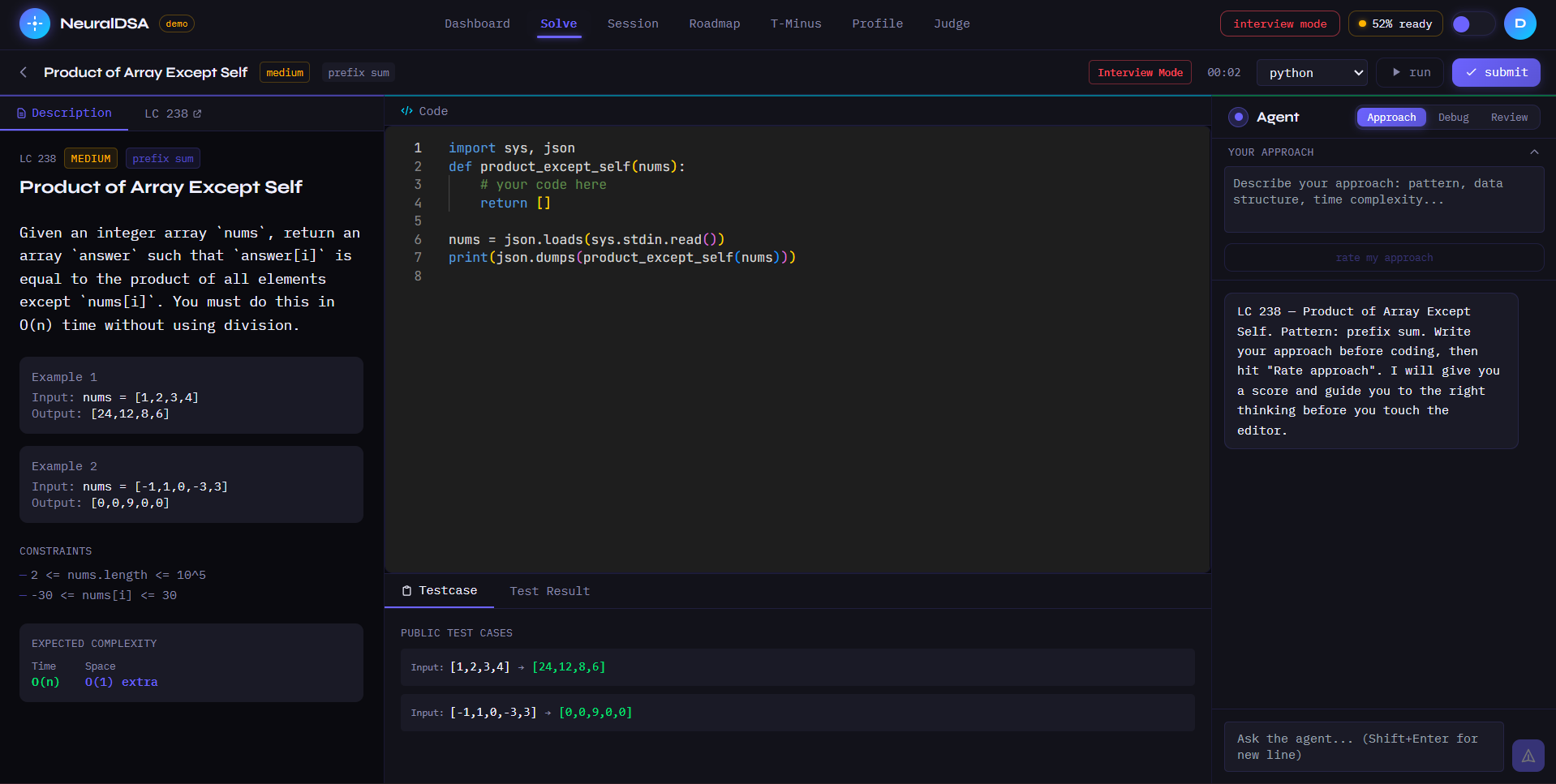
solve page with agent
-
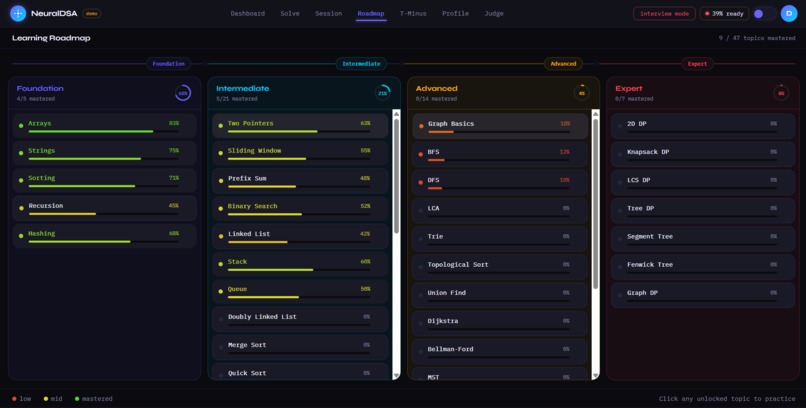
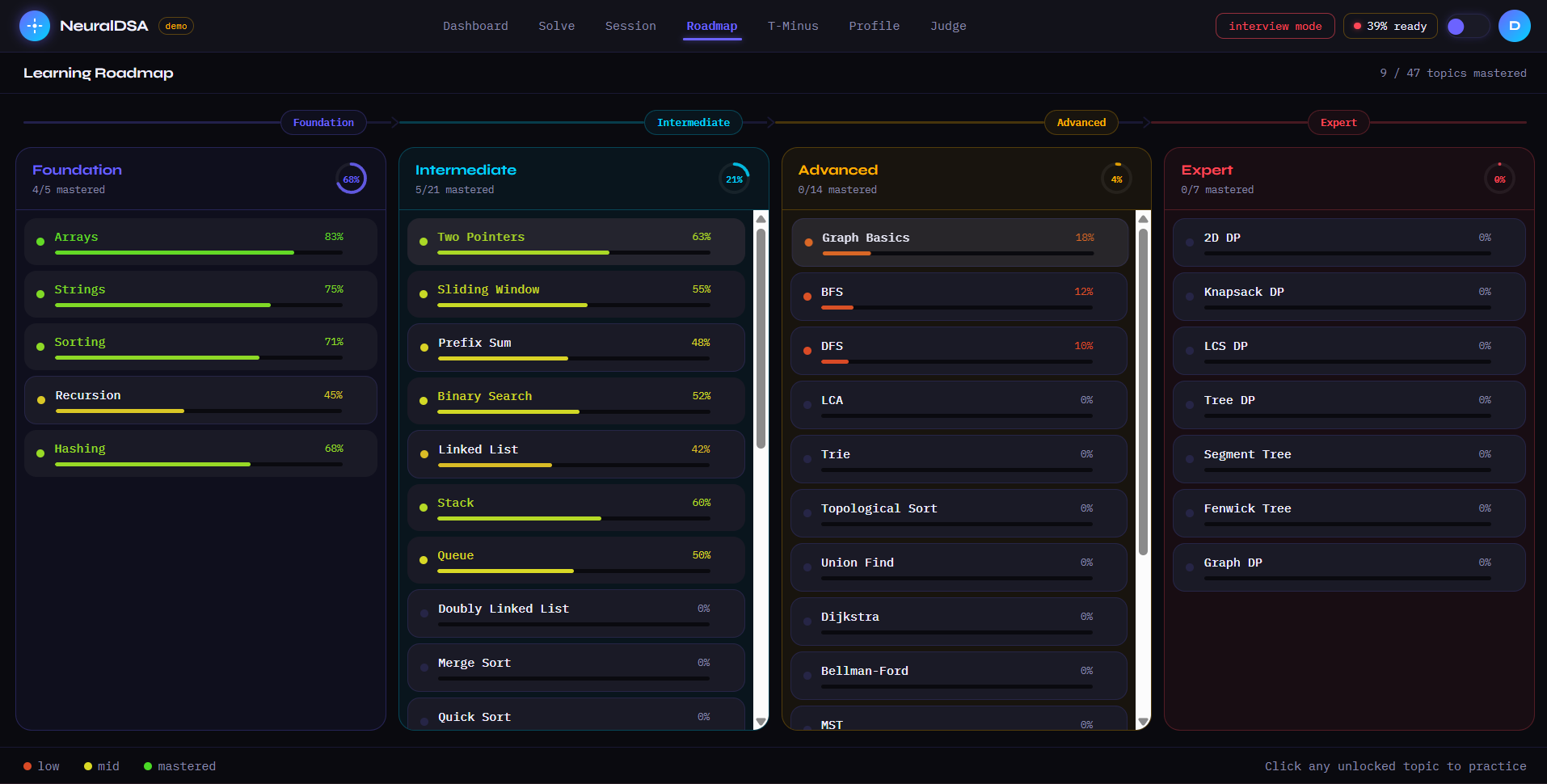
roadmap page with execution
-
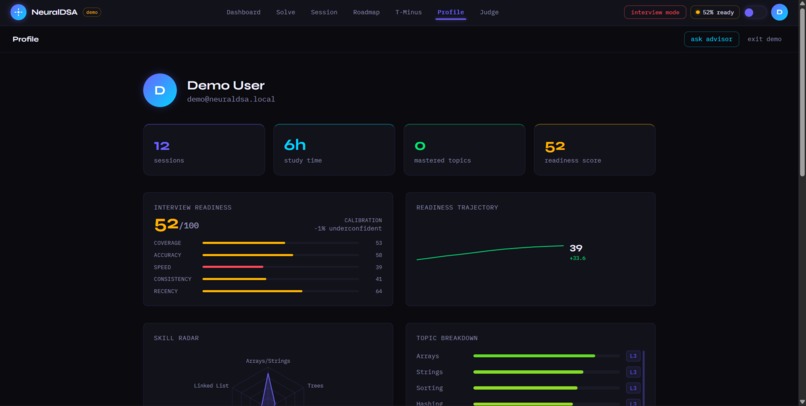
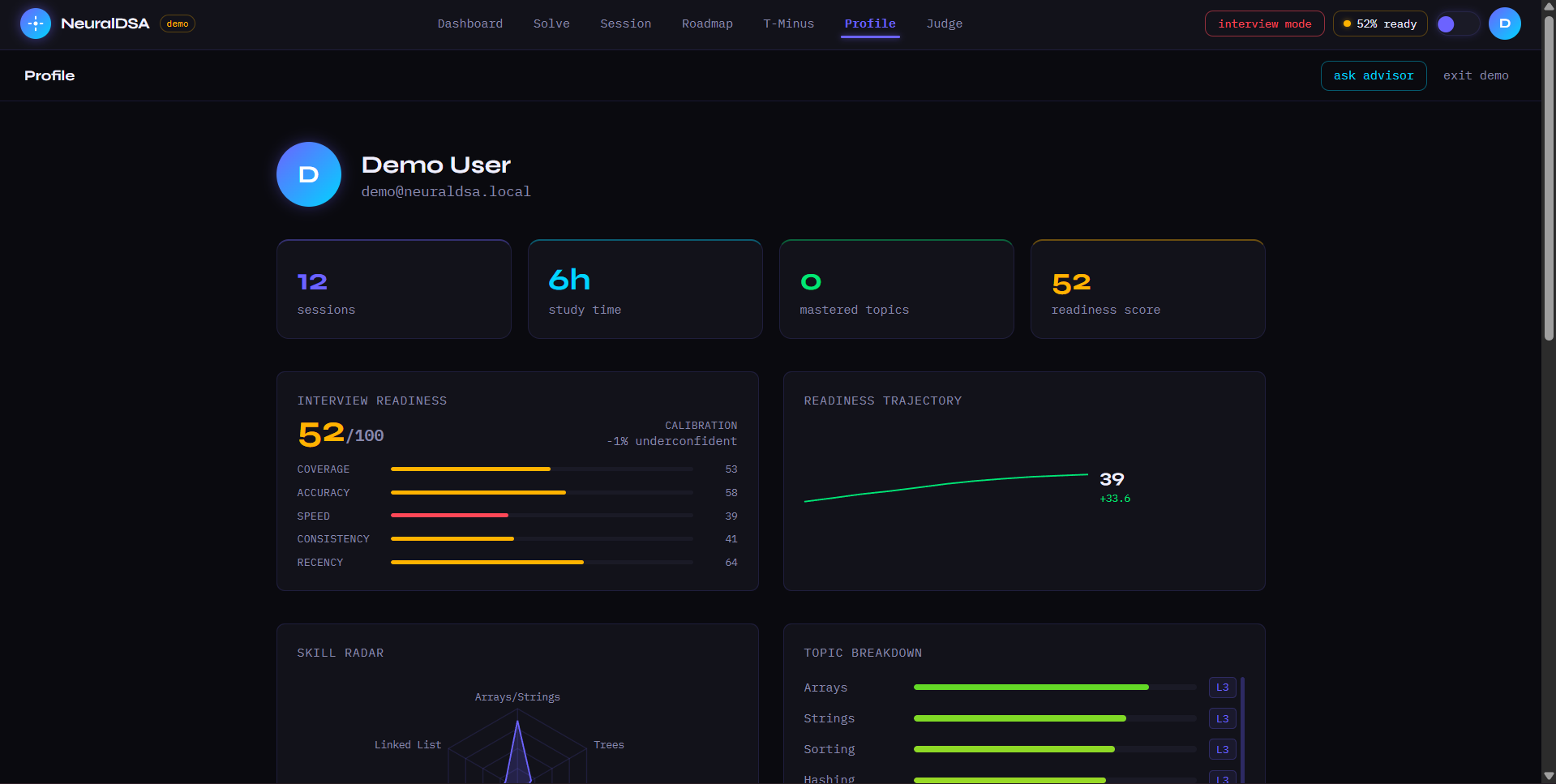
profile page with insights
Inspiration
Every one of us has been through placement season. You grind 300 LeetCode problems, feel ready, then freeze on a medium problem you've technically solved before — not from lack of effort, but lack of the right feedback. We watched brilliant friends fail top-company interviews not because they didn't know the algorithm, but because no tool ever diagnosed why they kept failing the same way. That gap is what we built NeuralDSA to close.
What it does
NeuralDSA is an autonomous AI agent that models how you think — not just what you answer. Every learner gets a 5-Dimensional Brain Model tracking Knowledge, Speed, Confidence, Consistency, and Pattern Recognition, updated after every interaction. The agent runs a continuous OBSERVE → UPDATE → REASON → ACT loop, choosing from 8 coaching decisions based on your live cognitive state. Three features nobody else has: T-Minus Protocol tells you exactly what to study 48 hours before your interview. Cognitive Autopsy pinpoints which cognitive layer broke when you failed — not just that you failed. Interviewer Perception Engine scores how an interviewer would perceive you, independent of code correctness.
How we built it
React + TypeScript frontend with Monaco Editor and D3 knowledge graph visualization. Python FastAPI backend with WebSocket for real-time agent streaming. Firebase Auth and Firestore for persistence. Judge0 for sandboxed code execution. Claude/Gemini with a provider abstraction layer for LLM inference. The agent loop runs a full reasoning cycle after every interaction — structured JSON evaluation payloads streamed over WebSocket with normalization and fallback logic for every path. Deployed on Docker + Nginx.
Challenges we ran into
Getting the LLM to reason about learner state rather than follow a decision tree required careful prompt engineering and multiple fallback layers. Measuring genuine hesitation in a browser — distinguishing "thinking" from "stuck" from "confident" using only timing signals — took significant iteration. Streaming structured JSON evaluation payloads over WebSocket without silent failures when LLM output was malformed was unglamorous but essential work. Solving the cold start problem — seeding a meaningful brain model in the first 5 minutes with no history — without making it feel like a test.
Accomplishments that we're proud of
Building an agent that genuinely reasons about a learner rather than reacting to their last answer. The T-Minus Protocol — no tool has ever told a student what to study the night before their interview with this level of specificity. The Cognitive Autopsy decomposing failures across 5 cognitive layers and prescribing targeted fixes rather than more of the same practice. Getting real-time LLM evaluation, WebSocket streaming, sandboxed code execution, and a live-updating brain model working end to end under hackathon conditions.
What we learned
Interview failure is almost never a knowledge problem — it's a diagnostic problem. Students get the wrong feedback, apply the wrong fix, and fail again. We learned that hesitation time is a stronger signal of surface knowledge than correctness alone, that the confidence calibration gap is more predictive of interview failure than raw mastery score, and that error classification matters far more than error detection . Knowing a student got something wrong is useless. Knowing they have pattern overfitting vs. complexity confusion vs. code translation breakdown — that's actionable.
What's next for NeuralDSA
Expanding the problem catalog to full FAANG interview pattern coverage. Company-specific curriculum — the agent should know that LinkedIn asks sliding window and graphs in 73% of rounds. Voice-based thought trace so the agent can evaluate verbal communication in real time. An institution dashboard so colleges can see aggregate misconception patterns across cohorts and intervene at scale.
Built With
- agents
- amazon-web-services
- bedrock
- d3.js
- docker
- fastapi
- javascript-frameworks-&-libraries-fastapi
- languages-react
- llama
- monaco
- ngnix
- python
- react
- typescript




Log in or sign up for Devpost to join the conversation.