
Neural Ordinary Differential Equations for Web Traffic Data
Introduction
Neural ODEs are a new family of deep neural network models that have proven to be effective in analyzing time series data. Their relatively recent emergence (with the first paper only being published in 2018) makes them the perfect candidate for a novel solution. Forecasting the future values of multiple time series has always been one of the most challenging problems in the field so we propose the utilization of Neural ODEs on irregular datasets, with web traffic data being a perfect candidate for evaluation. We also introduce a novel modification of the current Neural ODE architecture, by introducing a GRU-D cell as the encoder.
Methodology
Exploratory analysis
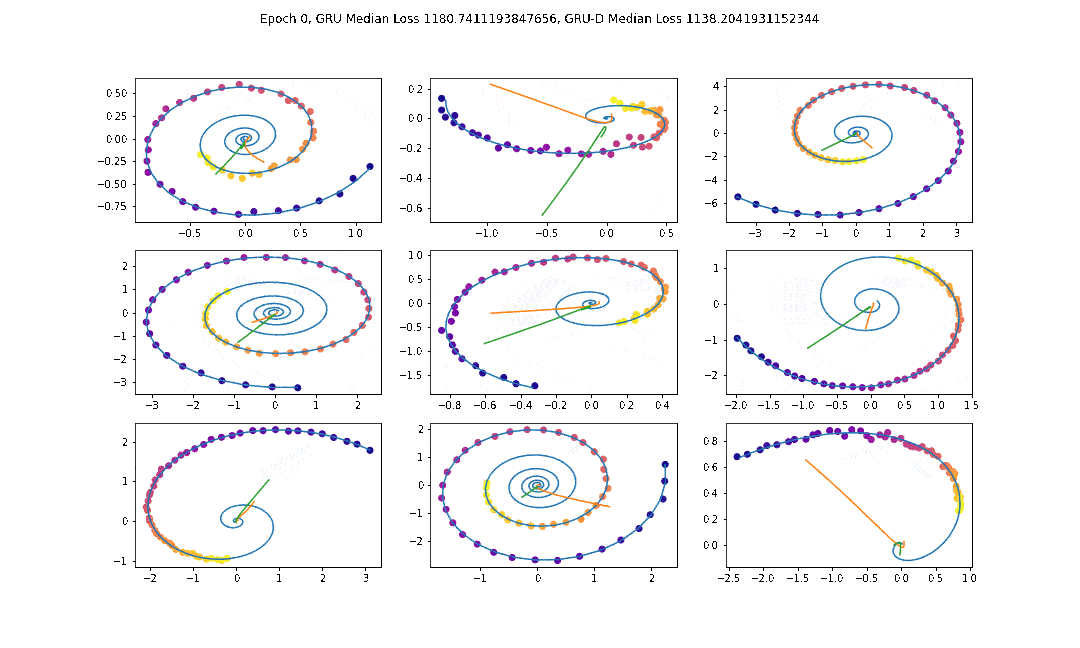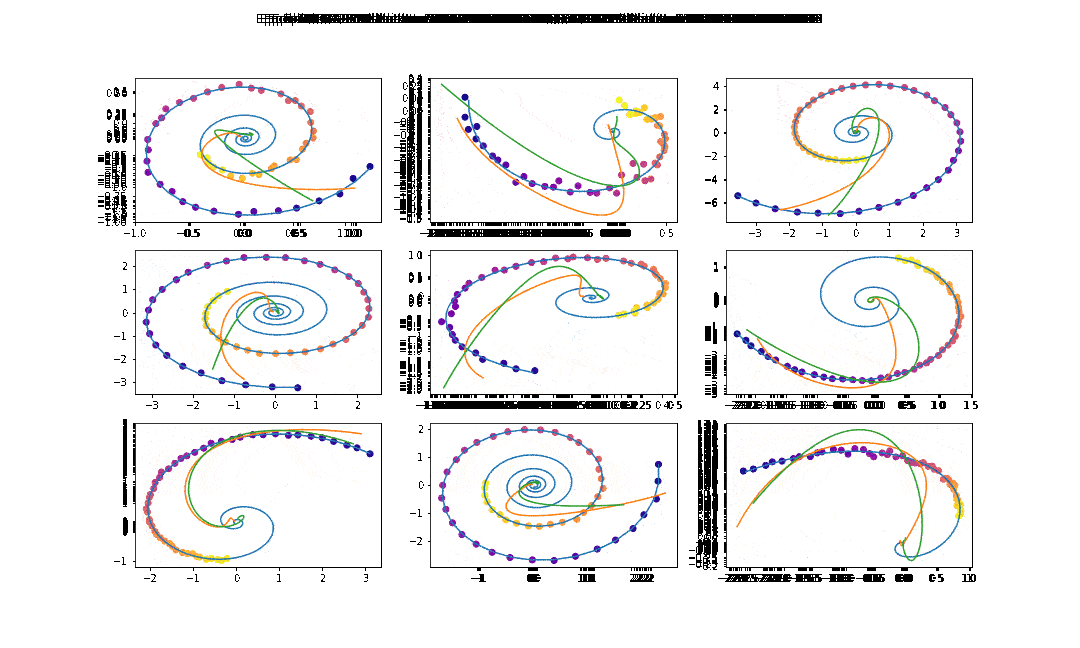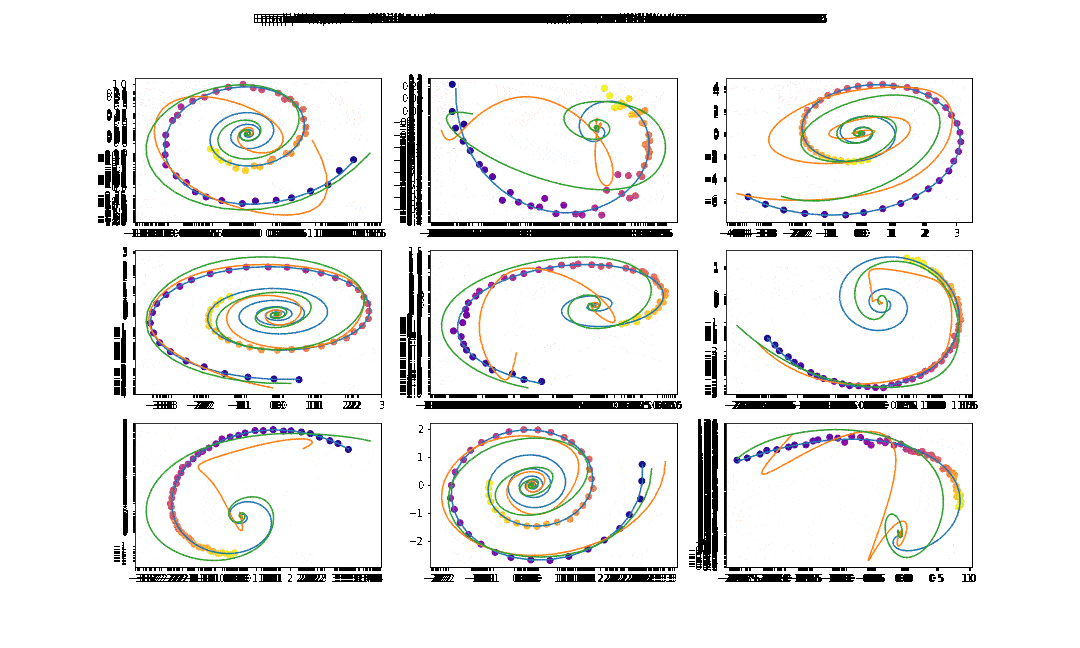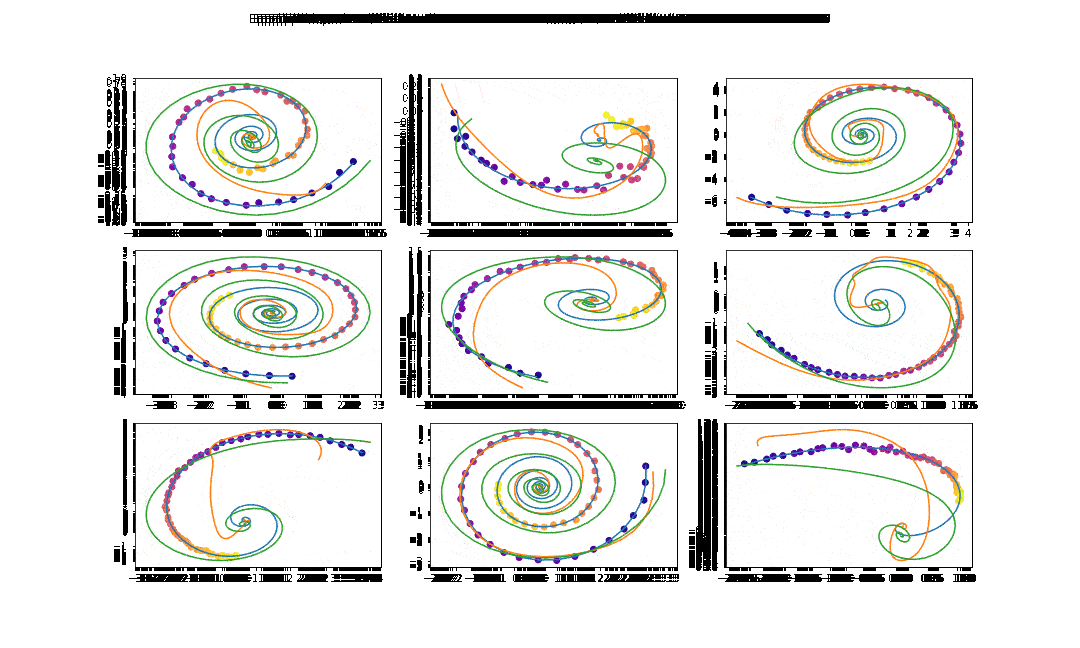
We had a myriad of options to choose from to approach the project but ultimately we chose to use Neural ODEs because Neural ODEs produce a time invariant and input adaptive evaluation method which means that for data prone to spikes and gaps, Neural ODEs should theoretically be able to perform well. Recently, Bilos et. al featured, through NeurIPS 2021, a different approach to Neural ODEs compare to the original landmark paper published by Chen et. al. The authors called their approach “Neural flows” similar in concept to the continuous normalizing flows approach. The approach learns to predict solutions rather than an encoding for the ODE itself, and is much less input adaptive as a result. It has been shown to generalize even worse than Neural ODEs, so we choose to use the original approach for our purposes. As a proof of concept we trained a Neural ODE to fit a time series which produces a spiral. The play dataset time series is imposed of t observations of (x, y) points. In 2016, Che et. al. introduced a GRU variant architecture, GRU-D, which interpolates points and the hidden state with a decay factor which is trained. We implement this model ourselves in pytorch and show through the test dataset that it is also effective, and in some cases much more effective than just the GRU at fitting the data.
Data Preprocessing
The training data was readily available using the Kaggle API and can be found at https://www.kaggle.com/c/web-traffic-time-series-forecasting/data. The data is made up of a page column, containing a concatenation of the article name, type of traffic, and crawling agents used to obtain data, as well as the number of page hits for each day between July 1st, 2015 and December 31st, 2015. Empty values are used to represent missing data (note that missing here can either mean the traffic was zero or that the data was not available for that day).
The training data consists of a total of 145,063 websites and 803 time points in total.
We first preprocess our data by converting it to a PyTorch tensor and using various methods to account for missing data. First, we remove any rows where more than 10% of the time points have missing data. This is to shrink the training dataset so that the model only trains on web traffic data with sufficient data points to allow effective fitting of an ODE.
Next, we use various interpolation methods to remove the missing time points in the remaining rows. Among the interpolation methods we used were a zero-based interpolation (each NaN value in the dataset is replaced by a 0), a median-based interpolation (each NaN value in the dataset is replaced by the median of the row), a mean-based interpolation (each NaN value in the dataset is replaced by the mean of the row), and a mean-based interpolation with noise (each NaN value in the dataset is replaced by a value normally distributed around the mean of the row). For models made using a GRU-D, we don't perform any of the above interpolations and directly feed in data containing the NaN values. Among the models using the above interpolation methods, the best-performing model was obtained with a median-based interpolation. We discuss possible reasons for why this may be further below.
Model Architecture
Our final model architecture consists of a variational autoencoder, where the encoder block is a GRU-D cell and the decoder block is a latent neural ODE. The encoder block generates a latent space representation of an ODE for the time series data and the decoder block essentially integrates over this ODE to obtain a prediction for any time value given an initial time. We use a learning rate of 0.001, train on a random sampling of 200 timesteps, batch size of 1000, and the Adam optimizer.
Figure 2: General Architecture
The GRU-D cell is implemented from scratch and can be called in exactly the same way as the GRU cell. A PyTorch implementation of the GRU-D cell is given in the publicly available repository since other publicly available implementations are either buggy or hardcoded for time series classfication problems rather than time series forecasting problems. A high-level overview of a GRU vs GRU-D cell is provided below:
The latent ODE uses a Dopri 5 solver to integrate the ODE. AFter experimentation with solvers including the Euler's method, Dopri5, Dopri8, Adams Bashfroth Moulton, Midpoint, and the built-in scipy solver, we found that Dopri5 was the best. This is likely because Dopri5, Dopri8, and the built-in scipy solver are able to account for the greatest stiffness in data and thus, allow for use of higher learning rates with lower batch sizes.
Training Methods
We train by shuffling the rows in the training data to obtain a random permutation of websites for each epoch. For each row in a batch, we then sample n timepoints starting from a random date between July 1st, 2015 and December 31st, 2015. We experimented with randomly dropping timepoints to create non-continuous data but found that, while this didn't make a substantial difference for the training loss, it lead to inefficient generalization to the testing data. Additionally, it outweighed the benefits of any given interpolation method and as such, we decided to feed in continuous time data after interpolation was performed (for the GRU).
Loss Methods
Particularly difficult was finding a loss function that could be minimized. Although the test predictions are evaluated using a SMAPE loss, such a loss is difficult to optimize since the value of the function near 0 is undefined. As a result, we experimented with other loss functions including MSE, MAE, a differentiable version of SMAPE, a rounded version of SMAPE, and MAPE. Comparisons between each of these functions are shown below: Figure 4: Loss Function Comparison
We found that performing a log1p transformation on the data before applying the MAE loss function allowed us to minimize the loss function optimally. This is because a log1p transformation decreases the magnitude of the data points, allowing for more continual training of the model given data containing sudden spikes in web traffic. The MAE loss function smoothes the results at most data points, providing a similar function. Given that the MAE loss is close to the SMAPE competition loss function, it is an efficient substitute for training.
Related Work
The original paper for this work, Neural Ordinary Differential Equations (https://arxiv.org/pdf/1806.07366.pdf) lays out three main benefits of neural ODES:
- They have a constant memory cost, allowing for training of deeper models
- Adaptive computation allows for an accuracy vs. time tradeoff
- Applicable to continuously-defined dynamics
In this paper, the authors actually mention that applying traditional neural networks to irregularly-sampled data such as network traffic is difficult but that neural ODEs present a continuous-time, generative approach that may provide significant improvements. However, we have not found any papers since then that lay out the architecture of such a model and evaluate its performance against a test dataset.
Neural ODEs have successfully been applied to other time-series data though. For example, they have been used to successfully predict the weather in Delhi based only on a dataset of climate measurements over the past few years (https://sebastiancallh.github.io/post/neural-ode-weather-forecast/).
Additionally, there are numerous articles discussing potential variations on the basic neural ODE architecture described by Ricky Chen et. al in the original paper such as ODE-RNN hybrids and latent ODEs (https://proceedings.neurips.cc/paper/2019/file/42a6845a557bef704ad8ac9cb4461d43-Paper.pdf) that provide ample opportunity for fine-tuning of model parameters and potentially creation of a novel architecture specific to this problem.
The original paper for GRU-D (https://arxiv.org/pdf/1606.01865.pdf)
In this paper, the authors points out that missing time steps in temporal data would count as a valuable observation. Instead of filling in missing values, masking is used to inform the model on missing data and time intervals are used to observe input patterns. By considering these dependencies and training on all components through back propagation, using GRU-D would greatly improve the model's accuracy.
Given the existing theoretical background as well as effective, albeit limited, papers applying neural ODEs to other time-series data, this presents an exciting opportunity to explore the potential of neural ODEs with a GRU-D encoder for irregularly sampled datasets.
Initial Goals
Base Goal (SMAPE): 70.0 Target Goal (SMAPE): 40.0 Stretch Goal (SMAPE): 30.0
Ethics
Website traffic is an important indicator of the effectiveness of advertisements, social media presence, and overall business success. Being able to successfully predict web traffic may help narrow down areas for improvement and increased profitability. Thus, accurate forecasting could drastically change the way businesses operate.
Deep learning is perfect for this problem because it is a prediction task for which an abundance of training data exists. In addition, existing solutions employing RNNs and LSTMs have proven to be somewhat effective for prediction of web traffic and other time-series data.
Challenges & Insights
The point of the dataset was to try and develop a method for fitting very noisy, jagged, and irregularly sampled data. This is one of the most challenging characterizations of time series, and as a result we had to research and employ a myriad of techniques to allow our model to effectively fit and predict the data. We split up our challenges and solutions into 3 main categories: Data Processing: Since the data had many large peaks it made training impossible since the model would both attempt to fit the low average traffic and peak traffic. As a result, we initially employed outlier exclusion, but this effectively prevented the model from learning at all. We also employed average window smoothing, but this caused the same issue. As a result we chose to just log transform the input, so our model would train in log space, drastically reducing the euclidean distance between the peak and maximal value. Also, many websites had extremely large gaps in between data entries, roughly 20% of the entire time series would be NaNs in these cases, as a result, we excluded these websites from training overall, and then trained a separate model with its own weights to fit particularly on these websites. Here the GRU-D based models exceptionally outperformed the GRU models since interpolation methods effectively erased any possible trends to be extrapolated from the gaps. Interpolation methods themselves were a pitfall, initially we were not adding any random noise and as a result the models performed exceptionally well in training but had poor extrapolation performance on the test data sets. We tried different distributions, but found uniform distribution led to the best performance. We tested this by removing random points, replacing the missing points with the interpolation with different noises (Gaussian, Xaviar, Exponential, Uniform) and we found uniform produced the lowest KL-divergence.
Training: The train time was the most exceptional difficulty, since two of our group members could not run the model locally, we were limited to 6 devices counting the free GCP accounts each of us made. This meant we had to be careful about setting up and running experiments since training took roughly 4 hours. Each batch took about 10 seconds to train for GRU models and 12 seconds for GRU-D models, we used batch size = 1000, and there are roughly 144,000 websites. We also had a lot of difficulty setting up Cuda for both the GRU and GRU-D based model, so we were unable to take advantage of GPUs in our training. While the loss profile seemingly indicates convergence, the model actually becomes much more accurate even past 100 epochs. In our literature review, most experiments trained for over 1000-10,000 epochs, but this would take over 2 weeks by our calculations without Cuda, so we settled on a realistic amount of epochs for experiments and trained for a whole day for our final model which we submitted on Kaggle.
Testing: The model initially had really poor testing performance due to overfitting. Using a 10-fold cross validation to optimize hyperparameters alleviated the issue, but the most significant improvement came from implementing dropout. We suspect applying gentler smoothing techniques than average window such as Savitzky-Golay filtering would improve generalizability too.
Future Directions
In addition to considerations mentioned above such as Savitzky-Golar filtering, training for longer, and adding Cuda capabilities, we are also very interested in latent PDE generation rather than latent ODE. This is because while our system of ODEs representation does well, it fails to effectively capture relationships between websites. Intuitively it makes sense for related topics or articles in the same language to have somewhat related traffic. We theorize that making each website a dimension of a latent PDE and using PDE solving techniques could also be fruitful.
Contributors: Madhav Ramesh (mramesh5), Brian Sutioso (bsutioso), Kevin Lu (klu25), and Matthew Meeker (mmeeker1)
Video and Writeup (Google Drive Link): https://drive.google.com/drive/folders/1XOLw4jMJHxZmSMF3GRhK-jPCWCGjxUjp?usp=sharing
Built With
- python
- tensorflow








Log in or sign up for Devpost to join the conversation.