-
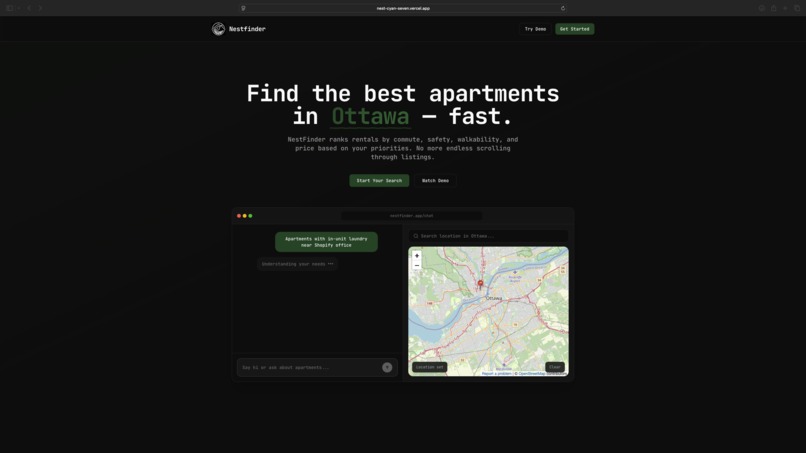
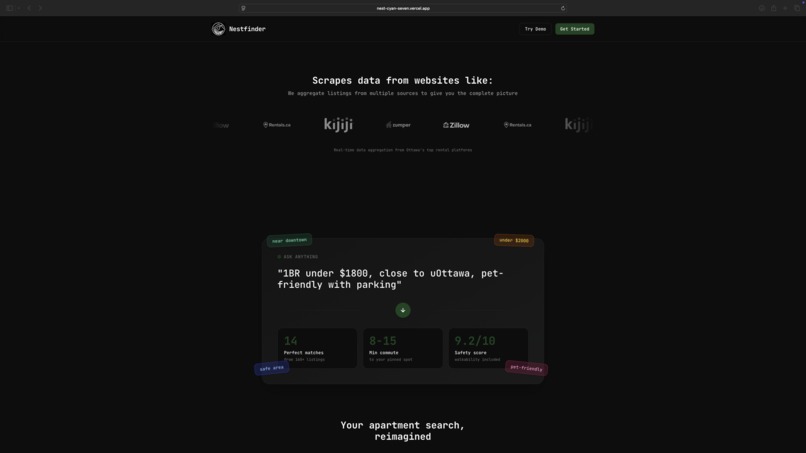
Home Page (dark mode)
-
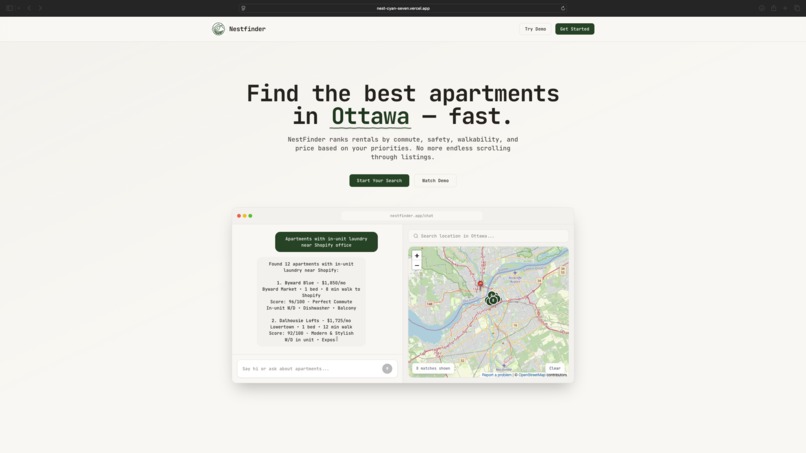
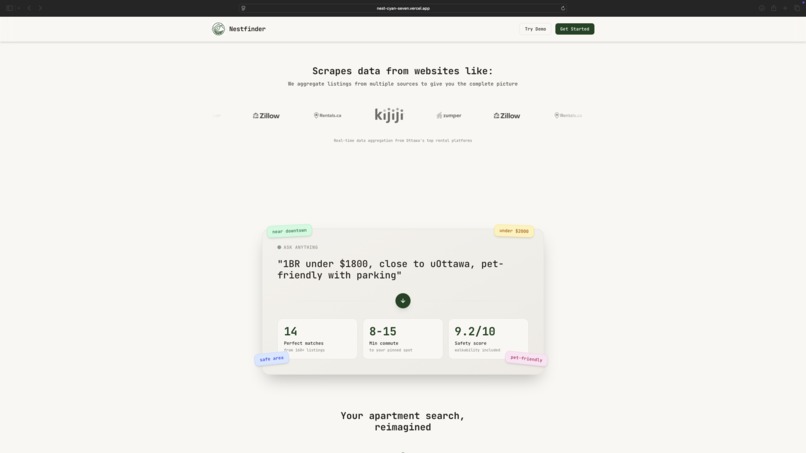
Home Page (light mode)
-
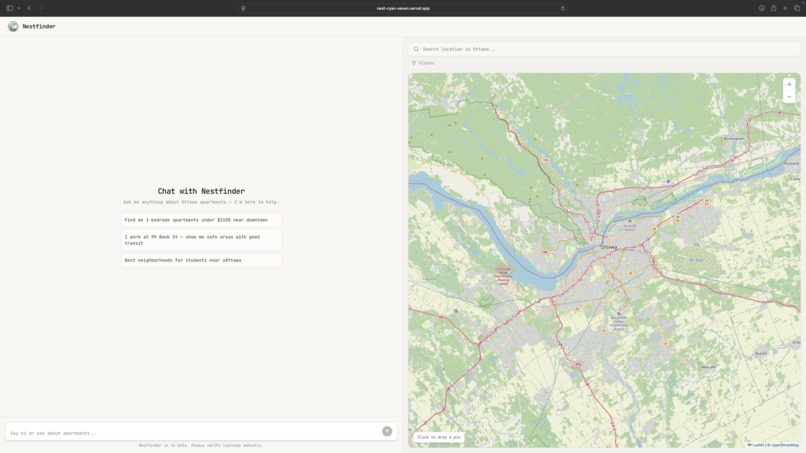
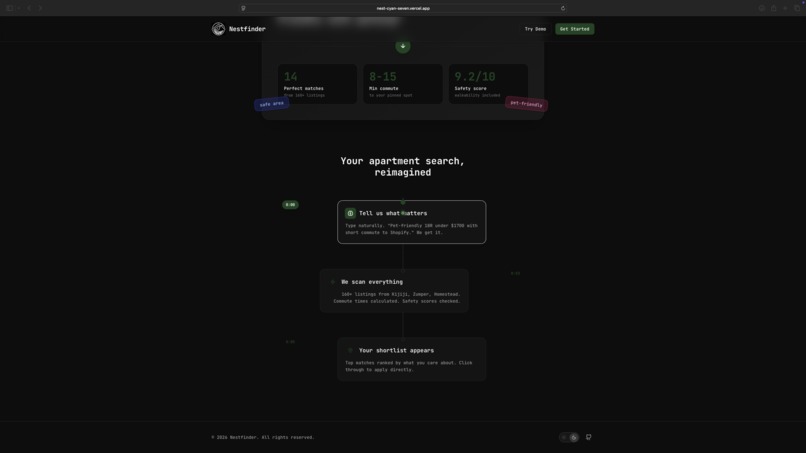
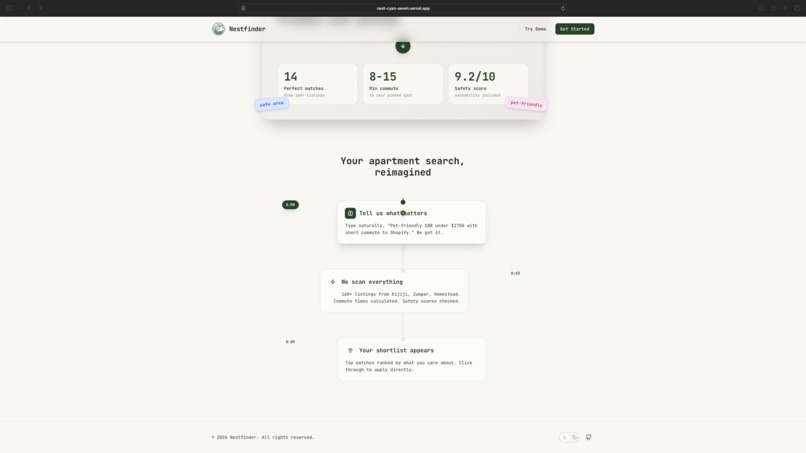
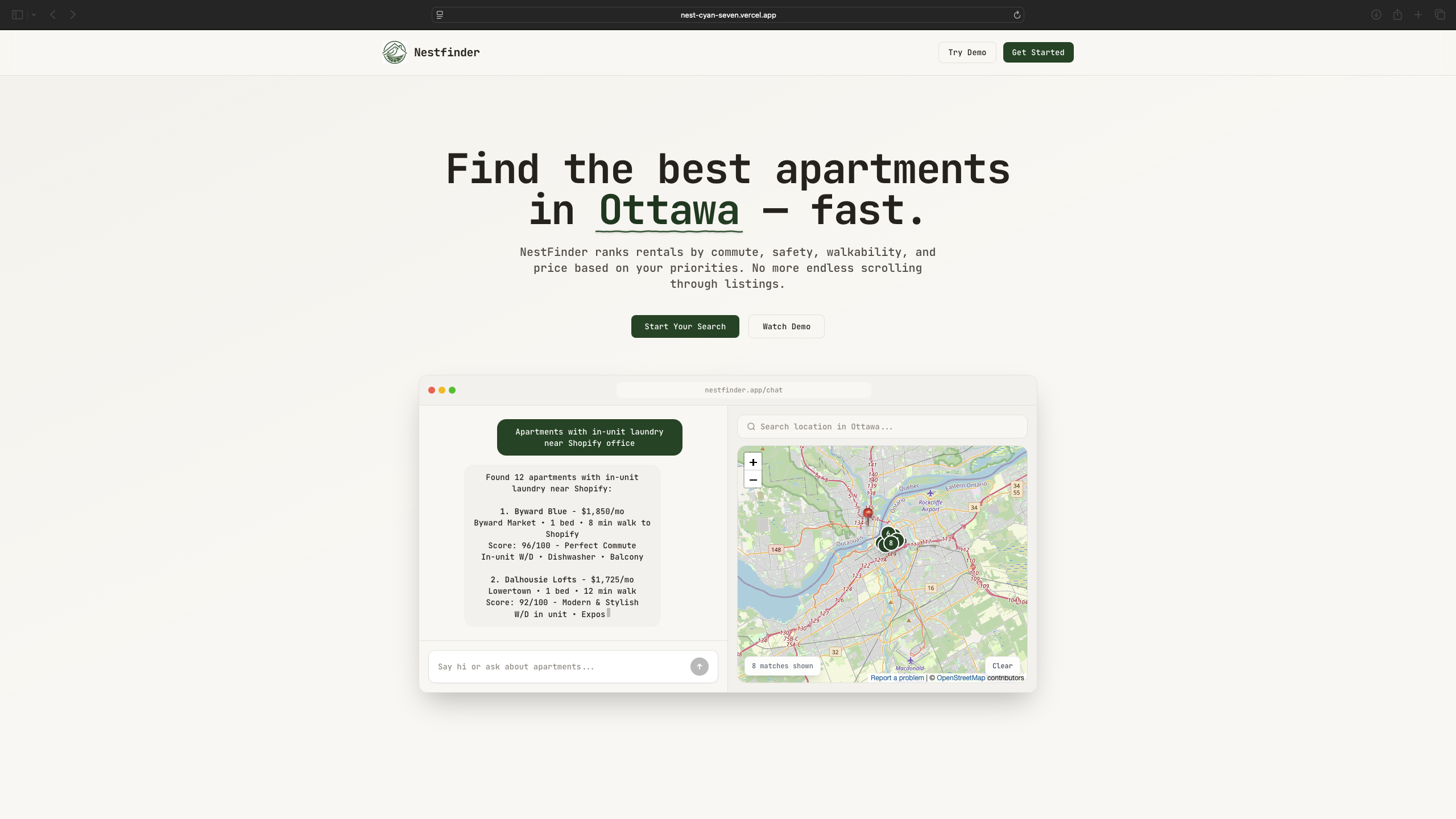
Search Chat (dark mode)
-
Search Chat (dark mode)
-
info1 (dark mode)
-
info2 (dark mode)
-
info2 (dark mode)
-
info1 (light mode)
Inspiration
Apartment hunting means juggling 50 tabs, manually checking commutes, and finding places that work for both partners. We built an AI to do this for us.
What it does
NestFinder helps you find apartments without juggling tabs by combining real listings, commute math, and preference-based ranking in one flow. You enter what you want in plain language, optionally set how heavily commute time should matter (including a couples “dual-destination” case), and NestFinder pulls real rent listings and resolves each location automatically. It calculates commute times for driving, transit, biking, and walking, then scores and ranks apartments using factors like price (including comparison to local market), neighbourhood safety, and proximity to groceries and key amenities, while also balancing both partners’ commutes for couple-friendly recommendations. Results are presented on an easy-to-visualize map, and each option includes a direct link to the original rental listing so users can jump straight to the source.
How we built it
We built NestFinder with a Next.js frontend and a Python/FastAPI backend, using Openai(SAM) for intelligent scoring, the Yellowcake API for listings, and the TravelTime API for multi-modal commute calculations (driving, transit, biking, walking). To move fast without blocking on unreliable data sources, we started with mock data to validate a stable backend flow and scoring pipeline while building the frontend UI in parallel. Once the core logic was dependable, we integrated the AI agents into the existing decision flow, then switched from mock inputs to real listing data and live commute calculations. Finally, we connected the backend and frontend end-to-end to close the project with a working, demo-ready experience.
Challenges we ran into
Yellowcake + real-world listing data reliability: inconsistent data formats, missing documentation, unpredictable responses, and poorly structured endpoints—combined with typical scraping walls (anti-bot measures, changing site structure, missing/unavailable info)—made getting clean, reliable listings a major time sink.
Frontend–backend integration: connecting the two exposed issues with heavy payloads, evolving schemas, and edge cases that required repeated contract alignment and debugging.
Team coordination under time pressure: splitting tasks evenly without overlap was difficult, and merge conflicts became common as multiple people modified shared files and interfaces.
Accomplishments that we're proud of
We delivered a complete end-to-end product within the hackathon window, and the core pipeline is implemented: we can pull listings, resolve locations, compute real multi-modal commute times, and rank results based on user preferences while optimizing specifically for couples’ dual commutes. We are also proud that the experience is genuinely innovative: users can enter a natural-language chat prompt and adjust the weighting of commute time (including a couples “dual-destination” case) to produce decision-ready recommendations instead of manually comparing dozens of tabs. Finally, we are especially proud of successfully integrating \textbf{SAM} and the \textbf{Yellowcake API}—our primary technical goals—despite the data and integration complexity, and of completing the project to a level of polish that is clearly presentable for demo and judging.
What we learned
Multi-agent AI architecture. How to coordinate multiple agents and responsibilities in a cohesive workflow, including event-driven components.
Geocoding + travel-time APIs. Translating addresses into coordinates and turning location data into commute-time insights that actually affect recommendations.
Web scraping via APIs and real-world challenges. Using the Yellowcake API effectively, handling data gaps/inconsistencies, and learning why “live” data pipelines are harder than a one-time dataset snapshot.
Multi-constraint optimization. Ranking listings while balancing competing constraints (budget, commute, neighborhood signals, amenities) instead of optimizing for a single metric.
Hackathon tradeoffs. Where to move fast versus where to invest in structure—maintaining code quality, integration stability, and clear interfaces under tight deadlines.
What's next for NestFinder
Real-time listing data (in progress). We currently scrape listings via the Yellowcake API and run the app on a fixed snapshot dataset. We’ve started implementing runtime scraping to refresh listings live for a more accurate, up-to-date dataset, and the next step is completing and hardening that pipeline.
More accurate search results (refining relevance). Filters already exist; the focus is improving match quality—better ranking, fewer false positives, and stronger alignment to user intent.
Neighborhood + commute scoring with SAM (enhancing). SAM-based scoring is integrated; we’re improving stability, weighting, and practicality for commute-to-work fit.
Landlord “Post a Rental” (new). Enable direct listing submissions with validation/moderation to maintain data quality.
Built With
- css
- next.js
- python
- react
- solace-agent-mesh
- typescript
- yellowcakeapi


Log in or sign up for Devpost to join the conversation.