-
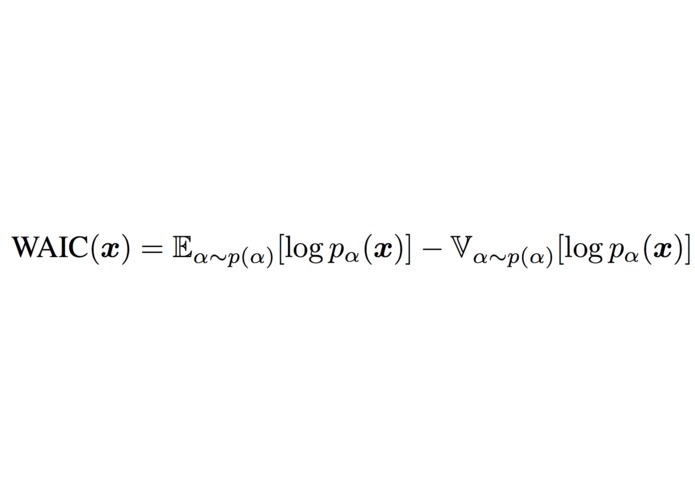
WAIC score that our model optimizes
-
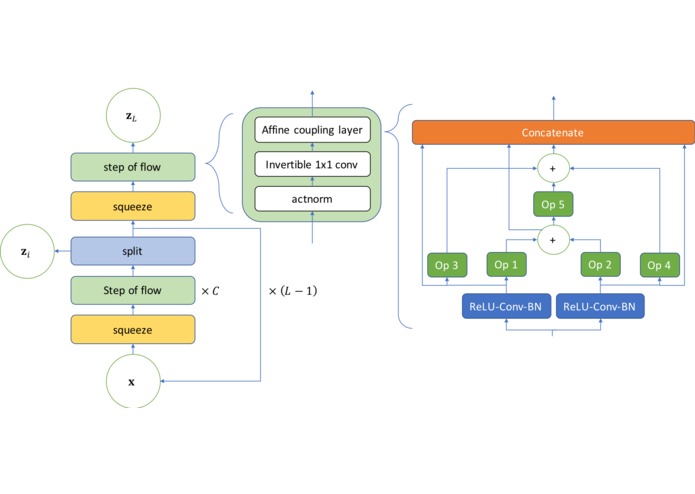
Search Space of our NAS
-
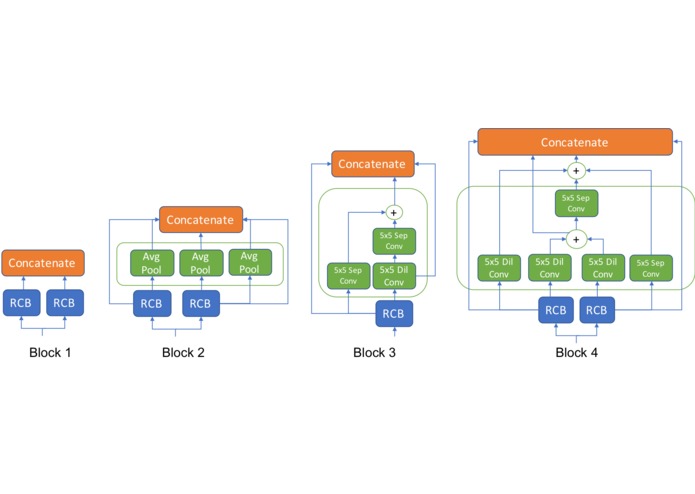
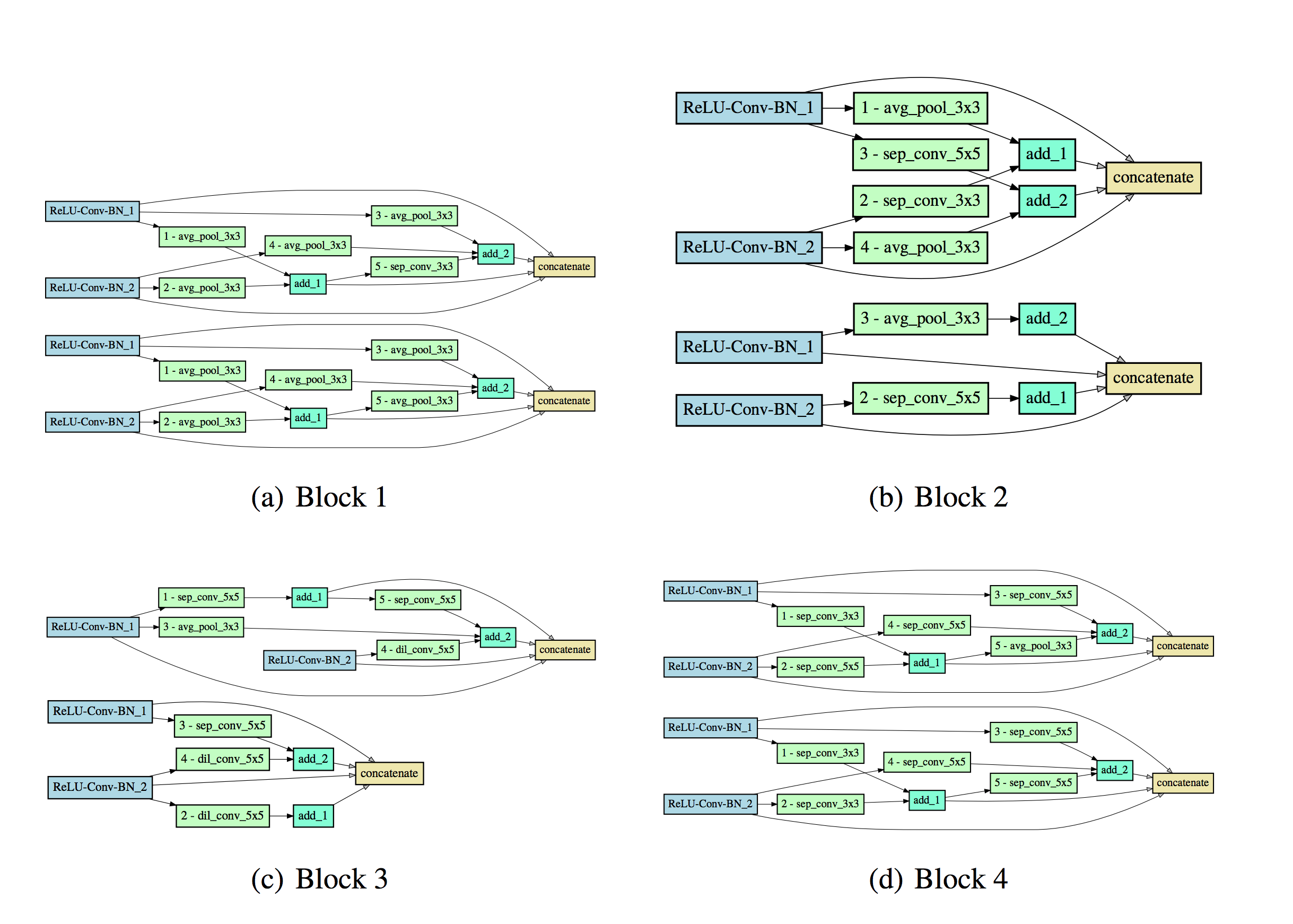
Summary of our architecture search findings: the most likely architecture structure found by NAS
-
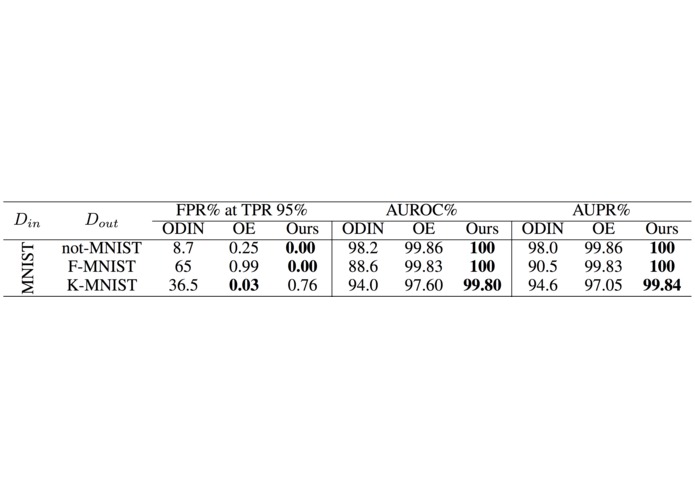
Evaluation of different outlier detectors
-
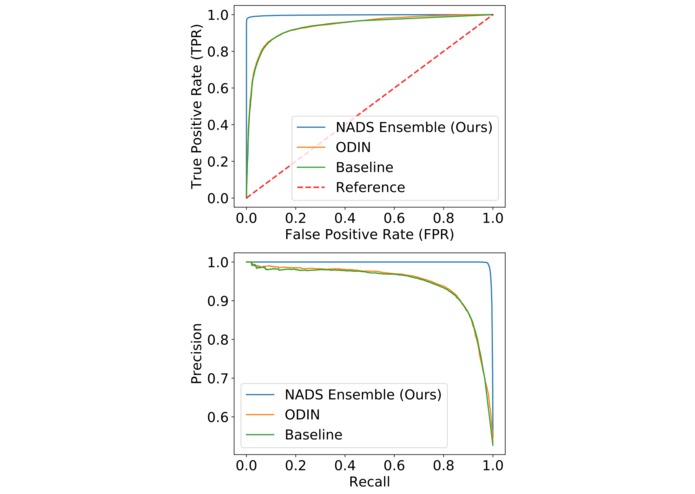
ROC and PR curves for K-MNIST, the most challenging dataset.
-
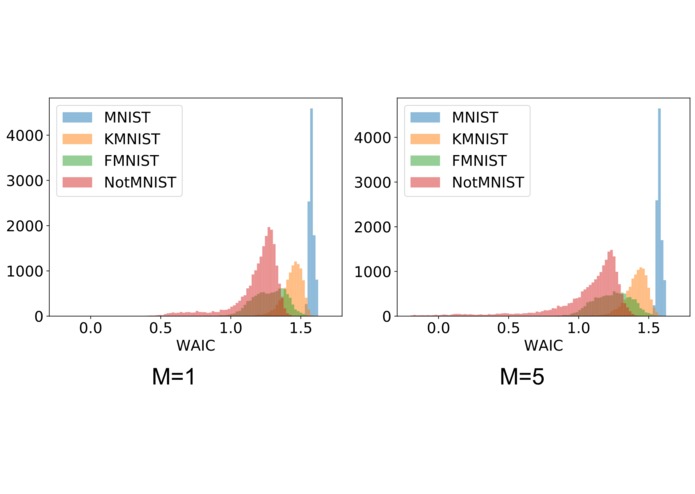
Effect of ensemble size to the distribution of WAIC scores estimated by model ensembles trained on different datasets.
-

Sample digits generated from the model.
-

Equations of the proposed optimization method
-
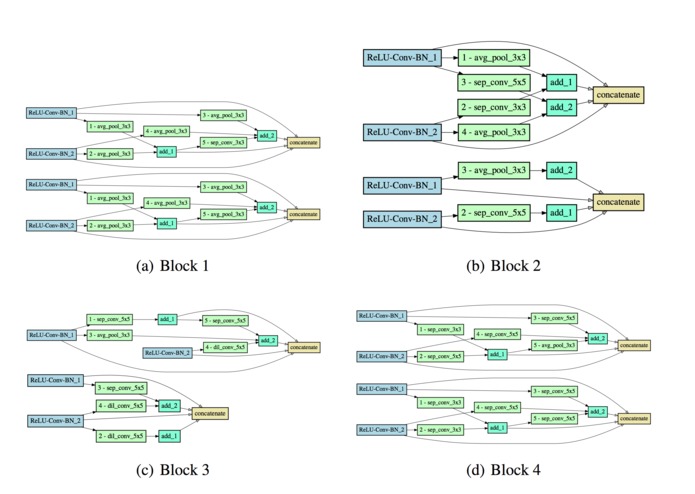
Sample architectures found by the architecture search
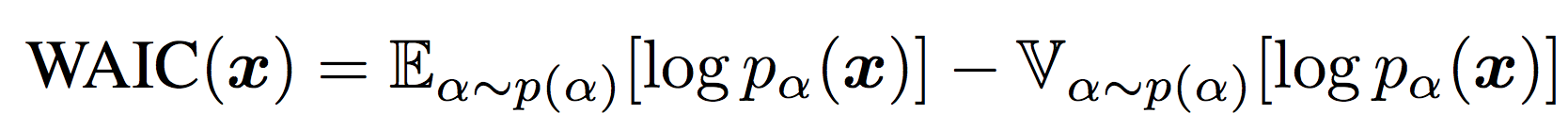


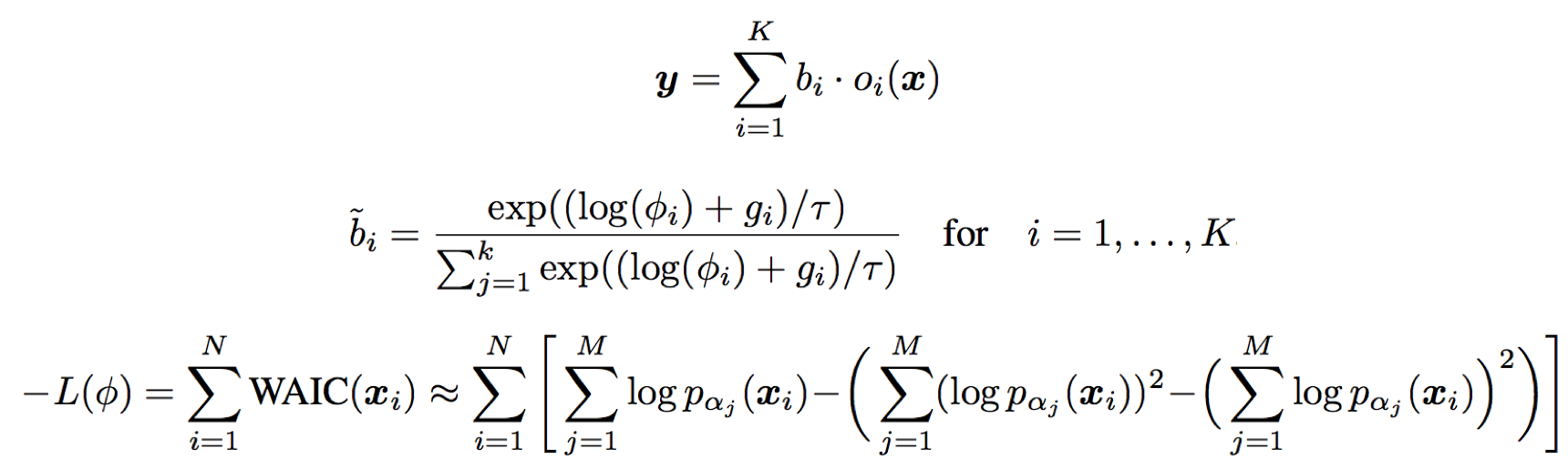
Inspiration
Neural networks are very overconfident in their predictions. They can even assign higher confidence to predictions to outlier data points compared to training data points. This could be very dangerous for critical applications such as autonomous driving, disease monitoring, and fault detection.
However, neural networks work almost like a black box: there is no guiding principle for designing robust, uncertainty aware deep models capable of screening outliers. This makes Neural Architecture Search (NAS) a promising option to explore better designs of uncertainty-aware models. However, most NAS methods focus on finding a single best architecture, whereas there could be many architectures that perform well on uncertainty estimation.
Because of this we propose a NAS framework to identify common building blocks that naturally incorporate model uncertainty quantification and compose good outlier detection models. We then use it to construct an ensemble of models to perform outlier detection.
Having neural networks identify outliers is the first step to making them become uncertainty aware and thus more applicable to critical applications. In these situations, unconfident predictions can be handled differently or even be monitored by a human for further analysis.
Challenges
NAS consists of three main components: the proxy task, the search space, and the optimization method. Specifying these for outlier detection is not immediately obvious. For example, naively using data likelihood maximization as a proxy task would cause the model to often assign high likelihood to outliers. The search space needs to be large enough to include a diverse range of architectures, yet still allowing a search algorithm to traverse it efficiently.
How we built it
Proxy Task
Instead of searching for architectures which maximize the likelihood of in-distribution data, which may cause our model to incorrectly assign high likelihoods to OoD data, we instead seek architectures that can perform entropy estimation by maximizing the Widely Applicable Information Criteria (WAIC) of the training data. The WAIC score is a Bayesian adjusted metric to calculate the marginal likelihood. The metric has been shown to be robust towards the pitfall causing likelihood estimation models to assign high likelihoods to OoD data. The score is defined in the equation above
Search Space
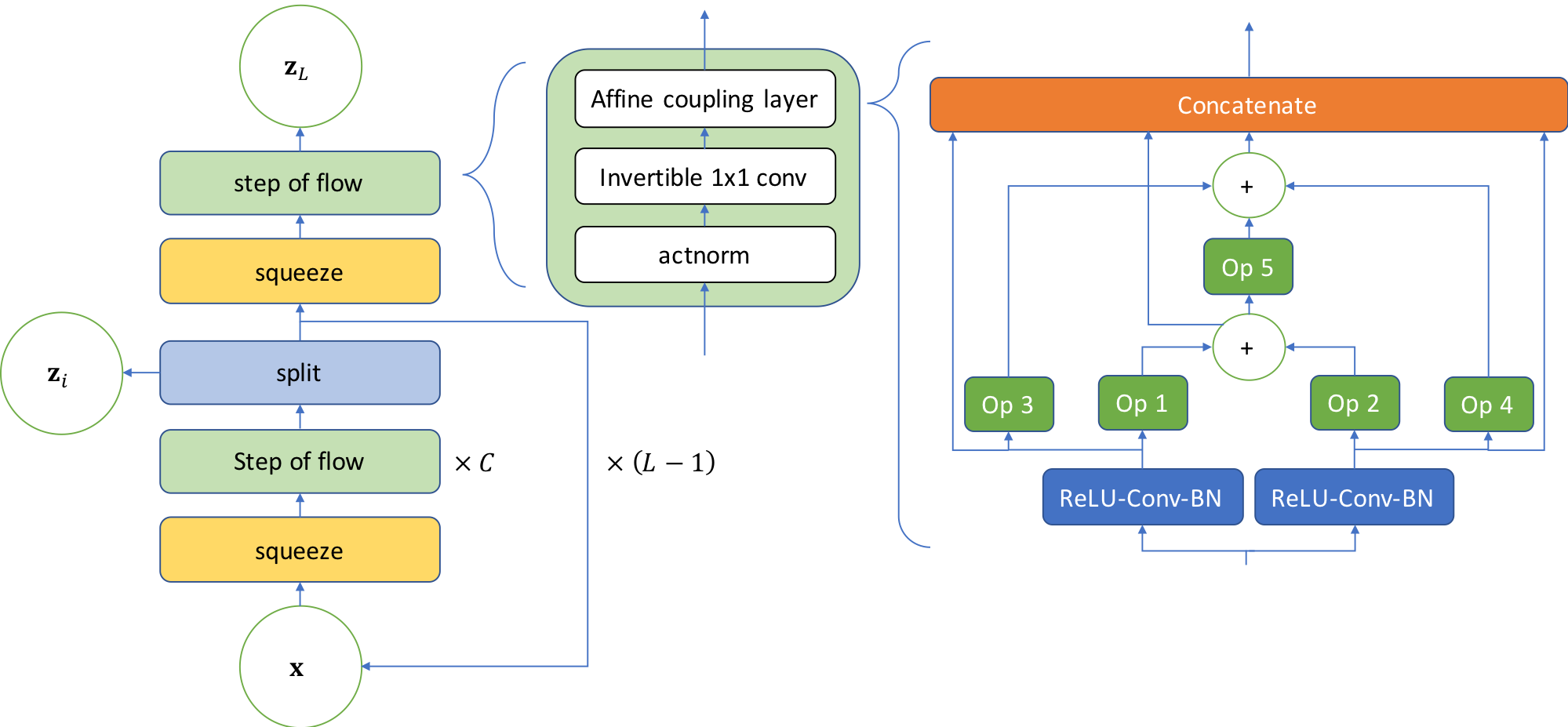
We use a layer-wise search space with a pre-defined macro-architecture, as shown in the diagram above:
Here, each operational block of the affine coupling layer is selected from a list of candidate operations that include 3 × 3 average pooling, 3 × 3 max pooling, skip-connections, 3 × 3 and 5 × 5 separable convolutions, 3 × 3 and 5 × 5 dilated convolutions, identity, and zero. We choose this search space to answer the following questions towards better architectures for OoD detection:
What topology of connections between layers is best for uncertainty quantification? Traditional likelihood estimation architectures focus only on feedforward connections without adding any skip-connection structures. However, adding skip-connections may improve optimization speed and stability.
Are more features/filters better for OoD detection? More feature outputs of each layer should lead to a more expressive model. However, if many of those features are redundant, it may slow down learning, overfitting nuisances and resulting in sub-optimal models.
Which operations are best for OoD detection? Intuitively, operations such as max/average pooling should not be preferred, as they discard information of the original data point “too aggressively”. However, this intuition remains to be confirmed.
Optimization
NAS is a discrete optimization problem and is in general, intractable. To relax this problem, we rely on the Gumbel-Softmax reparameterization, a continuous reparameterization of discrete/categorical variables. Explained briefly, the output of each operational block is a weighted sum parameterized by a normalized weight vector. If we sample this weight vector from a specific distribution, the Gumble-softmax distribution, the generating distribution can also be treated as a probability that the operational block is selected.
Results, Accomplishments, and Insights
Search Results
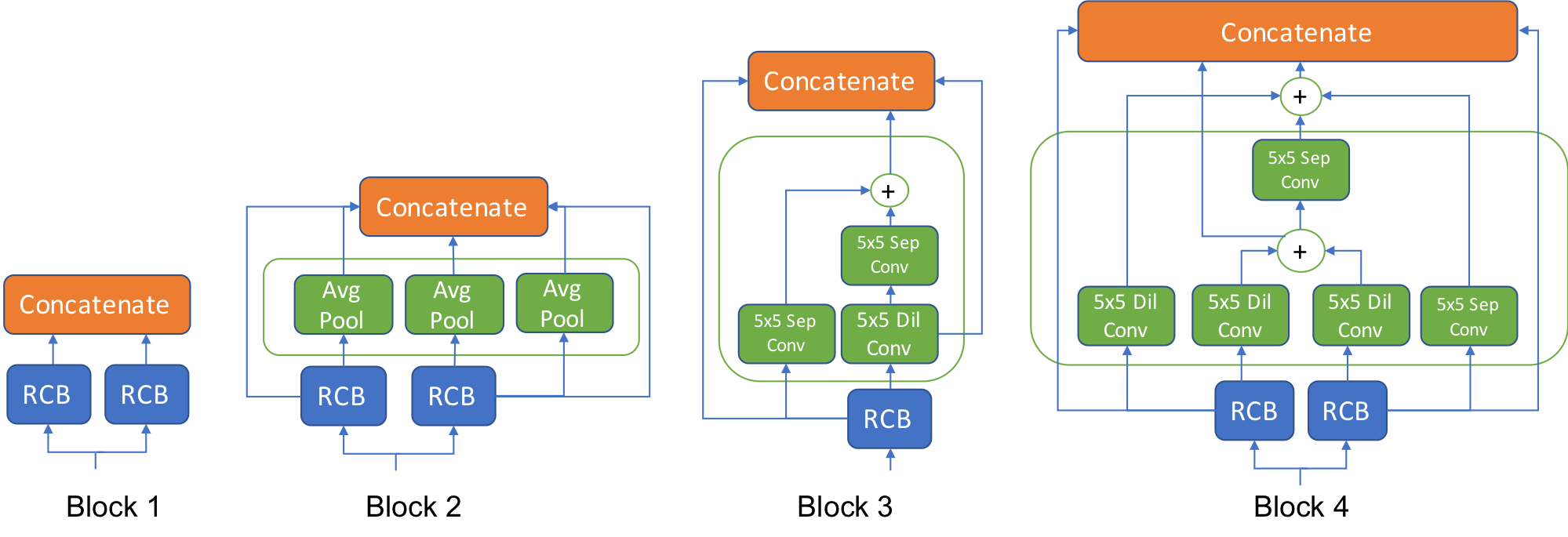
Using our architecture search on the MNIST dataset, we highlight some notable features of the architectures found. These observations are summarized below and in the second diagram:
The first few layers have a simple feedforward structure, with either only a few convolutional operations or average pooling operations. On the other hand, more complicated structures with skip connections are preferred in the deeper layers of the network. We hypothesize that in the first few layers, simple feature extractors are sufficient to represent the data well.
The max pooling operation is almost never selected by the architecture search. Intuitively, operations that discard information about the data is unsuitable for OoD detection.
The deeper layers prefer a more complicated structure, with some components recovering the skip connection structure of ResNets. We hypothesize that deeper layers may require more skip connections in order to feed a strong signal for the first few layers.
Model Ensembling Results
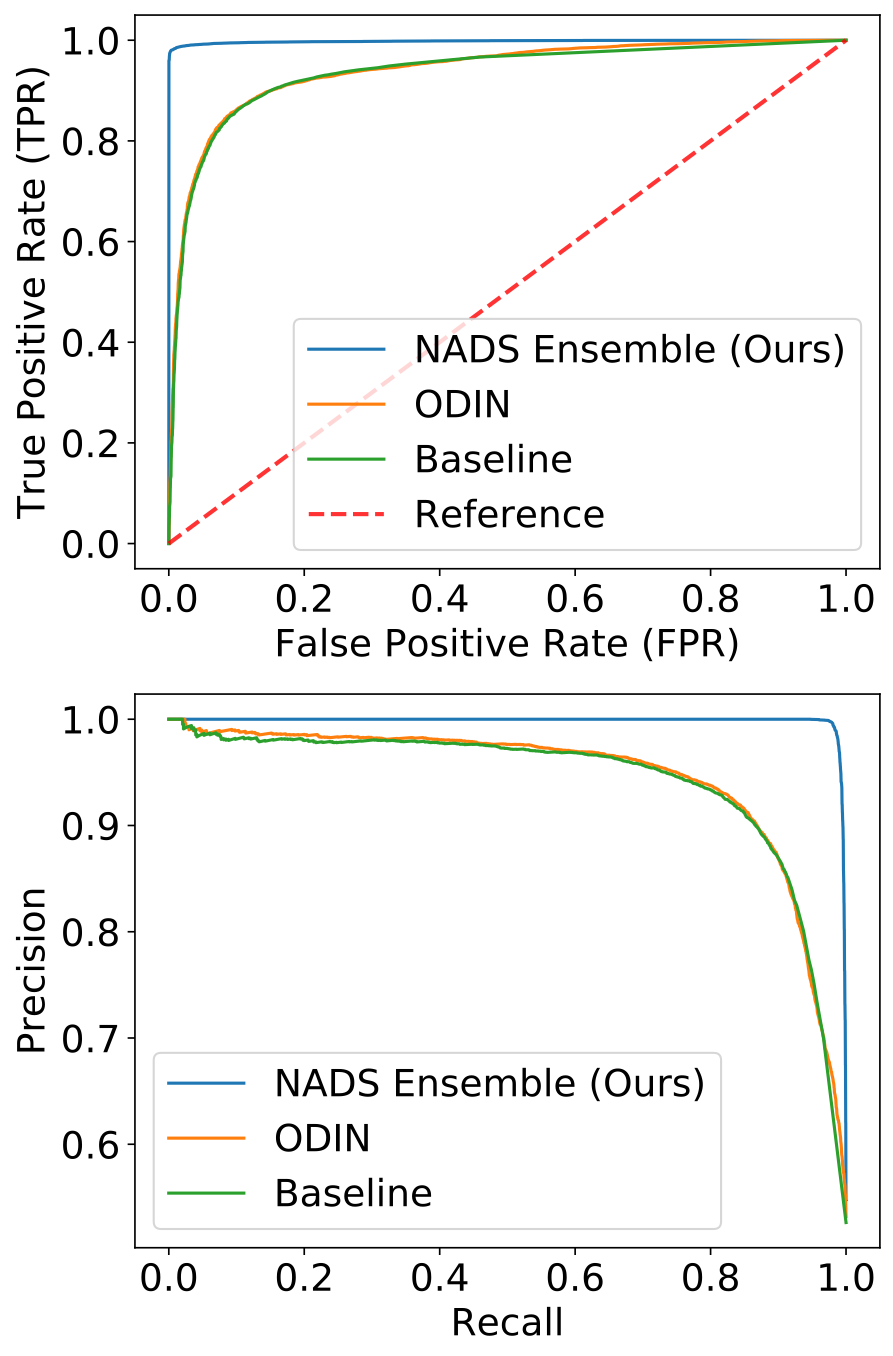
Due to our relaxation from a discrete search problem to a continuous probability estimation problem, we now have access to a posterior distribution of well-performing architectures for outlier detection. We can then sample these architectures and construct an ensemble to perform outlier detection. To this end, we trained an ensemble on the MNIST dataset and performed outlier detection against similar datasets such as not-MNIST, F-MNIST, and K-MNIST. The performance of our method is shown in the table above. We compared existing outlier detection methods ODIN and Outlier Exposure (OE). Surprisingly, our method performs competitively when compared with OE which requires access to outliers during training to perform outlier detection. The results are shown in the table above:
We further plot ROC and PR curves for the most challenging dataset for further validation. Notably, our method consistently achieves high area under PR curve (AUPR%), showing that we are especially capable of screening out OoD data in settings where their occurrence is rare.
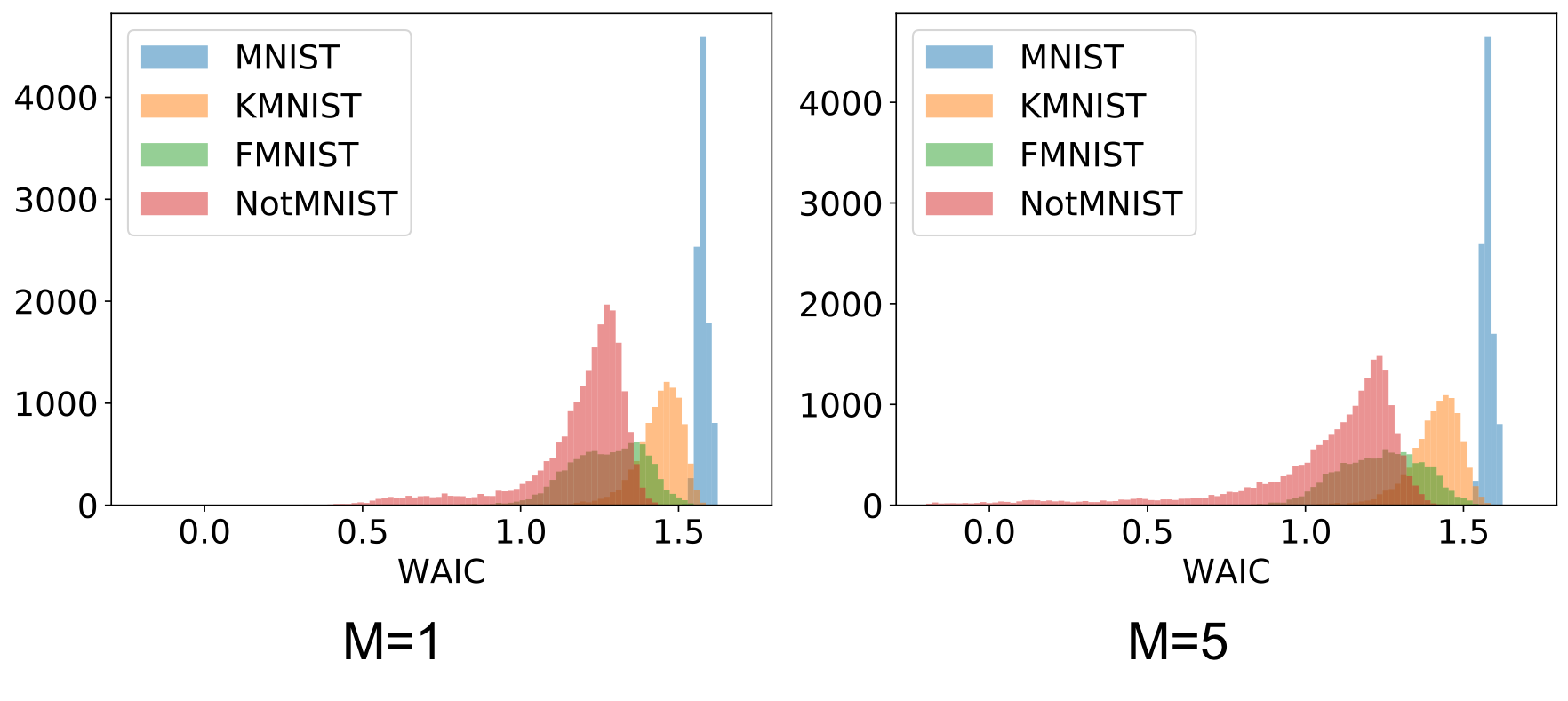
Finally, we can see the effect of the ensemble size that was used when performing outlier detection by visualizing the histograms of the data likelihoods of different datasets. We should expect that with a larger ensemble size, the training dataset should be more and more separated from the outlier dataset. The following histogram figure above confirms this:
Additional results
Interestingly, we found that our outlier detection has the ability to generate images, as we are estimating the probability density of the training data. These are shown above:
The Future of this work
Using the architecture distribution learned by NADS, we constructed an ensemble of models to estimate the data entropy using the WAIC score. We demonstrated the superiority of our method to existing OoD detection methods and showed that our method has highly competitive performance without requiring access to OoD samples. Overall, NADS as a new uncertainty-aware architecture search strategy enables model uncertainty quantification that is critical for more robust and generalizable deep learning, a crucial step in safely applying deep learning to healthcare, autonomous driving, and disaster response.

Log in or sign up for Devpost to join the conversation.