-
-
interface
-
eye opening animation
-
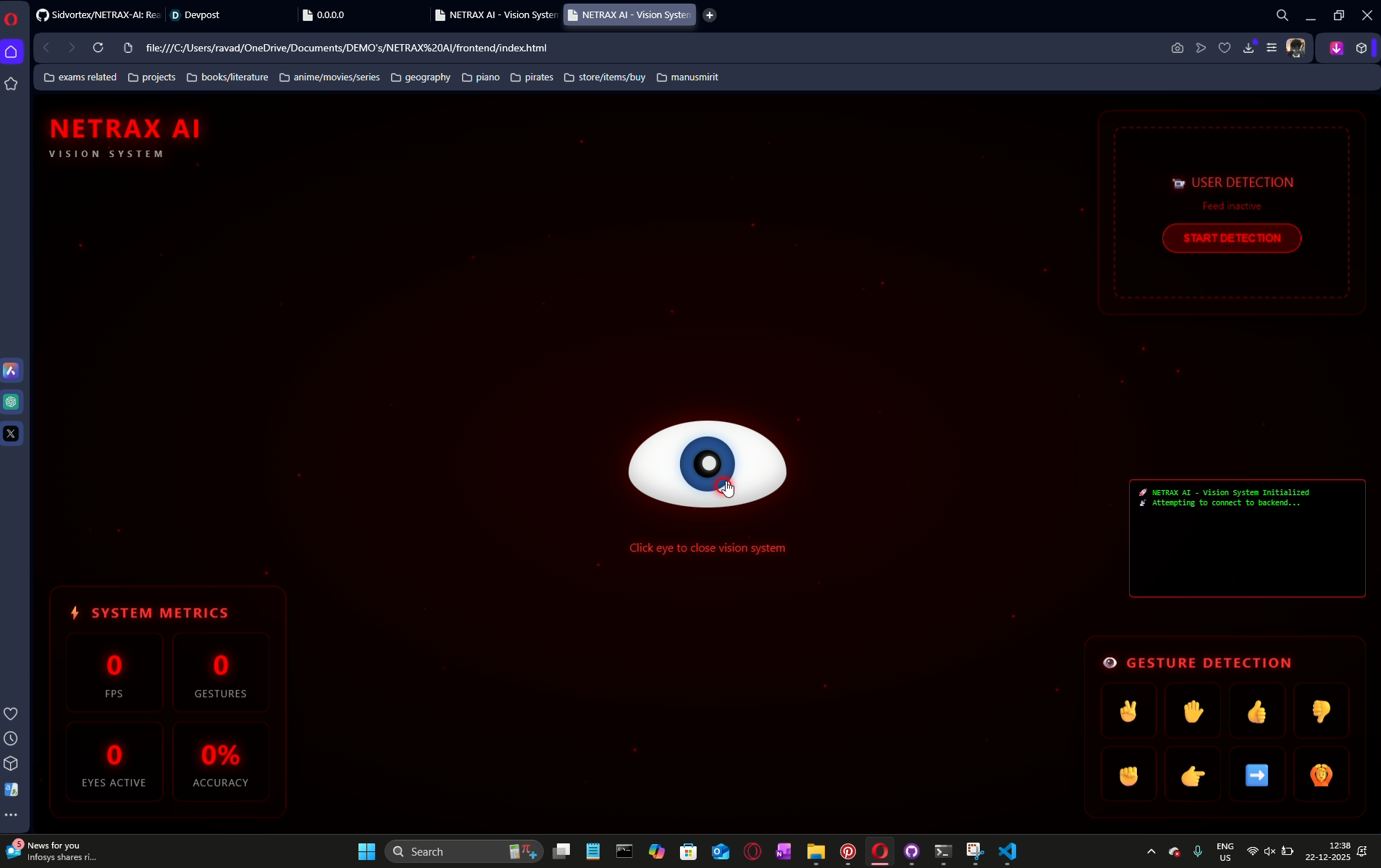
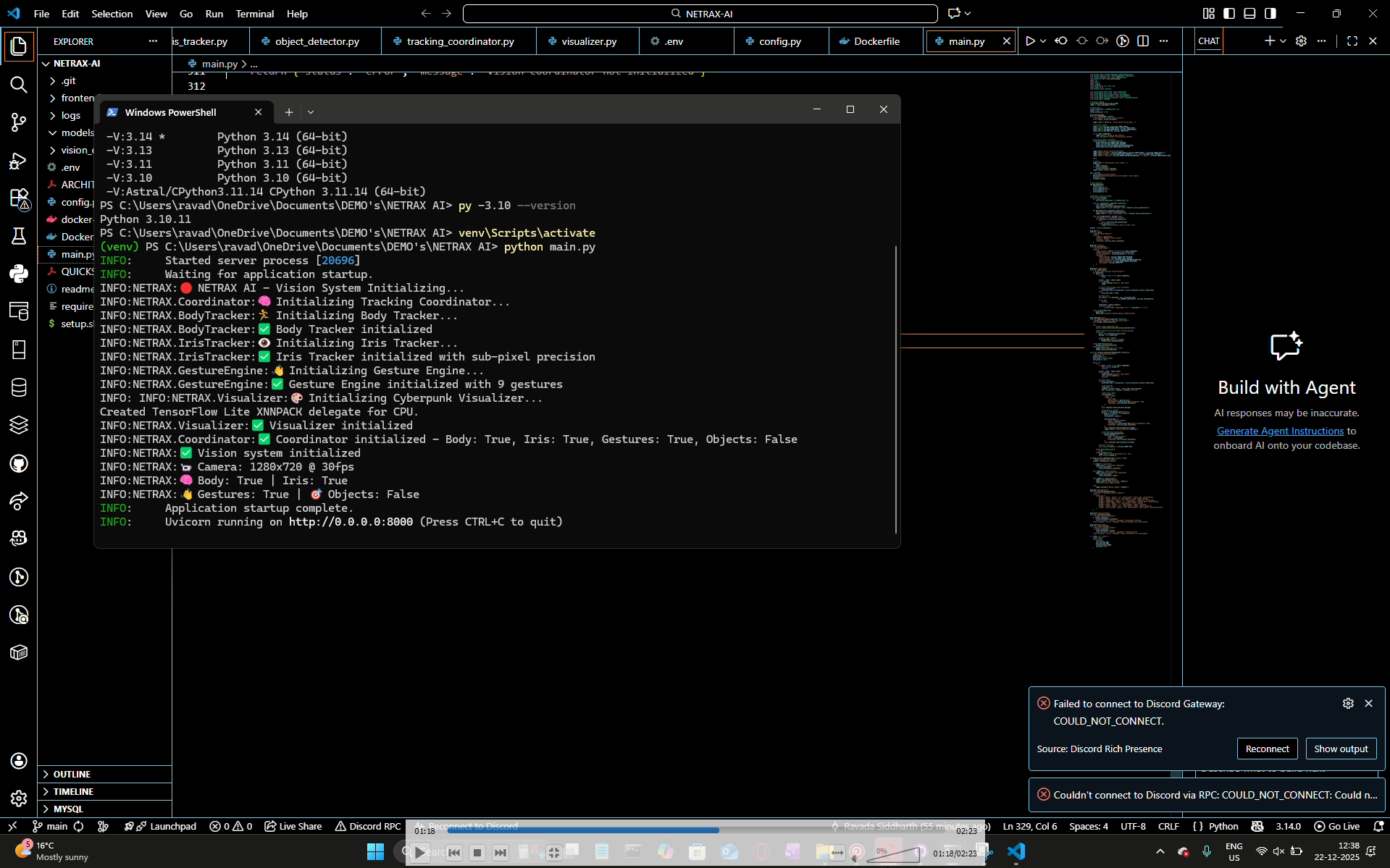
system starting
-
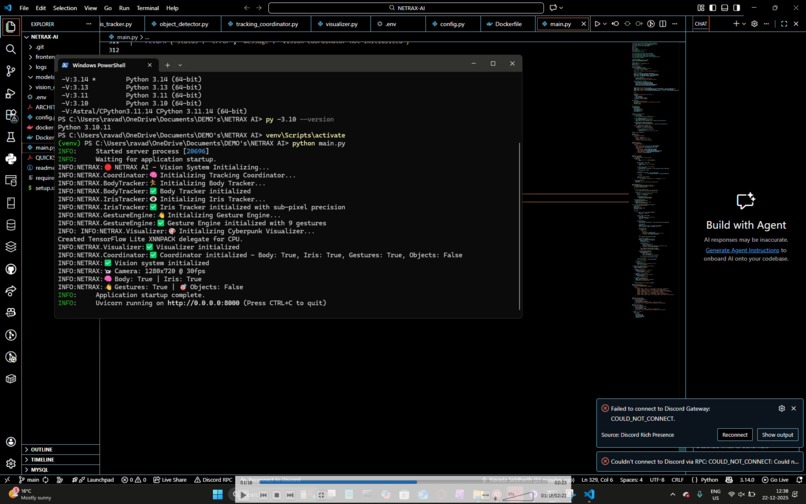
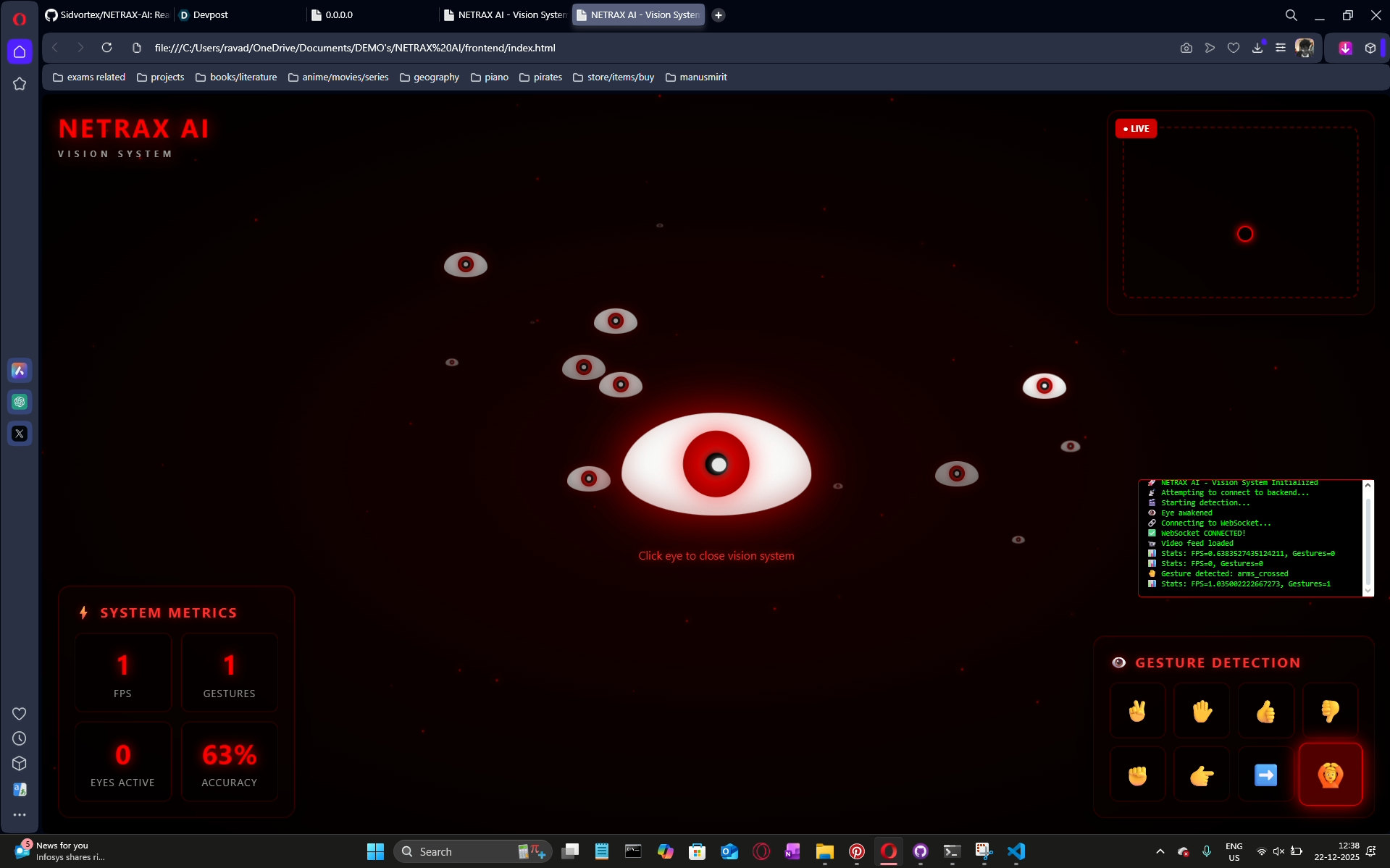
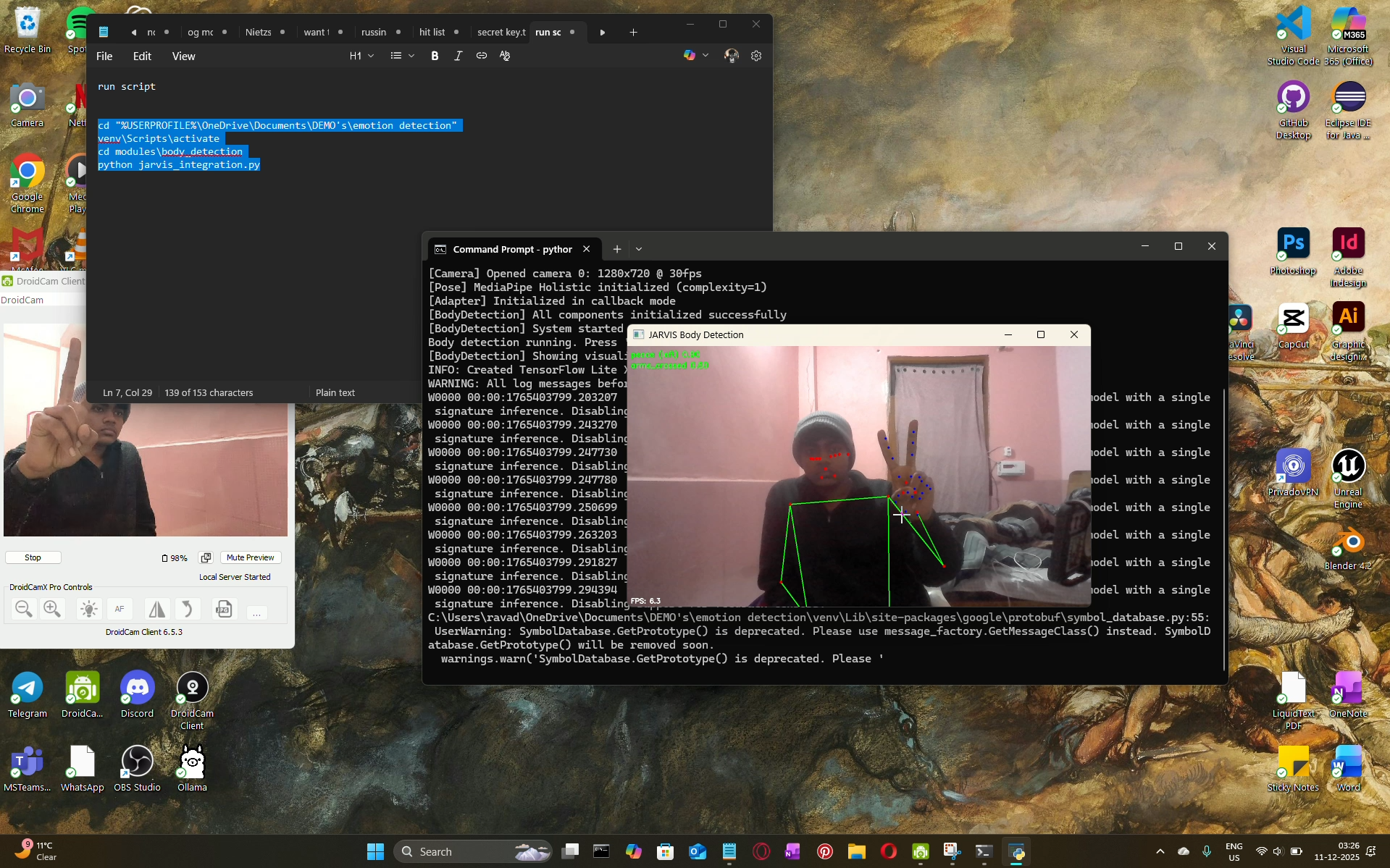
integrating the frontend and the working
-
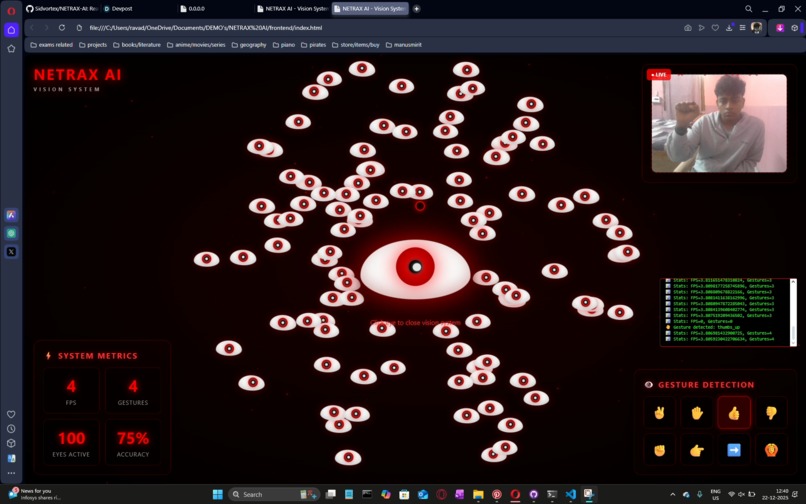
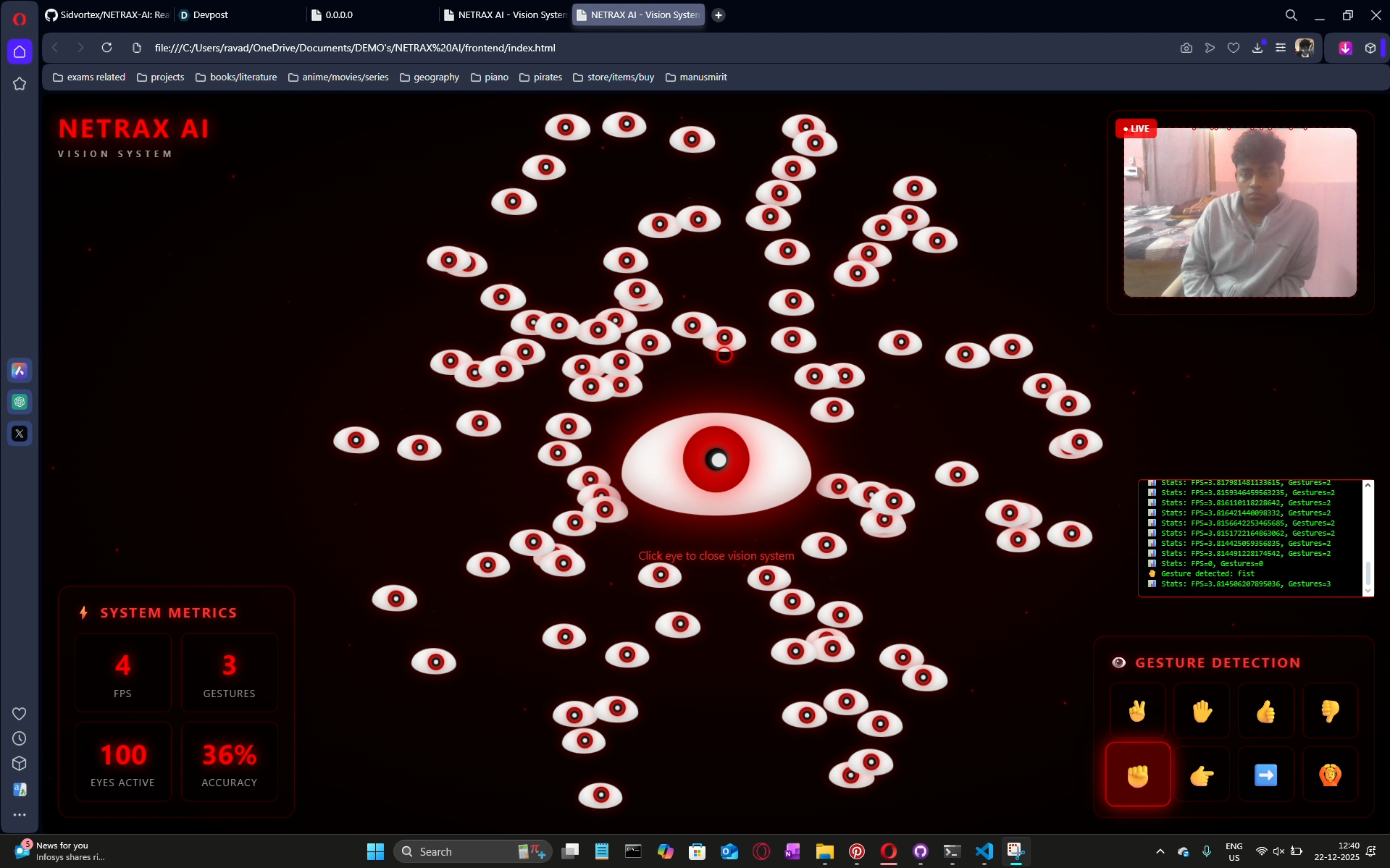
some other gestures
-
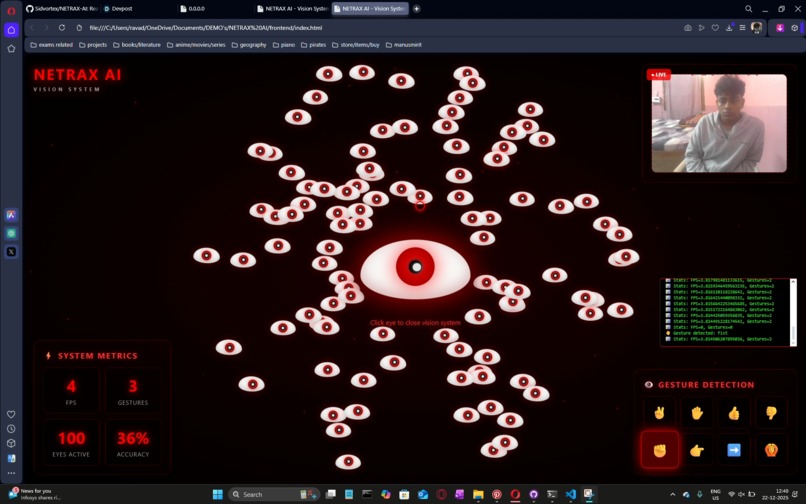
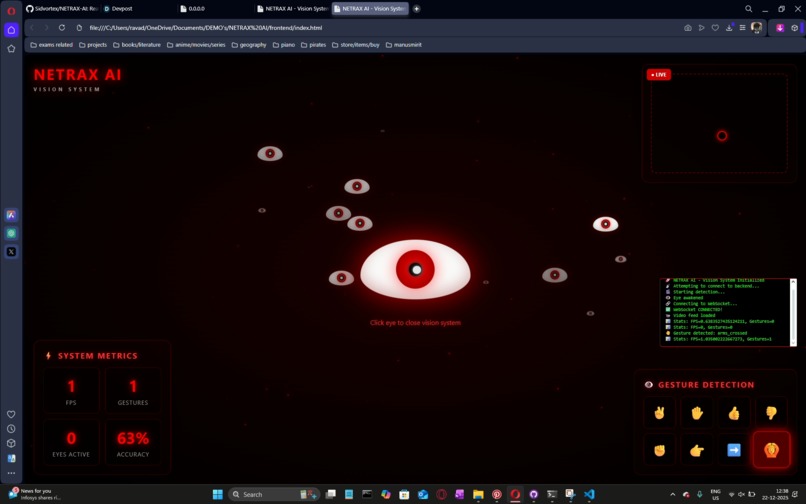
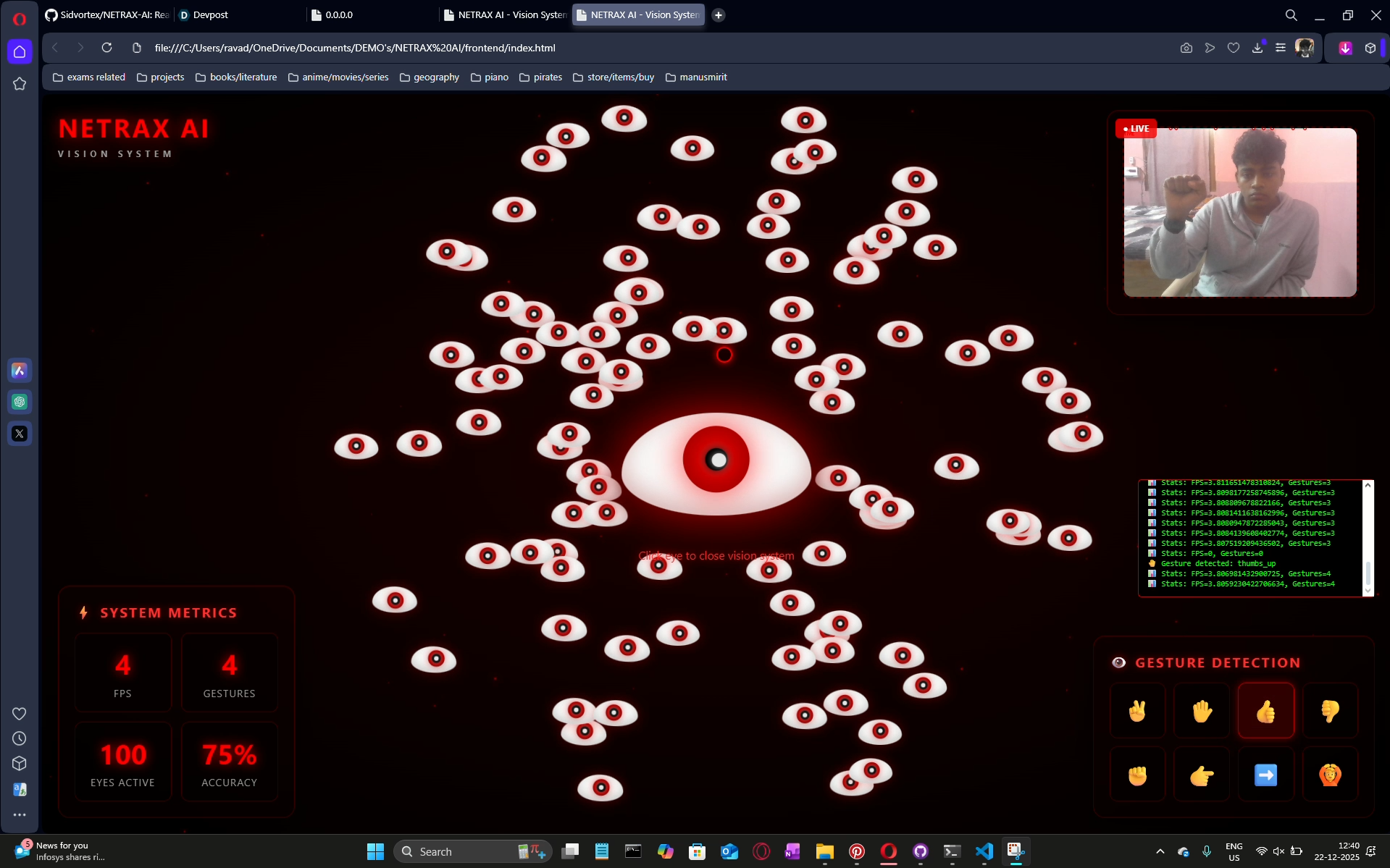
detecting gestures with a pop up below
-
gestures
-
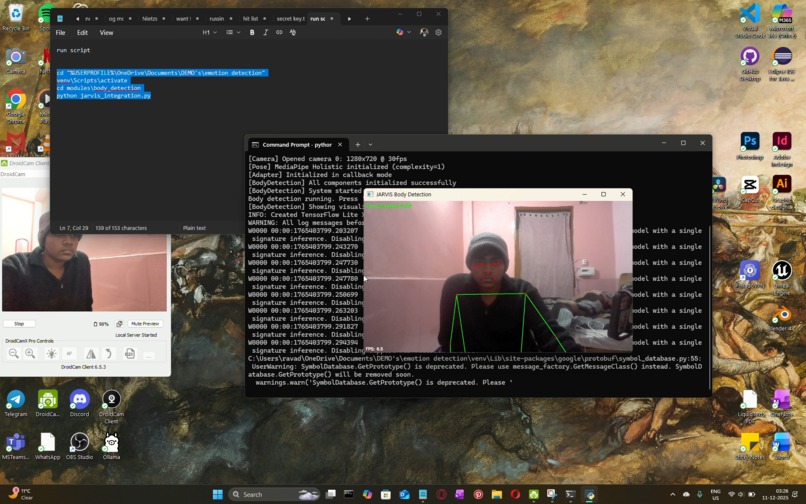
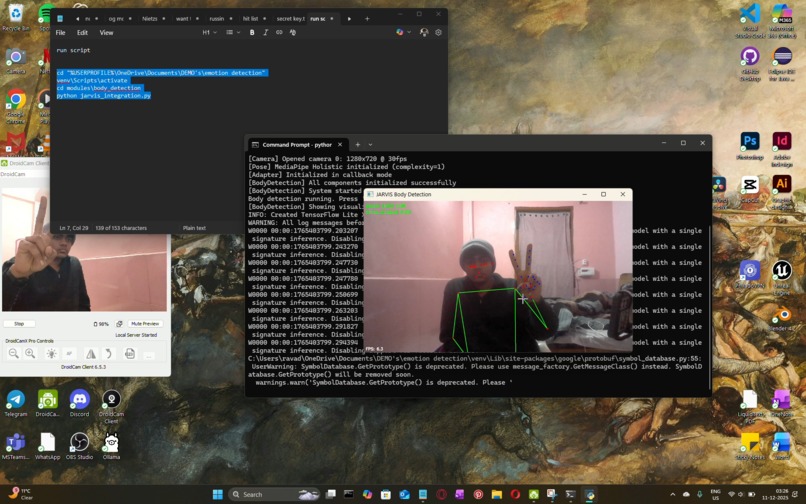
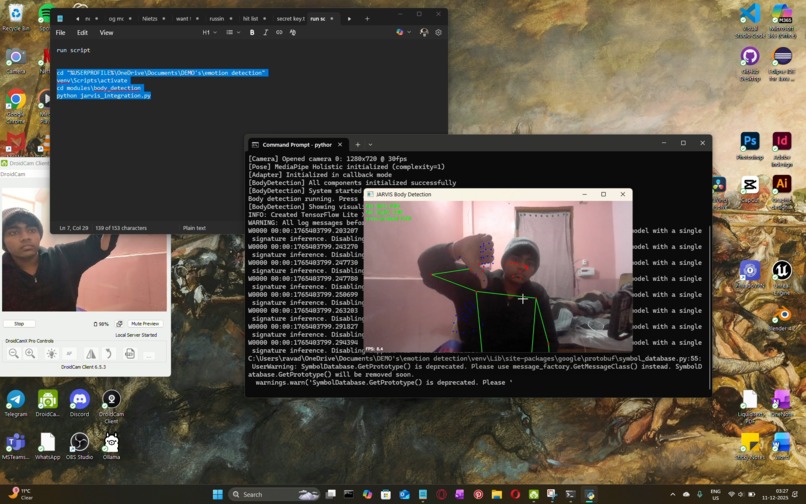
initial terminal working with body skeletons
-
gestures
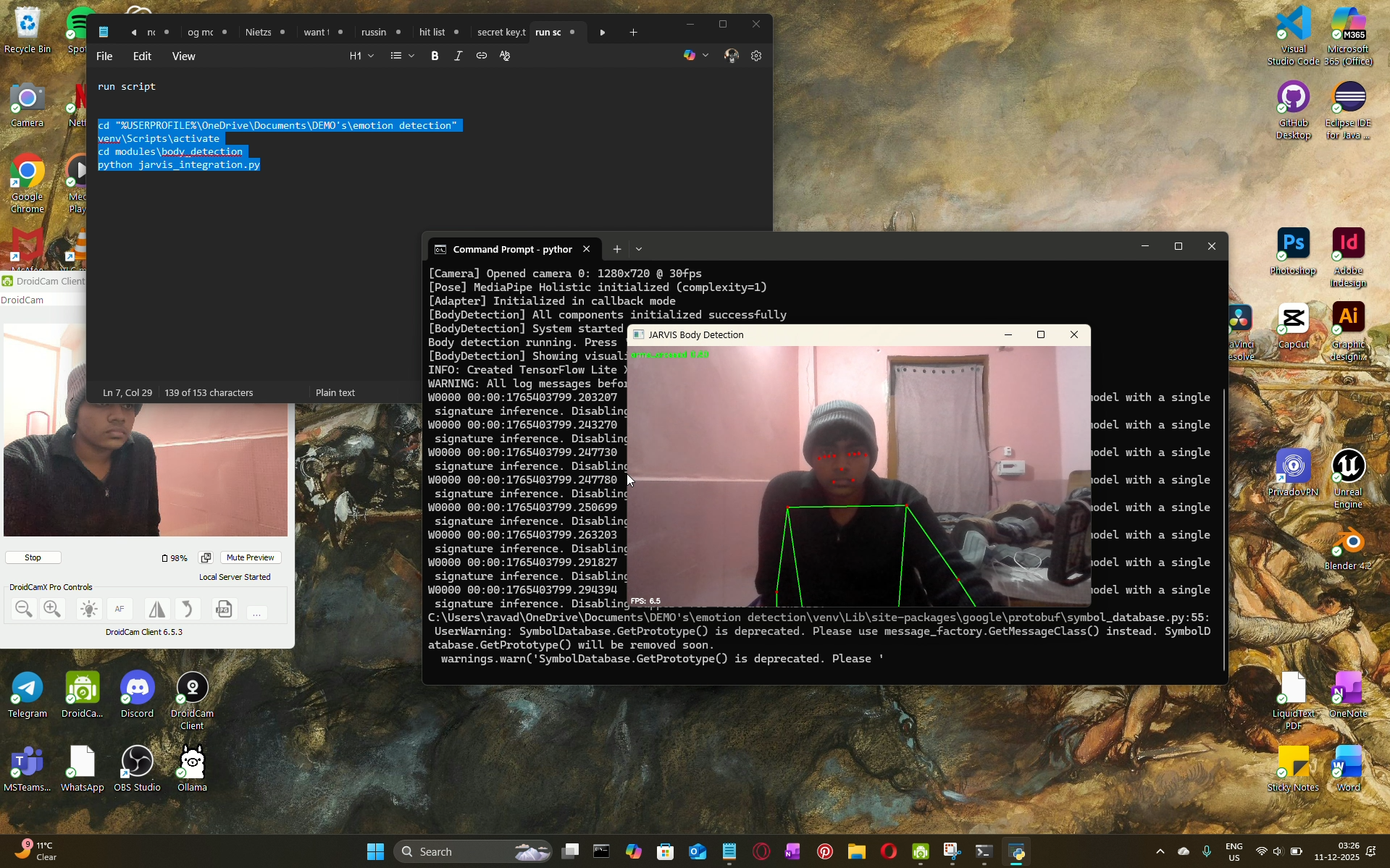
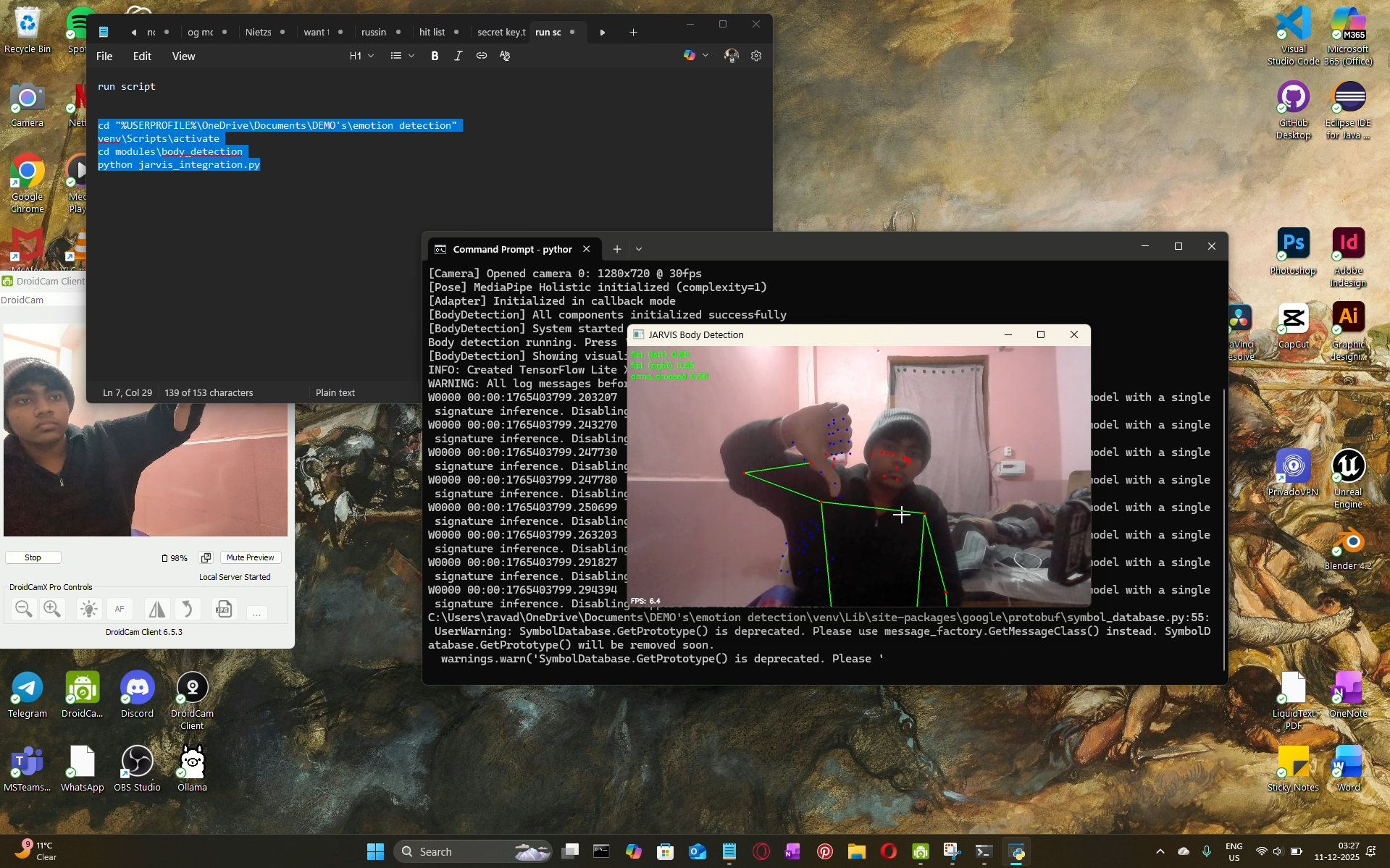
Project Overview
NETRA (also referred to as NETRAX AI) is a modular vision and perception system designed to act as the visual intelligence layer of a larger JARVIS-inspired AI assistant. The project explores how computer vision can enable natural, touch-less human–computer interaction through body movement, gestures, facial presence, and emotional cues.
Inspiration
The inspiration behind NETRA came from the idea of reducing friction between humans and intelligent systems. Traditional interfaces rely heavily on keyboards, touch, and rigid inputs. NETRA aims to move beyond that by allowing systems to see, understand, and respond to human presence in a more intuitive way. This module is intended to be a foundational component in a larger long-term project involving spatial interfaces, holographic setups, and AI-driven interaction systems.
What It Does
NETRA processes live camera input to detect and interpret human visual signals in real time. It tracks body posture, gestures, facial presence, and emotional expressions, converting raw visual data into structured signals that can be used by higher-level AI systems for interaction, control, and adaptive responses.
Capabilities
Real-time camera feed processing
Body pose and landmark detection
Hand and gesture recognition
Face detection and tracking
Facial emotion analysis (experimental)
Modular outputs that can trigger actions, UI changes, or AI responses
How We Built It
The system is built using Python as the core language. OpenCV is used for camera handling, frame processing, and visualization, while MediaPipe provides efficient and accurate landmark detection for face, hands, and body pose. The project is structured as a modular pipeline, allowing individual detection components to be developed, tested, and integrated independently. This makes NETRA scalable and suitable for long-term integration into larger AI systems.
Architecture & Technical Design
NETRA follows a layered architecture:
Input Layer – Captures live video from the camera
Vision Layer – Performs face, body, and hand landmark detection
Analysis Layer – Interprets gestures, posture, and emotional states
Integration Layer – Exposes structured outputs for external systems (JARVIS core, UI, or control logic)
This design allows NETRA to function as a standalone module or as part of a broader AI assistant ecosystem.
Challenges
Maintaining stable frame rates during real-time processing
Debugging camera inconsistencies across environments
Synchronizing multiple detection pipelines
Reducing noise and false positives in gesture interpretation
Balancing accuracy with performance on consumer hardware
Accomplishments
Built a working real-time perception system from scratch
Achieved reliable body and gesture detection using live input
Designed a modular architecture suitable for future expansion
Successfully integrated multiple vision components into a unified pipeline
What We Learned
Through this project, we gained hands-on experience with real-time computer vision systems, MediaPipe’s landmark models, OpenCV’s video pipeline, and performance optimization techniques. We also learned how to design AI modules that are extensible and integration-ready rather than one-off demos.
Future Development
NETRA will be integrated into a larger JARVIS-inspired AI system featuring spatial and holographic interfaces. Planned improvements include advanced gesture mapping, emotion-aware AI responses, multi-camera support, and deeper integration with voice and contextual intelligence systems to enable fully immersive, touch-less interaction.

Log in or sign up for Devpost to join the conversation.