

Inspiration
Antitrust and competition-law decisions published every year by the European Commission, national authorities, and courts often reveal that thousands of companies — especially SMEs — were overcharged by cartels or abusive market practices. Most of these victims never claim the damages they are entitled to, simply because identifying themselves in a 200-page legal decision, building a case, and funding a multi-year litigation is out of reach.
On the other side of the table, Third-Party Litigation Funding (TPLF) funds are constantly looking for solid follow-on cases to invest in, but their sourcing process is still painfully manual: read the decision, extract the cartel's perimeter, list candidate buyers, run financial due diligence, and finally write an investment memo.
We wanted to bridge that gap. Nesmos.ai was born from a simple idea: an antitrust decision is a structured signal — an AI agent should be able to read it, understand who was harmed, and turn it into a ranked, fundable investment shortlist.
What it does
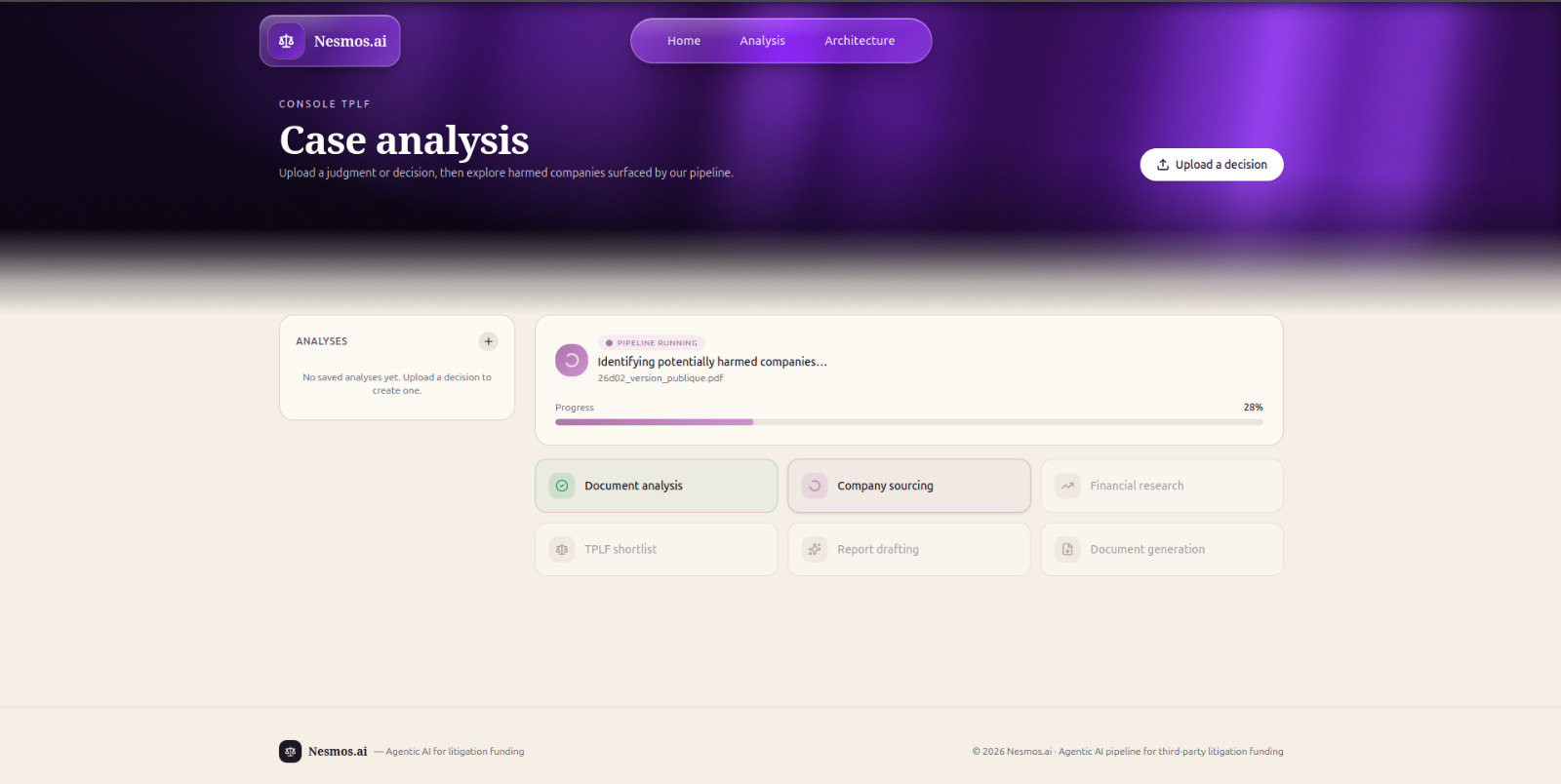
Nesmos.ai is an agentic AI pipeline for TPLF due diligence. From a single competition-law decision (PDF or text), it produces a complete investment memorandum in a few minutes:
- Reads the decision and extracts a strict, schema-validated
judicial_contract(infraction type, affected markets, geographic scope, damage period, sanctioned parties, buyer profiles, legal findings, NACE codes, appeal status, etc.). - Sources candidate companies that match the affected buyer profile described in the decision.
- Runs parallel deep research on each candidate (revenue, market cap, ticker/ISIN, credit rating, legal team, exposure to the cartelized market, corporate continuity) using grounded web search.
- Scores and ranks each company on its TPLF attractiveness (exposure, financial resilience, legal standing, procedural risks).
- Writes a senior-grade investment memorandum — executive summary, legal mechanics of the infraction, top-3 targets, risk factors, and a final recommendation — and exports it as a clean
.docxready for an investment committee.
The user just uploads a decision; Nesmos.ai returns a shortlist of fundable claimants and the memo to back it up.
How we built it
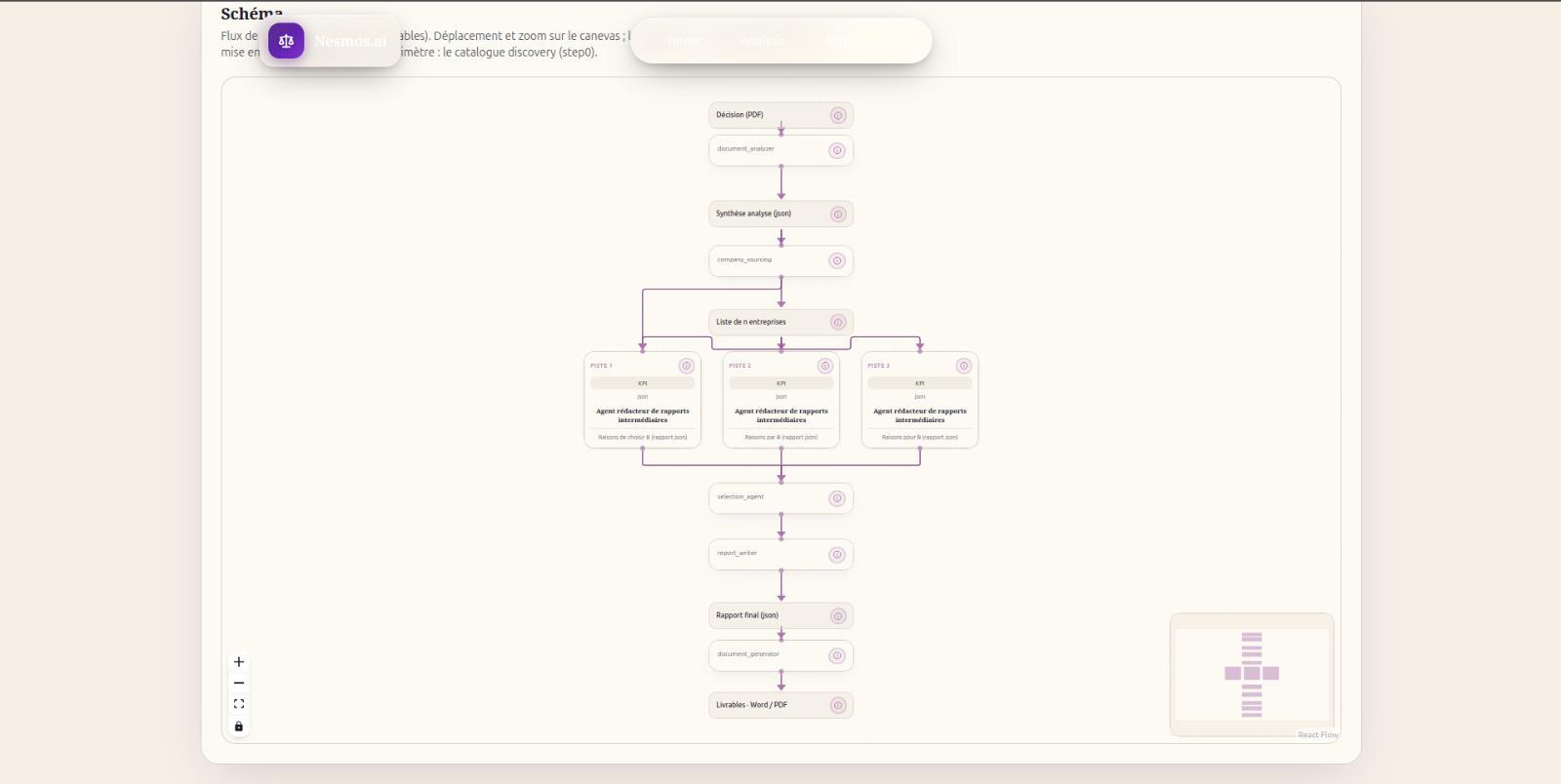
- Backend: Python, FastAPI, LangGraph and LangChain. The pipeline is modeled as a stateful graph of agentic nodes (
document_analyzer,company_sourcing,company_research,judge,report_writer) communicating through a strongly-typedPipelineState. - LLM layer: Google Gemini via
langchain-google-genai, used both with structured outputs (Pydantic schemas likeJudicialContract,CompanyReport,FinalReport) and as a ReAct agent with a custom Gemini grounding search tool for live, citable web research. - Caching: A content-hash-based LLM cache so that re-running an analysis on the same decision is instant and free.
- Document generation: A
.docxbuilder that turns theFinalReportPydantic object into a polished investment memo. - Frontend: React 19 + TypeScript, TanStack Start and TanStack Router (SSR, file-based routing), Tailwind CSS 4, and shadcn/ui components. The architecture page visualizes the pipeline graph live, and the analysis page streams the agents' progress to the user.
- Deployment: Vite 7 build targeting Cloudflare Workers through
@cloudflare/vite-pluginand Wrangler.
Challenges we ran into
- Hallucination is not an option in legal tech. A wrong fine amount or a fabricated company link could invalidate a multi-million-euro case. We had to enforce a strict "if it's not in the document, it's
null" policy at the prompt, schema, and post-validation level — and resist every temptation of the model to "complete" missing fields. - Grounding the research agent. Letting an LLM browse the web freely produces beautiful but unverifiable narratives. Wrapping Gemini in a ReAct loop with a single grounding-search tool, and forcing every data point to come from an actual tool call, was much harder than expected.
- Schema engineering. The
judicial_contractschema went through many iterations: too loose and the downstream nodes hallucinate; too strict and Gemini refuses to output anything. Finding the right "shape of truth" for an antitrust decision was a project on its own. - Parallelism and state. Running company research in parallel through LangGraph's map pattern, while keeping a deterministic, cacheable, and resumable pipeline state, required several rewrites.
- Latency vs. depth. Investment-grade memos demand depth, but a hackathon demo demands speed. We invested heavily in caching, smart fan-out, and progressive UI streaming to keep both.
Accomplishments that we're proud of
- A fully working end-to-end pipeline: from raw decision text to a downloadable, senior-quality investment memorandum.
- A strict anti-hallucination architecture combining tool-grounded agents, Pydantic-validated structured outputs, and explicit
null-when-unknown policies. - A parallel multi-agent research layer that performs deep due diligence on several companies at once with reproducible, cached results.
- A clean, modern UI built on the latest React + TanStack Start stack, deployable to the edge on Cloudflare Workers.
- Turning a complex, niche fintech problem (TPLF sourcing) into a product that a non-lawyer can actually use.
What we learned
- How to design agentic pipelines as graphs instead of monolithic prompts — and how much more reliable, debuggable, and cacheable that makes them.
- The real craft of prompt engineering for high-stakes domains: precise role framing, explicit forbidden behaviors, schema-anchored outputs, and aggressive "null-by-default" defaults.
- How to combine structured output models (
with_structured_output) and tool-using ReAct agents in the same LangGraph application. - A lot about EU competition law, follow-on damages, Article 101/102 TFEU, Directive 2014/104, and how the TPLF industry actually evaluates a case.
- The TanStack Start + Cloudflare Workers stack — a genuinely fast and elegant way to ship a modern React app to the edge.
What's next for Nesmos.ai
- Broader source ingestion: directly connecting to official feeds (European Commission, Autorité de la concurrence, Bundeskartellamt, CMA, etc.) so new decisions are analyzed automatically as they are published.
- Multi-jurisdiction support: extending the pipeline beyond EU/French competition law to UK, US antitrust, and sector-specific regulators.
- Claimant outreach: turning the ranked shortlist into a contact-ready CRM layer, with tailored claim letters and damages estimates per company.
- Quantitative damages modeling: integrating econometric overcharge estimation models (rather than relying only on the percentages stated in the decision).
- Funder workspace: collaborative dashboards for TPLF funds to track, score, and progress dossiers from sourcing to settlement.
- Compliance & auditability: full citation trails for every claim in every memo, so each output is defensible in front of an investment committee — and, eventually, a court.
Built With
- fastapi
- gemini
- langgraph
- lovable
- python
- typescript

Log in or sign up for Devpost to join the conversation.