-
-
Introduced One Custom Layer for ONNX dependency with Amazon Linux
-

Runtime Settings
-
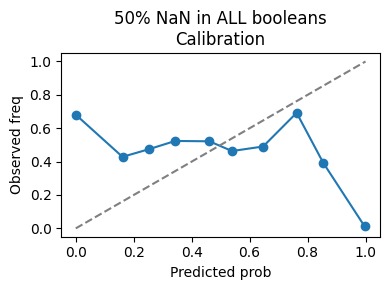
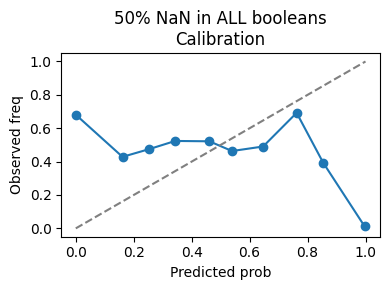
NaN injection with 50% in Booleans calibration
-
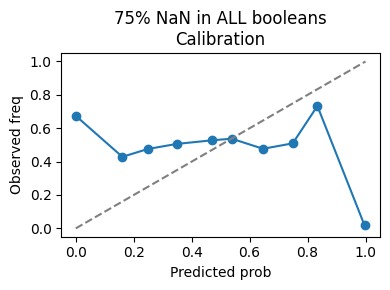
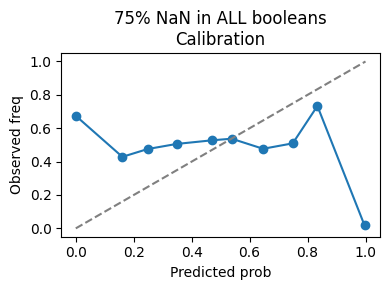
NaN injection with 75% in Booleans calibration
-
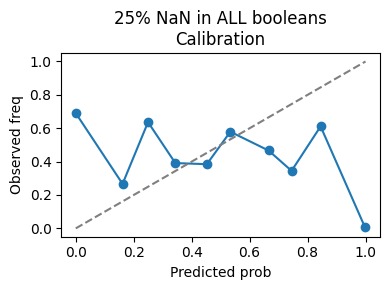
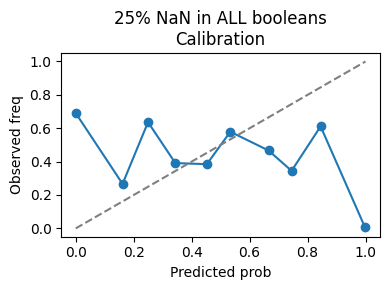
NaN injection with 25% in Booleans calibration
-
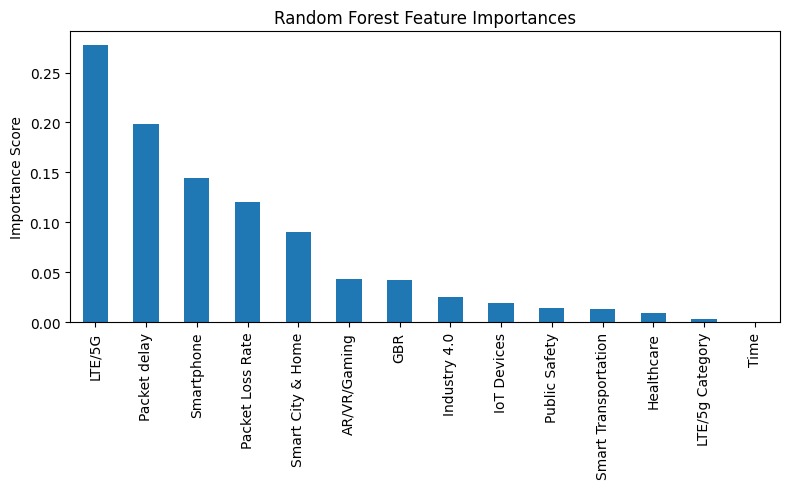
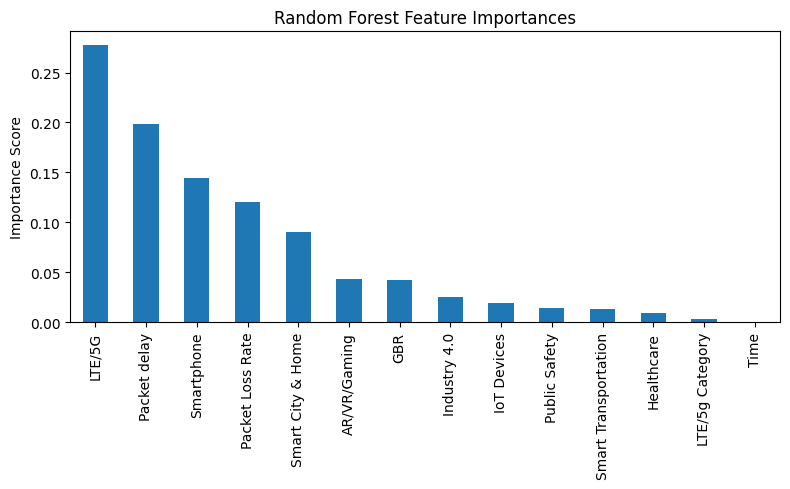
Feature Importance Plot with Random Forest
-
Pipeline
-
Lambda function "Code"
-
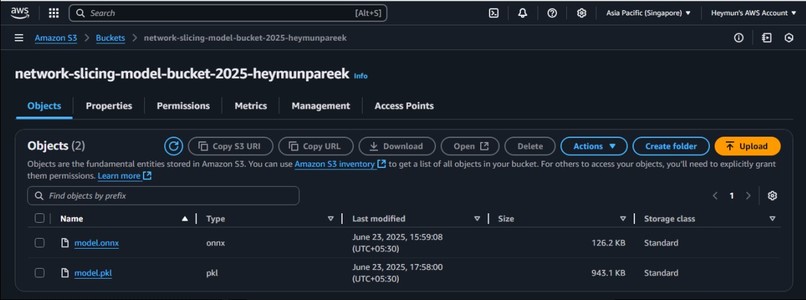
AWS model stored as pipeline pickle file and binary ONNX file in S3 bucket
-
AWS Lambda Functions
-
Amazon S3 bucket
-
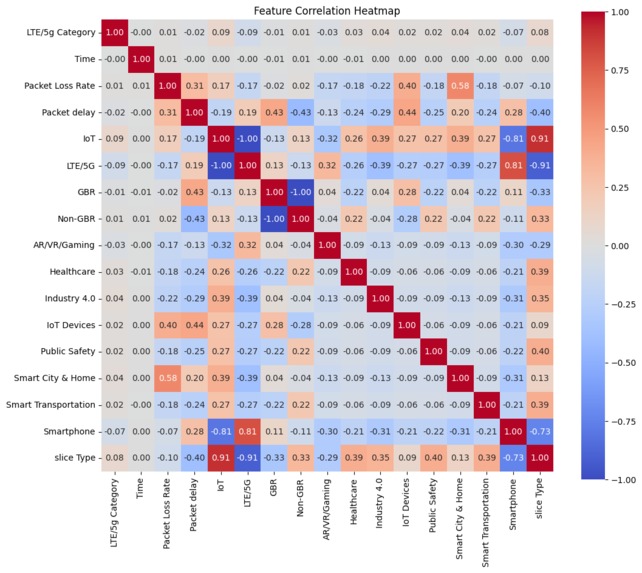
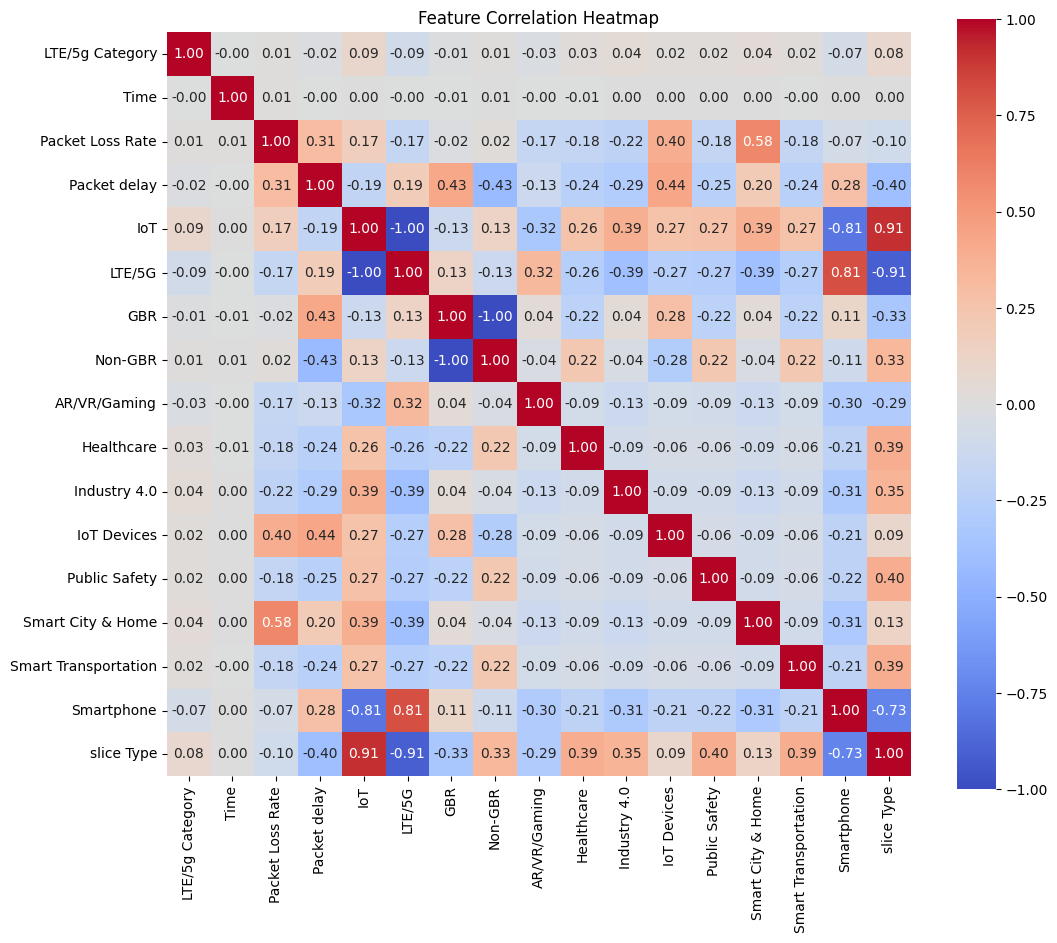
Correlation Matrix
-
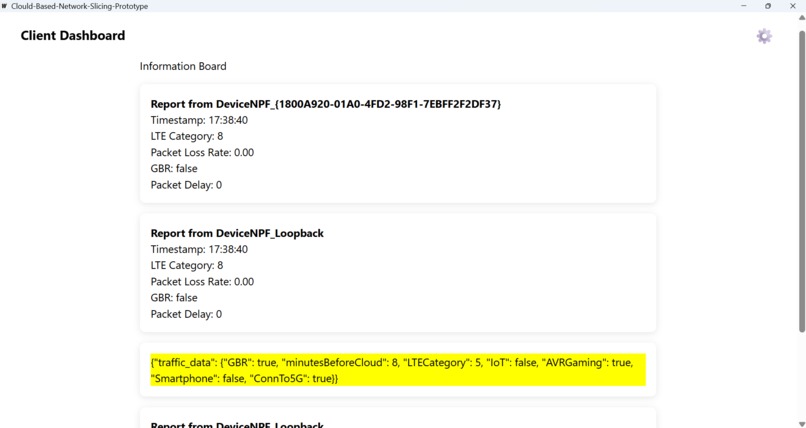
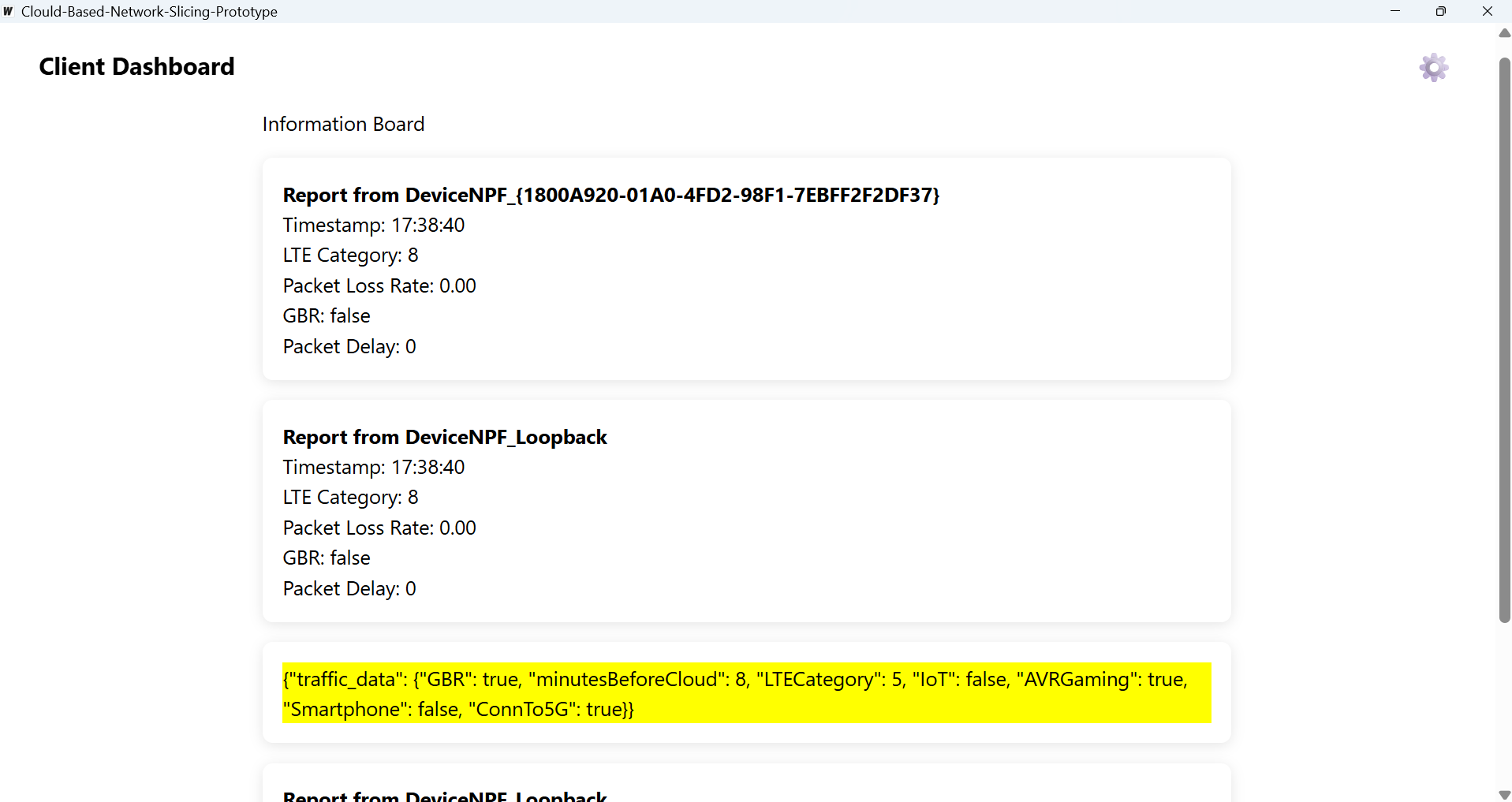
Desktop Information Board
-
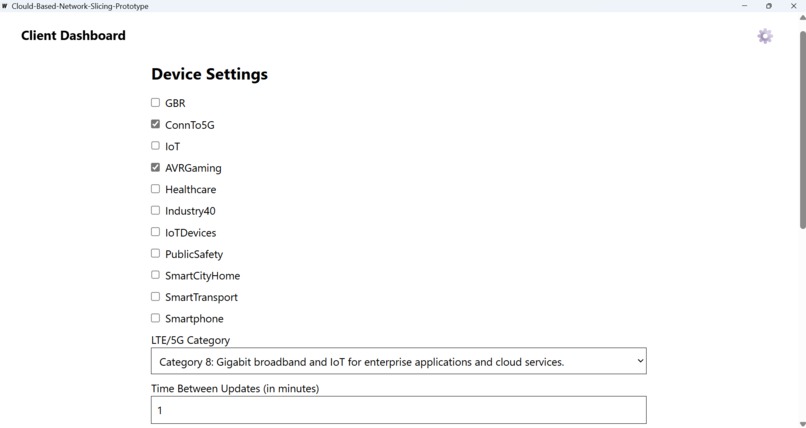
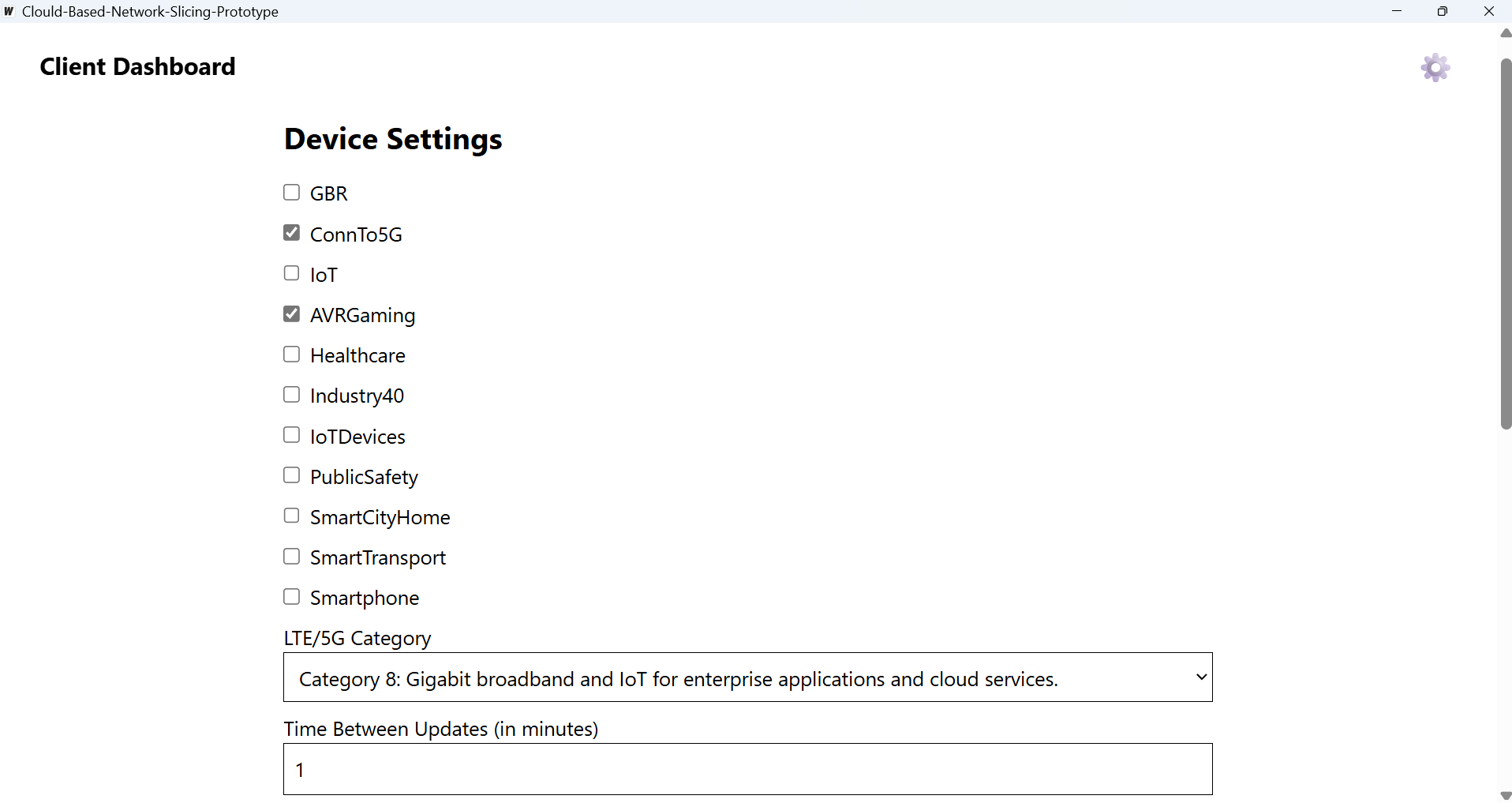
Desktop Settings

Netslicer: Dynamic Network Slice Allocation with Machine Learning
Inspiration
The initial spark for Netslicer came from observing the growing complexity of 5G networks and the vastly diverse demands of modern applications. Traditional, static network configurations felt increasingly outdated in a world craving instant gratification (like gamers who need immediate, low-latency responses), seamless experiences (such as movie watchers who require high bandwidth for continuous streaming), and efficient resource utilization (for numerous IoT devices with low data rate needs). The analogy of the "multi-lane highway" solidified the idea: if we can intelligently direct different types of traffic to the lanes that best suit their real-time needs, we can unlock the true potential of 5G and significantly enhance the user experience.
We were particularly fascinated by how a simple action like opening a game or a streaming app could have such profound and distinct network requirements. This user-centric view, coupled with the power of machine learning to adapt and learn on the fly (or via controlled batch updates), was the core inspiration. The idea of a "slice card" being dynamically handed out to clients felt like a smart, proactive approach to network management, moving beyond rigid, pre-defined rules.
What it does
Netslicer addresses the critical challenge of intelligently allocating network resources in a 5G environment. It functions as a smart allocator that, based on real-time data received from client devices, responds with an appropriate "slice card" indicating the optimal 5G network slice type.
The concept is that there would be a Golang based installer that would perform the intrinsic profiling that is gathering of information such as the network card details of the device and whether or not it is an emergency device or not, send all this intrinsic data as a JSON payload to the LAMBDA and that LAMBDA is connected to the S3 bucket storing the model. The model would classify based on the JSON payload info it receieves and send back to the client the label {1,2,3}
Specifically, it classifies incoming network traffic and user/device contexts into one of three 5G slice types:
- URLLC (Ultra-Reliable Low Latency Communication): For applications requiring extremely low latency and high reliability, such as remote surgery, autonomous vehicles, or industrial automation. (e.g., predicted as Category 1)
- mMTC (massive Machine-Type Communication): Designed for large-scale IoT deployments with low power and low data rate needs, like smart city sensors or utility meters. (e.g., predicted as Category 2)
- eMBB (Enhanced Mobile Broadband): Focuses on high-speed data and capacity for applications like 4K streaming, VR/AR, cloud gaming, and general smartphone cellular data. (e.g., predicted as Category 3)
This dynamic allocation optimizes network performance for various user profiles (gamer, movie watcher, college website checker) without relying on static, pre-configured rules.
How we built it
Our project was conceptually designed with a clear client-server architecture, leveraging cloud-native principles:
Client-Side Data Collection (Golang Desktop App):
- We envisioned a lightweight Golang application running on the client device. Golang was chosen for its efficiency, strong concurrency features, and suitability for system-level operations.
- This app would perform intrinsic profiling by observing network behavior and inferring device context. Ideally, direct monitoring (e.g., detecting
com.epicgames.fortniteactivity) would be used. However, recognizing real-world restrictions, the design focuses on reverse-engineering network traffic. This involves analyzing incoming/outgoing data on device ports to infer application behavior. - It collects crucial data points:
- LTE/5G User Equipment Category: Inferred from device capabilities.
- Packet Loss Rate: Calculated from network observations.
- Packet Delay: Estimated Round-Trip Time (RTT) between client and server.
- Guaranteed Bit Rate (GBR): A boolean flag set based on inferred application requirements (e.g., a video call needs GBR=true).
- Usage Contexts: Binary flags (Healthcare, Industry 4.0, IoT Devices, Public Safety, Smart City & Home, Smart Transportation, Smartphone) inferred from network patterns, common ports, or known service endpoints.
- It then packages all these characteristics into a JSON payload and reliably sends it to the server.
Server-Side Inference (AWS Lambda + S3):
- The core inference engine is an AWS Lambda function (e.g., written in Python or Node.js). It is triggered by HTTP requests from the Golang client.
- Upon invocation, the Lambda function loads the pre-trained machine learning model from an Amazon S3 bucket. Leveraging S3 for model artifact storage offers virtually unlimited capacity, economic scalability, and robust features like versioning and high availability, streamlining operations and ensuring atomic updates during retraining.
- The loaded model takes the client's data as input and outputs the predicted
Slice Type(eMBB, URLLC, or mMTC). - The Lambda function then returns this "slice card" (e.g., Category 1, 2, or 3) to the client.
Machine Learning Model Training (Offline/Batch):
- This component operates offline as a batch learning process. We would use historical data (simulated or collected from various network conditions and application usage scenarios) to train a multi-class classification model (e.g., Random Forest, Gradient Boosting Machine, or a simple Neural Network).
- The features for training are the intrinsic characteristics gathered by the client, and the labels are the desired slice types for those conditions.
- The trained model artifact is then uploaded to S3, making it available for the Lambda function.
- A continuous monitoring mechanism tracks the model's performance in production. If a "divergence > threshold" is detected (indicating performance degradation), it triggers an automated retraining process with updated data, and the new model version is deployed to S3. This "best of both worlds" approach prioritizes stability and efficient retraining cycles over continuous online learning.
Challenges we ran into
- The "Black Box" of Device Monitoring: The most significant conceptual challenge was the restriction on direct, deep device-level monitoring. This forced us to devise methods to infer user intent and application type (e.g., "gaming" vs. "healthcare") solely from analyzing network traffic patterns and indirect system signals. This necessitates complex reverse-engineering, heuristic development, and potentially deep packet inspection, which introduces computational overhead and privacy considerations.
- Defining and Acquiring High-Quality Training Data: For a supervised learning model, the availability of high-quality, labeled data is paramount. Generating or collecting diverse network conditions (varying packet loss, dynamic delays) combined with different application usage scenarios (intensive gaming, continuous streaming, intermittent IoT updates) and then accurately labeling the ideal 5G slice type for each specific scenario is an immense and complex undertaking that would require significant domain expertise in networking and QoS.
- Real-time Latency vs. Cold Starts in Serverless: While AWS Lambda offers excellent scalability, cold starts can introduce noticeable latency, which is detrimental for URLLC applications where "milliseconds matter." Mitigating this would require strategies like provisioned concurrency or warming up Lambda functions, adding to operational complexity.
- Robust Model Retraining and Deployment Pipeline: Building a reliable MLOps pipeline for continuously monitoring model performance, detecting data drift, triggering batch retraining, validating the new models, and then atomically deploying them to S3 (ensuring Lambda seamlessly picks up the new version) is a non-trivial engineering task. Maintaining zero downtime during these updates is critical for a live system.
- Complexity of a Reinforcement Learning Feedback Loop: While a rating-based control mechanism from clients for "fairness" is an intriguing idea for future enhancement, integrating it effectively for true reinforcement learning would introduce immense complexity. Defining the precise reward function, managing the exploration-exploitation dilemma, and ensuring stability and predictability in a production network environment would be a significant research and engineering challenge.
Accomplishments that we're proud of
- Conceptualizing a Dynamic 5G Slicing Solution: We're proud of devising a machine learning-driven approach that addresses the static nature of traditional network slicing, moving towards a truly adaptive and intelligent system for 5G resource allocation.
- Designing a Pragmatic Data Collection Strategy: Overcoming the limitations of direct device monitoring by focusing on network traffic analysis and inferential profiling is a practical and scalable design choice we are proud of.
- Leveraging Serverless Architecture for Scalability: The decision to use AWS Lambda and S3 demonstrates an understanding of modern cloud infrastructure for highly scalable, cost-effective, and robust ML inference pipelines.
- Framing the ML Problem Accurately: Clearly defining the problem as a multi-class classification and choosing batch learning for its stability and operational benefits showcases a solid grasp of machine learning principles in a real-world context.
- Identifying Key Performance Metrics: Pinpointing the relevant classification metrics (Accuracy, Precision, Recall, F1-Score, Confusion Matrix, Log Loss) for evaluating the model's effectiveness.
What we learned
Through the design of Netslicer, I gained invaluable insights:
- The Interplay of Networking and ML: A deep understanding of 5G network slicing (eMBB, URLLC, mMTC) is crucial for building effective ML models for network management. ML isn't a silver bullet; it must be grounded in domain knowledge.
- Real-world vs. Ideal Scenarios: The constraints on device monitoring taught me to think creatively and practically about data collection in challenging environments, emphasizing inference over direct observation.
- Architectural Trade-offs: The decision between batch and online learning, and the choice of serverless platforms, highlighted the importance of understanding the trade-offs between speed, stability, cost, and operational complexity.
- The Importance of MLOps: While building the core ML model is exciting, the true challenge and learning comes from designing the entire lifecycle, from data collection and training to robust deployment, monitoring, and retraining pipelines.
- User Experience Drives Technical Requirements: The core idea of catering to different user needs (gamer, movie watcher) directly translates into distinct technical QoS requirements that the network must fulfill, making the problem user-centric from the start.
What's next for NetSlicer
- Prototype Development and Data Simulation: The immediate next step would be to build a basic prototype of the Golang client and Lambda function. Concurrently, focus on generating or simulating realistic, labeled datasets that accurately represent various network conditions and application usage patterns to begin training initial ML models.
- Refining Inferential Profiling: Investigate advanced techniques for network traffic analysis and behavioral inference to improve the accuracy of detecting usage contexts (Gaming, Healthcare, etc.) without intrusive monitoring. This might involve exploring more sophisticated packet inspection libraries or statistical analysis of traffic flows.
- Model Selection and Hyperparameter Tuning: Experiment with different multi-class classification algorithms (e.g., XGBoost, LightGBM, simple neural networks) and rigorously tune their hyperparameters to achieve optimal performance on the collected datasets.
- Building the MLOps Pipeline: Develop a robust CI/CD pipeline for the ML model, including automated retraining triggers (based on performance divergence), version control for models, automated testing, and seamless deployment to S3 and Lambda.
- Exploring Feedback Mechanisms (Reinforcement Learning): While a significant undertaking, future work could explore integrating a simplified feedback loop where aggregate client satisfaction metrics (derived from application-level KPIs or indirect signals) could inform future model adjustments, potentially moving towards a reinforcement learning approach to truly optimize "fairness" in resource distribution.
- Integration with 5G Core Network Elements: Ultimately, for real-world deployment, Netslicer would need to integrate with actual 5G core network orchestration and slice management functions (defined by 3GPP standards) to effect the slice assignments. This would involve developing APIs and interfaces compatible with network function virtualization (NFV) and software-defined networking (SDN) controllers.
Built With
- amazon-web-services
- aws-lambda
- json
- python
- randomforest


Log in or sign up for Devpost to join the conversation.