-
-
Nerdle
Inspiration
Perplexity (and all Big Boy LLMs) are BAD at Nerdle
Nerdle is a word game similar to Wordle, but instead of guessing words, players guess arithmetic equations. We used reinforcement learning to train large language models (LLMs) to solve Nerdle. The project combines game theory, reinforcement learning fine-tuning (GRPO - Group Relative Policy Optimization), and modern web technologies to create an interactive AI agent that can play Nerdle autonomously.
What it does
This project implements a complete system for training and deploying LLMs to play Nerdle:
1. RL Training Pipeline: Uses Unsloth AI and GRPO to fine-tune Qwen models (Qwen3-0.6B) on Nerdle game data. The training incorporates a sophisticated reward system based on Nerdle's color feedback (green for correct position, purple for correct character wrong position, black for incorrect).
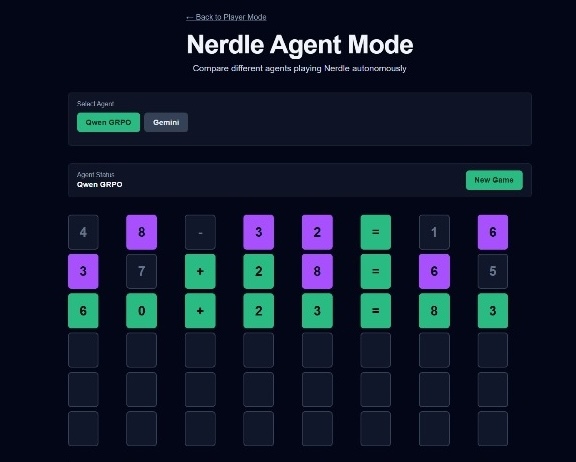
2. Interactive Frontend: A Next.js web application that allows users to:
- Play Nerdle manually with a clean, intuitive interface
- Watch AI agents play autonomously in "Agent Mode"
- Compare two different agent implementations side-by-side
3. Dual Agent System:
- Qwen GRPO: The Qwen model fine-tuned with GRPO (Group Relative Policy Optimization) using our custom reward system. This RL-trained model learns to play Nerdle through reinforcement learning, optimizing for correct guesses and efficient solving.
- Gemini: An LLM-based agent that uses the Gemini API directly to generate intelligent guesses, providing a baseline comparison against the RL-fine-tuned approach.
4. Reward System: Implements a configurable reward function that:
- Awards 3 points for green (correct position), 1 point for purple (correct character), 0 for black
- Penalizes invalid equations with -30 points
- Rewards correct solutions with +30 points
- Applies exponential decay: R = points * 1.1^(-k) where k is the attempt number
5. Real-time Simulation: Agents include realistic thinking times sampled from normal distributions (Qwen GRPO: mean 3s, Gemini: mean 7s) to simulate natural behavior.
How we built it
Backend & Training: • Used Unsloth AI for efficient LLM fine-tuning with LoRA (Low-Rank Adaptation) • Implemented GRPO (Group Relative Policy Optimization) training pipeline in Jupyter notebooks to fine-tune Qwen models • Created dataset generation script that simulates Nerdle games with 4-try histories • Built Python Flask backend service for Qwen GRPO inference using HuggingFace Transformers • Integrated Gemini API for baseline agent comparison • Implemented validation and retry logic to ensure only valid, balanced equations are returned
Frontend: • Built with Next.js 14 and React for the interactive game interface • Created TypeScript components for game logic, tile states, and keyboard interaction • Implemented agent mode with real-time visualization of AI decision-making • Added agent selector UI to switch between Qwen GRPO and Gemini agents • Implemented normal distribution sampling for realistic agent thinking times
Game Logic: • Implemented Nerdle classic rules: 8-character equations, 6 attempts maximum • Created equation pool generator that produces all valid 8-character balanced equations • Built feedback system that evaluates guesses and provides color-coded tile states • Implemented candidate filtering system that works with both agents to validate guesses
Integration: • Connected Next.js API routes to Python backend via proxy • Implemented comprehensive logging at all layers for debugging • Added source tracking to distinguish LLM outputs from fallback functions • Created health check endpoints and error handling throughout the stack
Challenges we ran into
1. Equation Validation: Ensuring the LLM generates valid, balanced arithmetic equations was crucial. We had to implement robust validation that checks equation syntax, mathematical correctness, and format compliance (exactly 8 characters, one equals sign, etc.).
2. Reward Function Design: Designing the reward system to properly guide the LLM's learning required careful balancing. We needed rewards that encourage both correctness and efficiency (solving in fewer attempts), leading to the exponential decay formula.
3. Frontend-Backend Integration: Managing the connection between the Next.js frontend and Python Flask backend, especially for real-time inference, required careful handling of CORS, API routing, and error states.
4. Model Inference Reliability: The LLM sometimes generated invalid equations or outputs that needed parsing. We implemented retry logic with multiple attempts and validation checks before accepting a guess.
5. Agent Behavior Simulation: Implementing realistic thinking times using normal distributions while maintaining smooth UX required careful async handling and state management in React.
6. Dataset Generation: Creating meaningful training samples with proper game histories required implementing a solver that could generate valid game scenarios with 4 previous attempts.
Accomplishments that we're proud of
1. Dual Agent Architecture: Successfully implemented and integrated two completely different solving approaches (RL-fine-tuned Qwen GRPO vs. Gemini API) in a single interface, allowing for direct comparison between reinforcement learning fine-tuning and general-purpose LLM performance.
2. Complete End-to-End System: Built a full-stack solution from dataset generation → model training → deployment → interactive frontend, demonstrating the entire ML lifecycle.
3. Sophisticated Reward System: Implemented a nuanced reward function with exponential decay that balances accuracy and efficiency, encouraging the model to solve puzzles in fewer attempts.
4. Robust Validation Pipeline: Created comprehensive equation validation that ensures game integrity, with automatic retry mechanisms and fallback strategies.
5. Interactive UI/UX: Developed a polished, responsive web interface that makes it easy to play manually or observe AI agents, with real-time feedback and visualization.
6. Realistic Agent Simulation: Added thinking time distributions that make AI agents feel more natural and human-like, rather than instant responses.
7. Extensible Architecture: Built a modular system that allows easy swapping of models, agents, and reward configurations.
What we learned
1. GRPO Fine-Tuning: Gained deep understanding of Group Relative Policy Optimization for RL-based LLM fine-tuning, including reward modeling and training loop configuration.
2. Unsloth AI Framework: Learned to leverage Unsloth AI for efficient LLM training with LoRA, reducing memory requirements and training time while maintaining model quality.
3. Game Theory in Nerdle: Explored optimal strategies for Nerdle, including filtering techniques, candidate space reduction, and the importance of initial guesses.
4. Full-Stack ML Integration: Understood the challenges and solutions for deploying ML models in production, including API design, error handling, and frontend-backend communication.
5. Reward Shaping: Learned how reward function design critically impacts RL training, requiring careful consideration of what behaviors to encourage (efficiency, correctness) and discourage (invalid outputs, excessive attempts).
6. TypeScript/React Patterns: Improved skills in building complex interactive UIs with React hooks, state management, and async operations.
7. Model Inference Optimization: Gained experience in optimizing LLM inference pipelines, including tokenization, chat templates, temperature sampling, and output parsing.
What's next for Nerdle
1. Improved Model Training: Train on larger datasets (extend beyond 500 samples) and experiment with different reward function parameters to improve agent performance.
2. Advanced Solving Strategies: Enhance the greedy solver with more sophisticated heuristics, such as information-theoretic approaches that maximize expected information gain per guess.
3. Model Comparison Dashboard: Add analytics to compare Qwen GRPO (RL-fine-tuned) vs. Gemini API performance metrics (solve rate, average attempts, success distribution) to evaluate the effectiveness of GRPO fine-tuning.
4. Multi-Agent Play: Implement head-to-head mode where multiple agents compete on the same puzzle.
5. Training Data Augmentation: Generate more diverse game scenarios, including different difficulty levels and edge cases.
6. Transfer Learning: Experiment with pre-training on larger equation datasets before fine-tuning on Nerdle specifically.
7. Better Initial Guesses: Research and implement optimal first-guess strategies beyond the hardcoded initial guess.
8. Real-time Training: Explore online learning approaches where the model can improve from user gameplay data.
9. Mobile Optimization: Adapt the interface for mobile devices to enable on-the-go gameplay.
10. Community Features: Add leaderboards, sharing of solved puzzles, and collaborative solving modes.
Built With
- python
- typescript
- unsloth

Log in or sign up for Devpost to join the conversation.