-
-
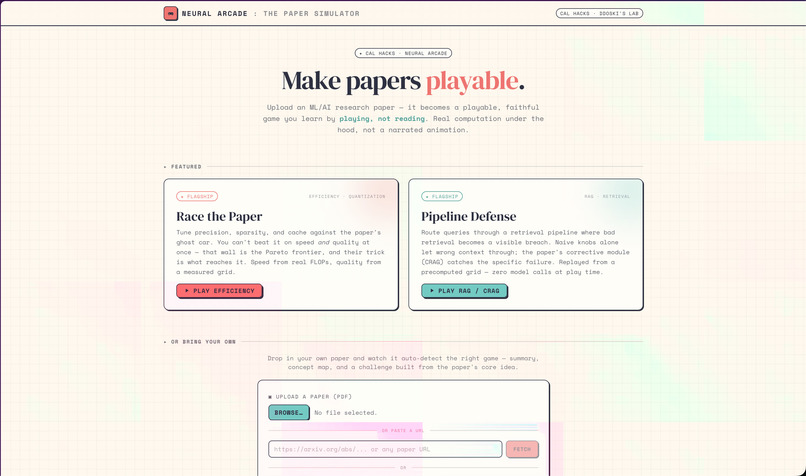
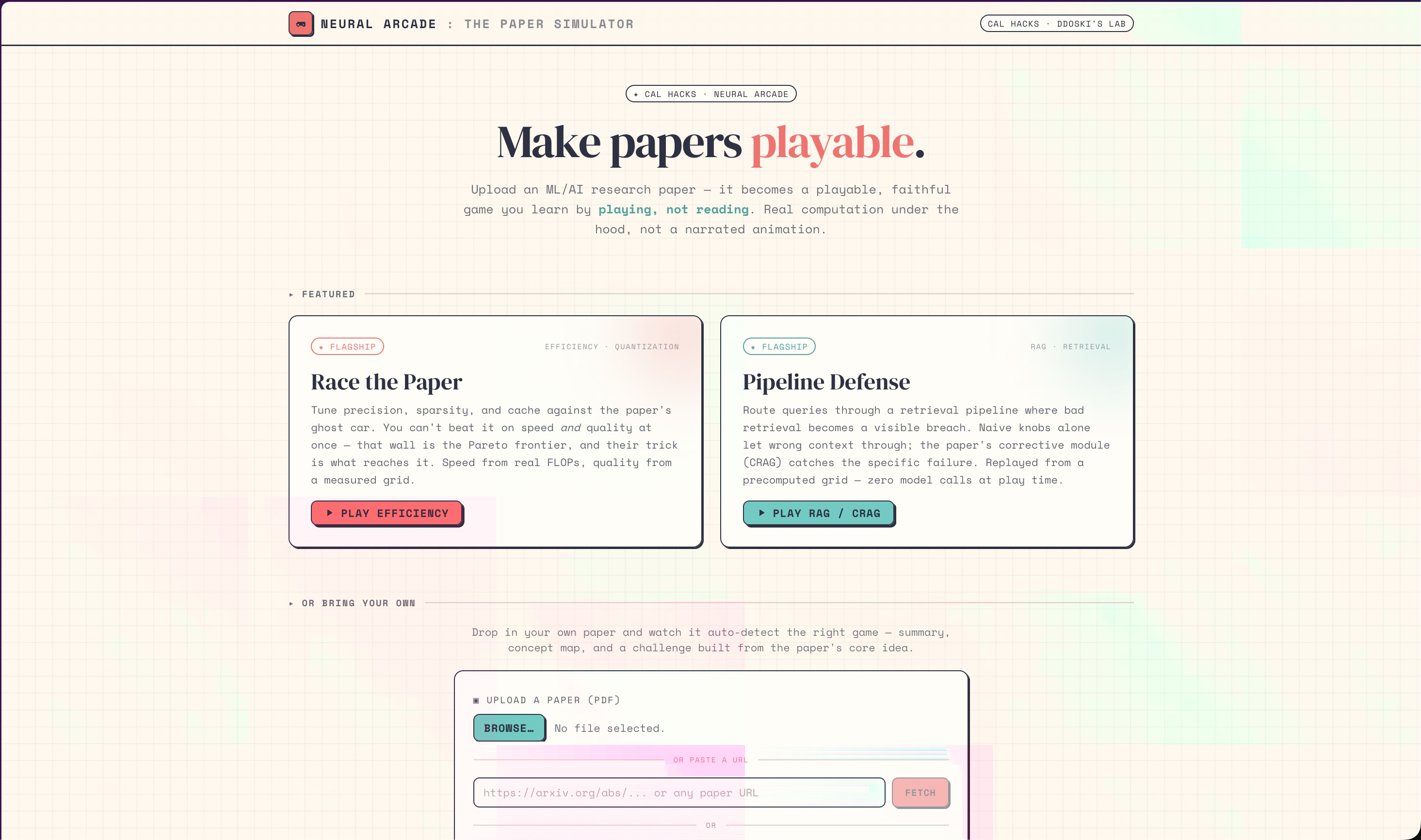
Landing page, pick a flagship (Race the Paper, Pipeline Defense) or drop your own ML/AI paper to auto-build a game from it.
-
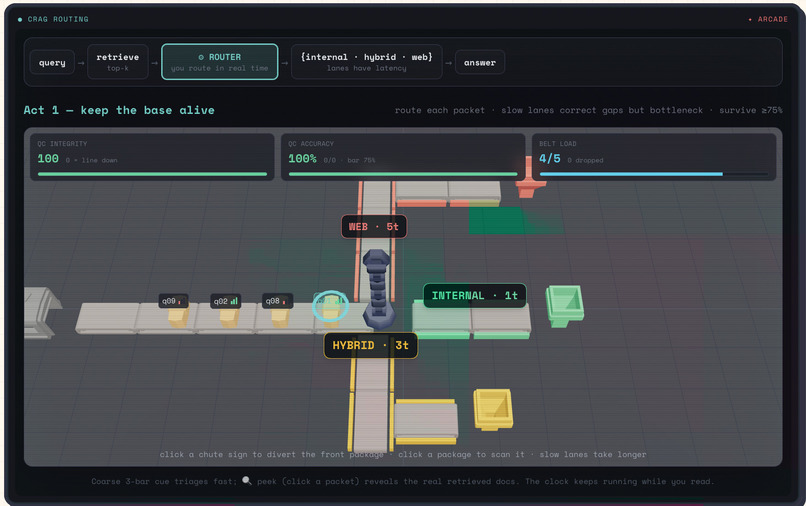
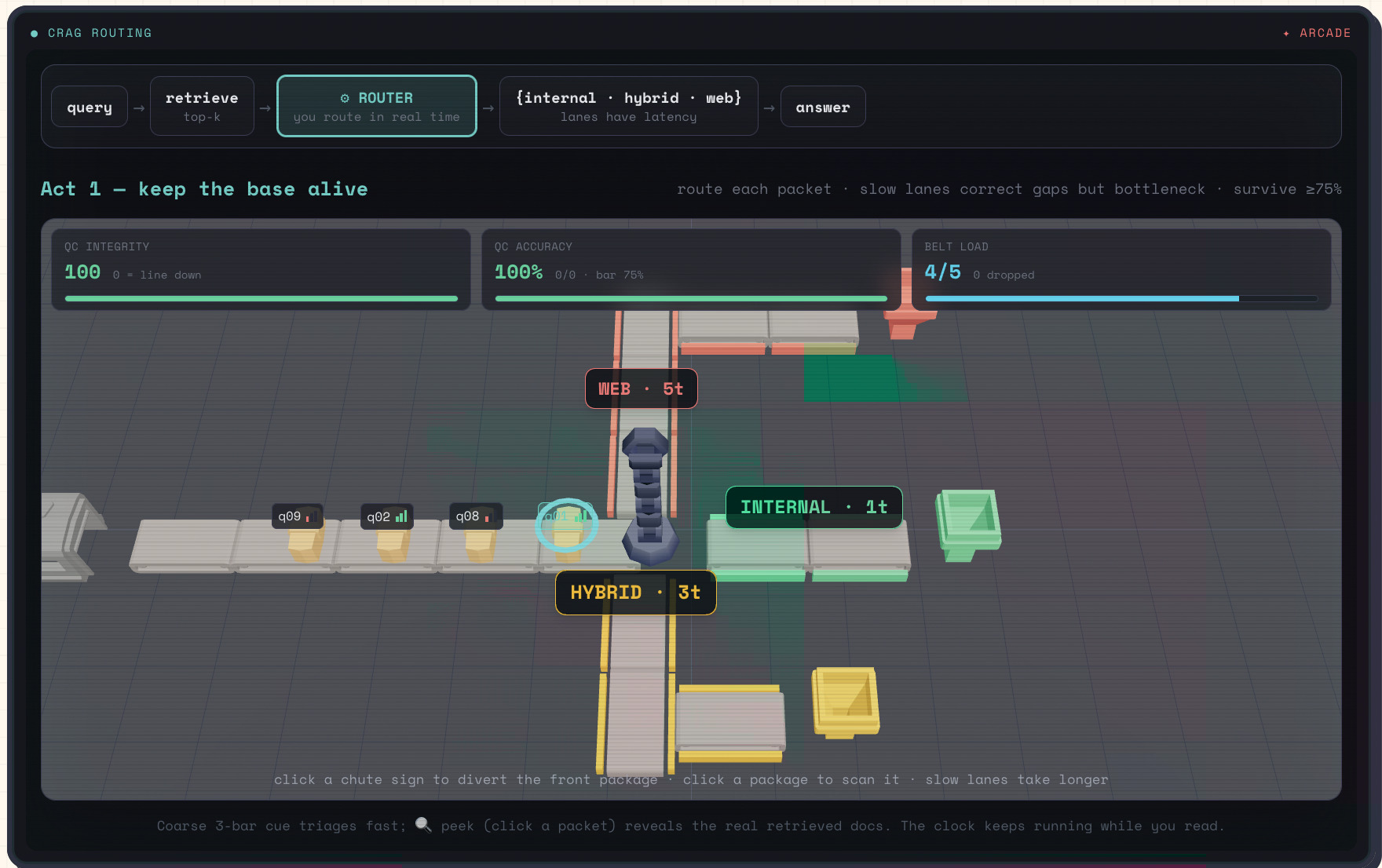
Pipeline Defense: route queries through internal/hybrid/web lanes in real time
-
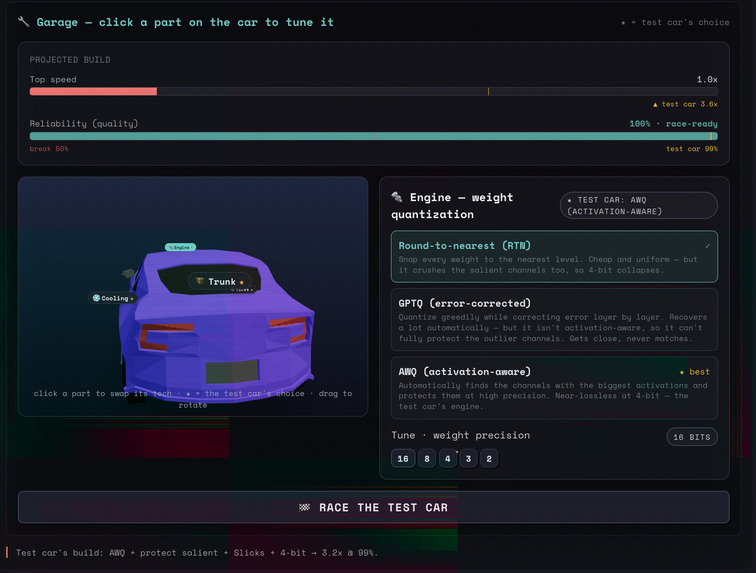
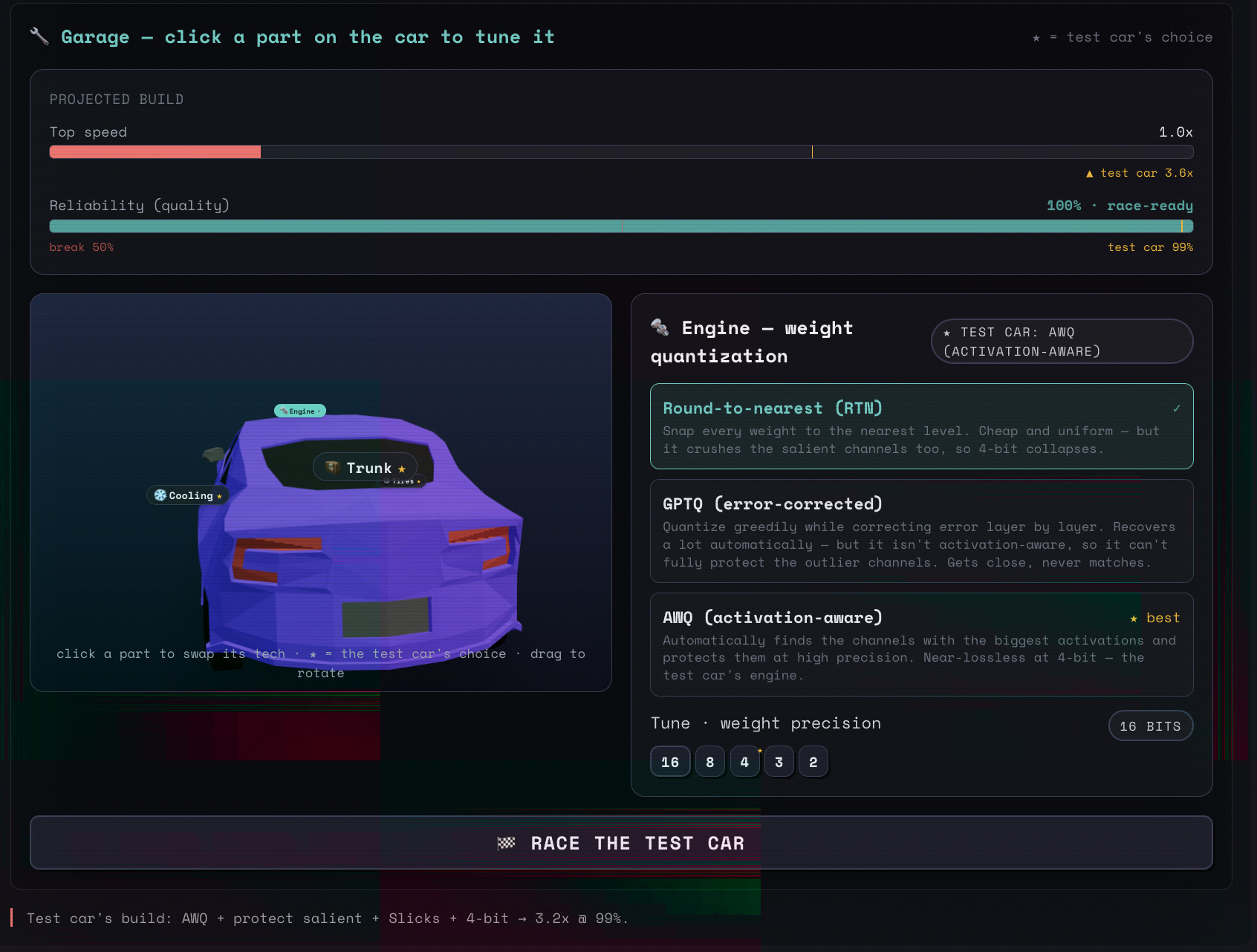
Race the Paper: tune a car's quantization (RTN/GPTQ/AWQ) and precision to beat the paper's ghost build
-
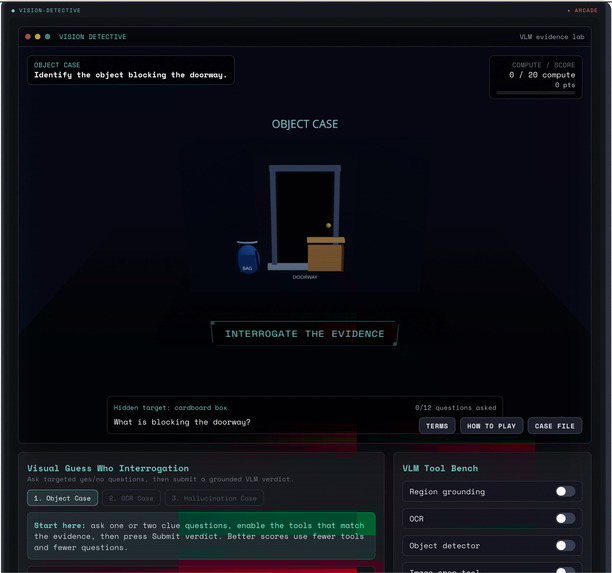
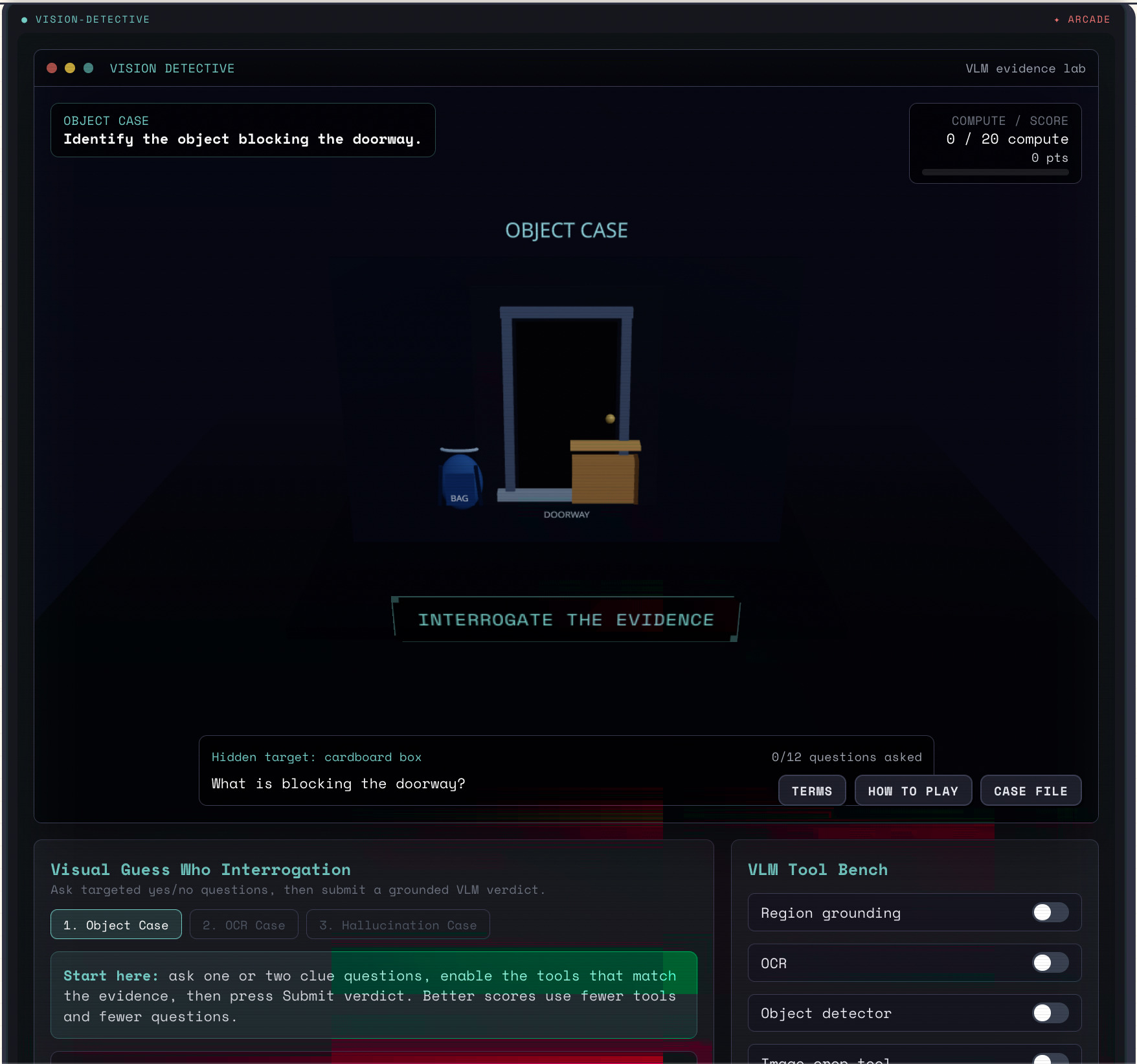
Vision Detective: interrogate a scene with VLM tools (grounding, OCR, detector) to ID the object
Inspiration
Every week, groundbreaking AI/ML research papers drop on arXiv, and almost nobody reads them. Not because people don't care, but because a 12-page PDF full of equations, ablation tables, and LaTeX notation is genuinely impenetrable for anyone who isn't already deep in the field. We watched classmates, founders, and even engineers glaze over when trying to understand papers that would directly impact their work. The insight that sparked PaperTrail AI was simple: what if you could play a paper instead of reading it?
An actual interactive game where the paper's core contribution becomes something you feel, where you drag a slider too far and watch a model reward-hack into gibberish, or toggle off a retrieval module and watch wrong answers flood through a pipeline. We wanted the "aha moment" that comes from breaking something yourself, not from reading someone else's explanation of why it matters
What it Does
PaperTrail is a platform that takes AI/ML research papers and either uploaded them as a PDF or paste it as a URL and transforms it into three things:
- Understand: An explanation and an interactive concept map that shows how the paper's ideas connect.
- Play: A unique, playable game whose mechanics are built from the paper's actual contribution. Not a generic quiz, a game where the rules, the physics, and the win condition come from what the paper discovered.
- Prove: Every game has a baseline (the naive approach) and a powerup (the paper's method). You experience firsthand why the paper matters by watching the baseline fail and the paper's method succeed. The numbers come from real computation, interpolated data points, constraint solvers, seeded simulations, and never LLM-narrated animations to make sure that you can really gain a feel for changes brought on by the research findings.
The system covers all 10 major AI research categories: RAG, agentic AI, pretraining, fine-tuning/alignment, prompt engineering, multimodal, reasoning/CoT, efficiency, evaluation, and safety. A chain-of-thought paper becomes a sampling visualization where you scale test-time compute and watch accuracy climb through voting. A RAG paper becomes a pipeline where toggling off the corrective module lets bad retrievals flood through. You tune a car (model) and race against an optimized solution and find out what their tech is about and why it's better than the naive approach.
How We Built It
Our idea lives and dies by the execution of the games; they are the user's way of feeling the theory, so making them interactive with an actual challenge and making the user struggle to figure out the solution is the end goal.
The pipeline runs on Claude (claude-sonnet-4-6) through four stages: extract (parse the PDF), classify (identify the category), generate (create a unique GameSpec), and explain (produce the concept map). Classify and explain run in parallel to keep latency down.
The game engine is the core innovation. Instead of fixed templates, we built a declarative GameSpec system, a JSON contract with 6 visualization types (curve charts, pipelines, sampling visualizations, comparison bars, token sequences, and interactive grids), composable controls (sliders, toggles, selectors), and simulation engines Claude generates a unique GameSpec per paper, choosing the visualization type and mechanics that best teach that specific paper's contribution. A universal DynamicGame renderer interprets the spec and composes the right primitives.
The simulation engines are functions, linear interpolation on data point arrays, pipeline accuracy computation from stage deltas, seeded-RNG sampling with voting logic, A* vs BFS grid search. Everything is deterministic and faithful: the numbers come from the paper's reported results.
The visuals use open-source SVG with animated gradient fills, glow filters, smooth bezier curves, and a particle canvas background. The 3D games (efficiency, vision detective) use react-three-fiber. Every game sits inside a GameFrame that handles the baseline/powerup toggle, scoring, and win/loss state.
Sponsor integrations: Anthropic Claude runs the whole AI pipeline. Redis keeps artifacts with categorization and hashing. Arize logs faithfulness and hallucination score for every generated game. Sentry does error logging and tracing. Deepgram delivers text-to-speech capability so that users can hear explanations. BrowserBase helps us get papers from links. We also have Pika video generation connected to use when the API keys are ready.
The Stack: Next.js 14 (App Router), React 18, TypeScript, Tailwind CSS, react-three-fiber for 3D, and the Anthropic SDK.
Challenges We Ran Into
- Making games that actually teach. Our first version just re-skinned fixed templates, a CoT paper and an agentic AI paper both got the same scheduling puzzle with different labels. It looked like a variety but played identically. We had to completely rethink the architecture, moving from "pick a template and fill in text" to "generate a declarative game spec that describes unique mechanics per paper."
- Faithfulness without fragility. We committed early to a rule: interactive numbers must come from real computation, never from LLM narration. That meant Claude provides data points and the client-side simulation engines do the math. Interpolation, constraint checking, and seeded RNG, getting Claude to reliably generate valid GameSpec JSON with realistic data arrays (15+ points per curve series, 20+ sampling distribution values) required careful prompt engineering with concrete examples.
- Graceful degradation. The system needs to work with no API key (demo mode), with a key but bad Claude output (template fallback), and with everything working (unique GameSpec game). Every layer has a fallback: GameSpec fails means you need template customization. Template fails, then relies on mock data. Mock data always works. We never break the demo.
- The append-only merge constraint. With multiple people working in parallel, we adopted a strict rule: the 6 shared files (types, router, templates, mock data, pipeline, package.json) can only be appended to, never restructured. Every merge conflict we had early on came from someone reorganizing a shared file. The rule eliminated conflicts entirely.
Accomplishments that we're proud of
- Unique Games. Taking inspiration from existing games like Forza, Is this seat open, A little to the left helped us broaden the ideas we were working with. With 3D modeling and interactive games we felt like we had the creative tools to make games that were able to present the challenge needed to help us understand the theory behind our demo papers.
- Every paper gets a genuinely different game. Upload a DPO paper and you get a curve chart where proxy reward diverges from true quality at the exact drift threshold the paper reports. Upload a CRAG paper and you get a pipeline where toggling the corrective module is the difference between 52% and 89% accuracy.
- Seven sponsor integrations that actually make sense. We didn't bolt on sponsors for the sake of it. Claude is the brain. Redis is the memory. Arize is the quality monitor. Sentry catches errors. Deepgram reads explanations aloud. BrowserBase fetches papers from URLs. Each one solves a real problem in the pipeline.
- The faithfulness guarantee. We can look a judge in the eye and say: every number you see in the game comes from real computation on data extracted from the paper. The curves are interpolated from actual data points. The pipeline accuracy is arithmetic on stage deltas. The sampling uses a deterministic PRNG. Nothing is made up by the LLM at render time.
- It actually works end-to-end. You upload a PDF on the home page, watch the progress bar tick through "Extracting... Classifying... Generating game... Building concept map...", and land on a result page with a summary, concept map, and a unique playable game. In production. With real papers.
What we learned
- Declarative beats imperative for AI-generated UIs. Having Claude generate React code would have been fragile and unsafe. Having it generate a declarative JSON spec that a renderer interprets is reliable, safe (no eval), and composable. The spec is just data where the client decides how to render it.
- Parallelize the pipeline, not the prompts. Running classify and explain in parallel (they both depend only on extract) cut our latency by ~40% without any prompt changes. Simple architectural wins beat prompt optimization.
- LLMs are great at choosing mechanics, not at running simulations. Claude reliably picks the right visualization type for a paper and generates realistic data points from the paper's results tables. But it would be terrible at running the actual simulation. Splitting "choose what to build" (LLM) from "do the math" (client-side engines) is the right division of labor.
- Additive-only file conventions prevent merge hell. One simple rule — append, never restructure — saved us hours of conflict resolution across a team working on different games simultaneously.
What's next
- More visualization primitives. We have 6 viz types but want to add network graphs (for diffusion/GNN papers), 3D landscapes (for loss surface visualization), and drag-and-drop composition (for architecture papers).
- Live model inference in games. Right now the games simulate the paper's results from data points. We want to run actual small models in the browser (via ONNX/WebGPU) so the game uses live inference, you'd literally watch a 125M parameter model reward-hack in real time.
- Paper-to-paper connections. Using Redis vector search to find related papers and link their games so playing one game suggests the next paper to explore, creating a learning path through the literature.
Built With
- anthropic-claude
- arize
- browserbase
- css
- deepgram
- html
- javascript
- next.js
- node.js
- openai
- pika
- react
- react-three-fiber
- redis
- sentry
- svg
- tailwind-css
- three.js
- typescript

Log in or sign up for Devpost to join the conversation.