Neural Network From Scratch
Modern AI frameworks abstract away the learning process behind a few lines of code.
!While powerful, this abstraction often hides why neural networks work. The inspiration for this project came from a simple question: “Do I really understand what happens inside a neural network when it learns?” This project was an attempt to answer that question by building a neural network from first principles, aligned with the spirit of Build From Scratch — Season I.
What it does
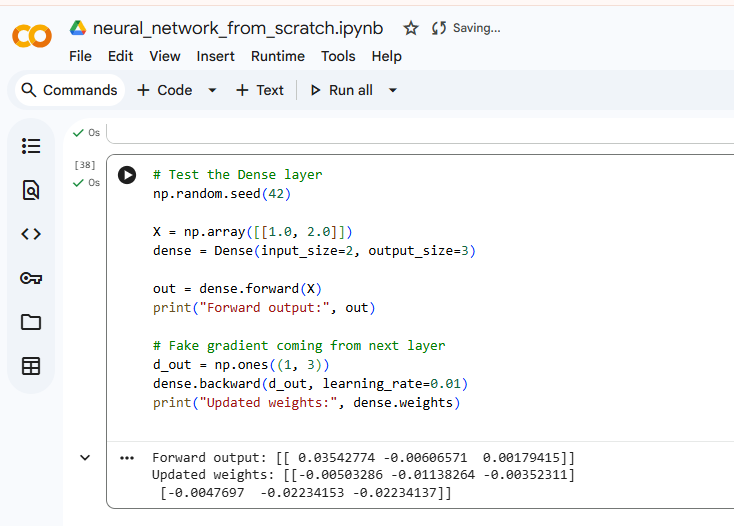
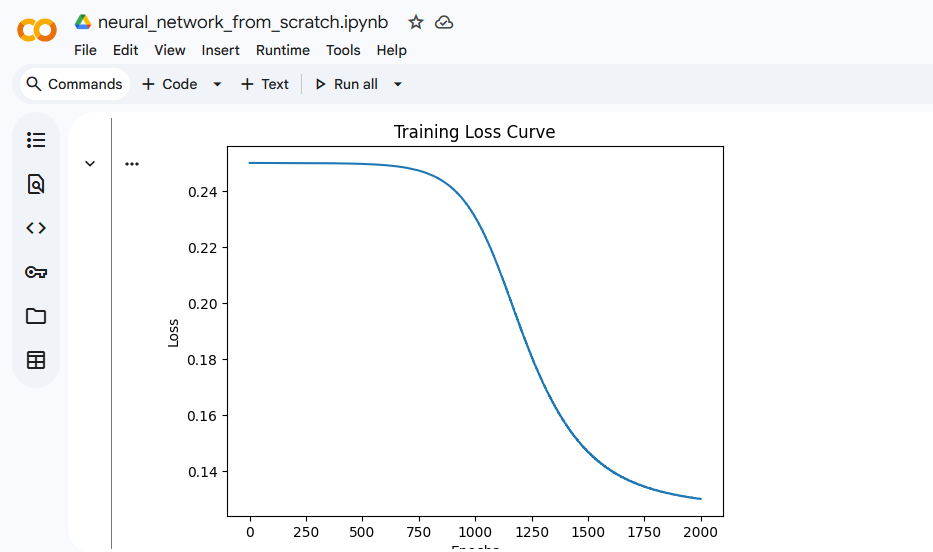
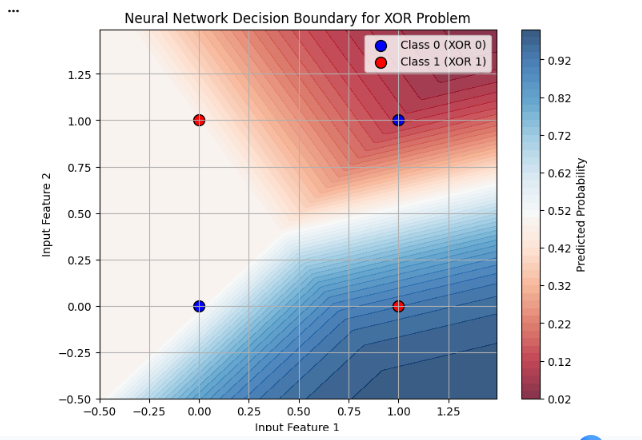
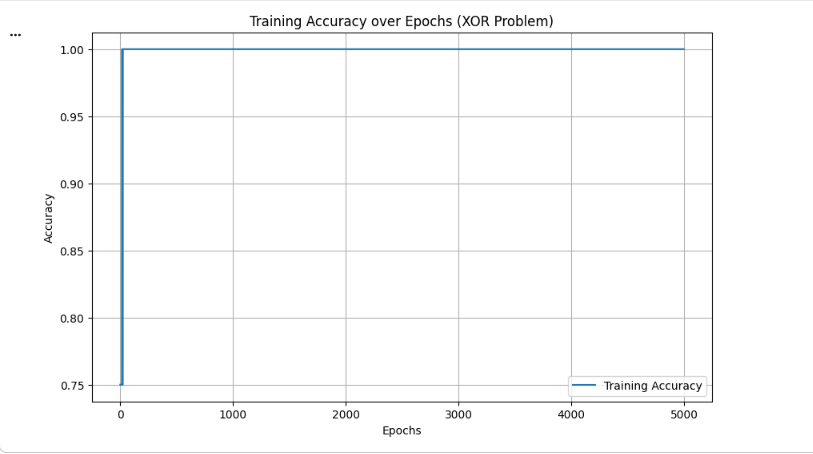
!This project is a from-scratch implementation of a neural network, built using only core programming fundamentals in Python and NumPy. The goal was not to achieve state-of-the-art accuracy, but to deeply understand how neural networks work internally by implementing every component manually — from forward propagation to backpropagation and optimization. Unlike typical ML projects that rely on high-level frameworks, this system exposes the mechanics behind modern deep learning models. The neural network is a feed-forward model trained using gradient descent and backpropagation. Input (2) ↓ Dense Layer (2 → 4) ↓ ReLU Activation ↓ Dense Layer (4 → 1) ↓ Sigmoid Activation ↓ Output
Implementing correct gradient calculations without automatic differentiation
!Managing tensor shapes across layers Debugging exploding or vanishing gradients Ensuring numerical stability in the sigmoid function Designing clean, extensible abstractions Each issue required careful reasoning and step-by-step debugging, reinforcing core ML concepts.
Building a complete neural network engine from scratch
!Using zero machine learning frameworks Successfully training on a non-linear dataset Writing clean, modular, and reusable code Achieving full transparency and reproducibility
What we learned
!This project significantly strengthened my understanding of: Backpropagation and gradient flow Why activation functions are essential How optimization drives learning The difference between using ML tools and building ML systems Most importantly, it removed the “black-box” feeling around neural networks.
Future improvements include:
!Implementing Softmax and Cross-Entropy loss Adding advanced optimizers (Momentum, Adam) Supporting mini-batch training Building a lightweight automatic differentiation engine Extending to multi-class classification problems



Log in or sign up for Devpost to join the conversation.