-
-
Landing Page
-
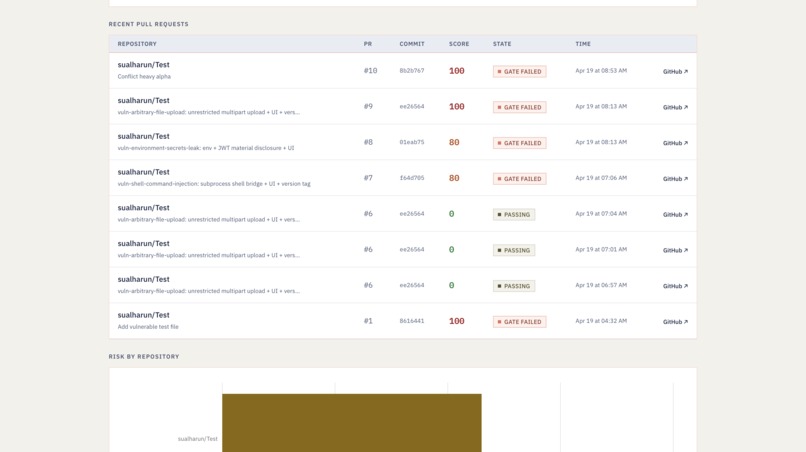
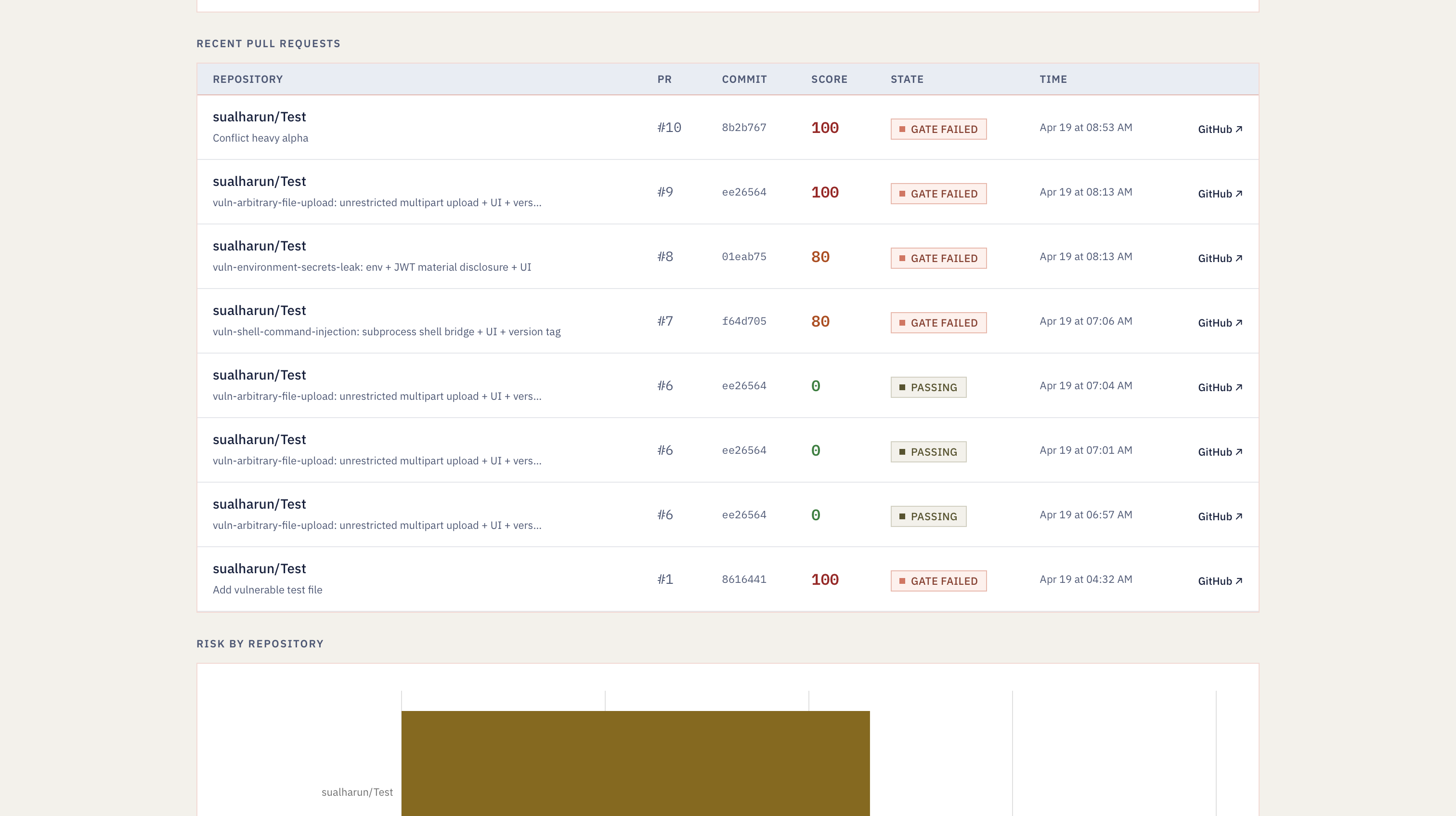
Pull Request Tracking
-
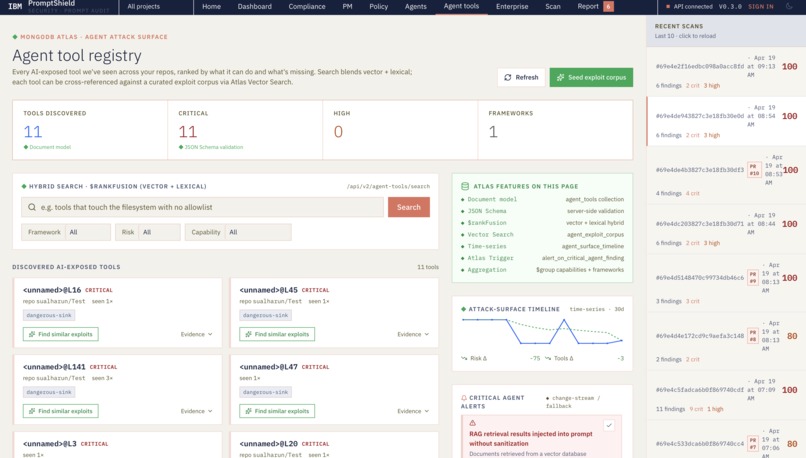
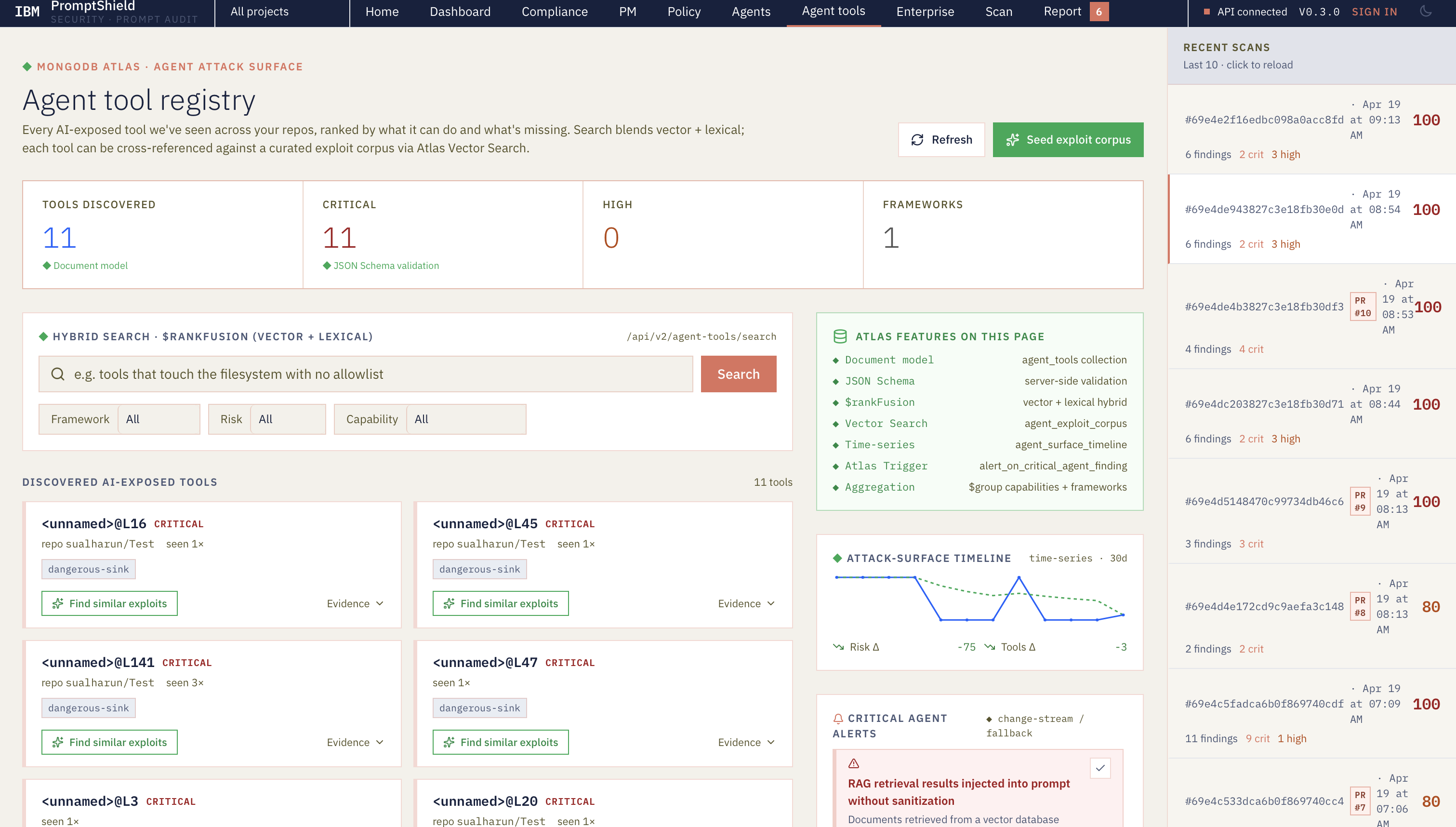
Dashboard
-
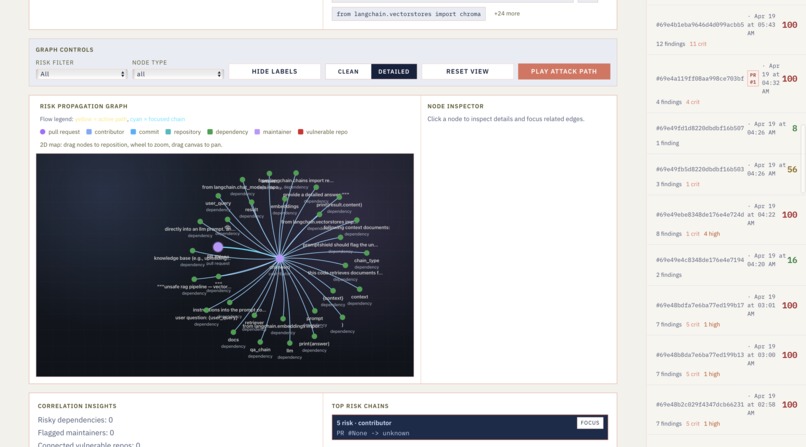
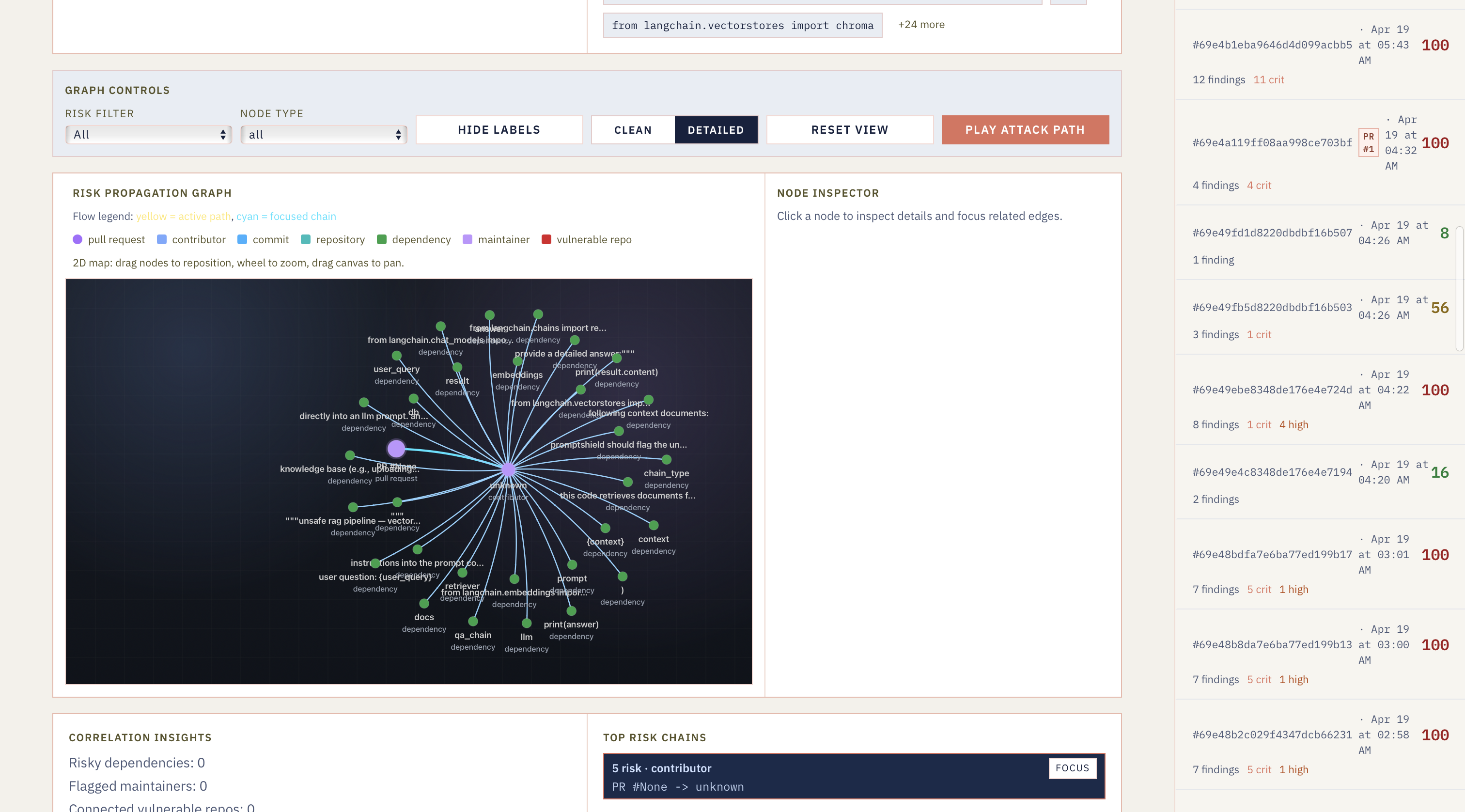
Repo Risk Graphing
-
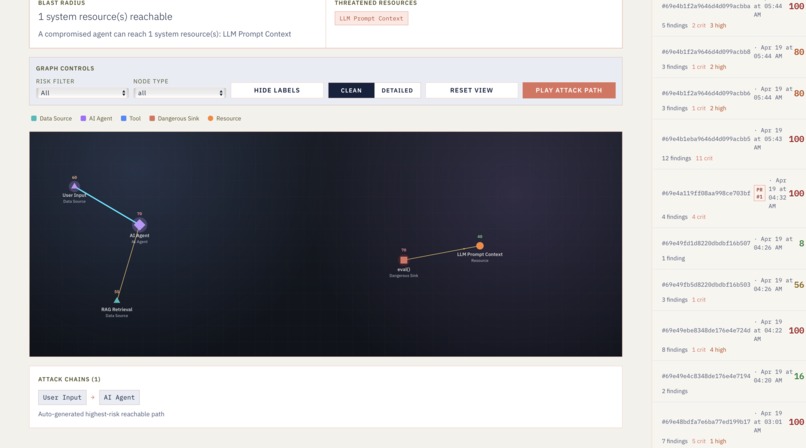
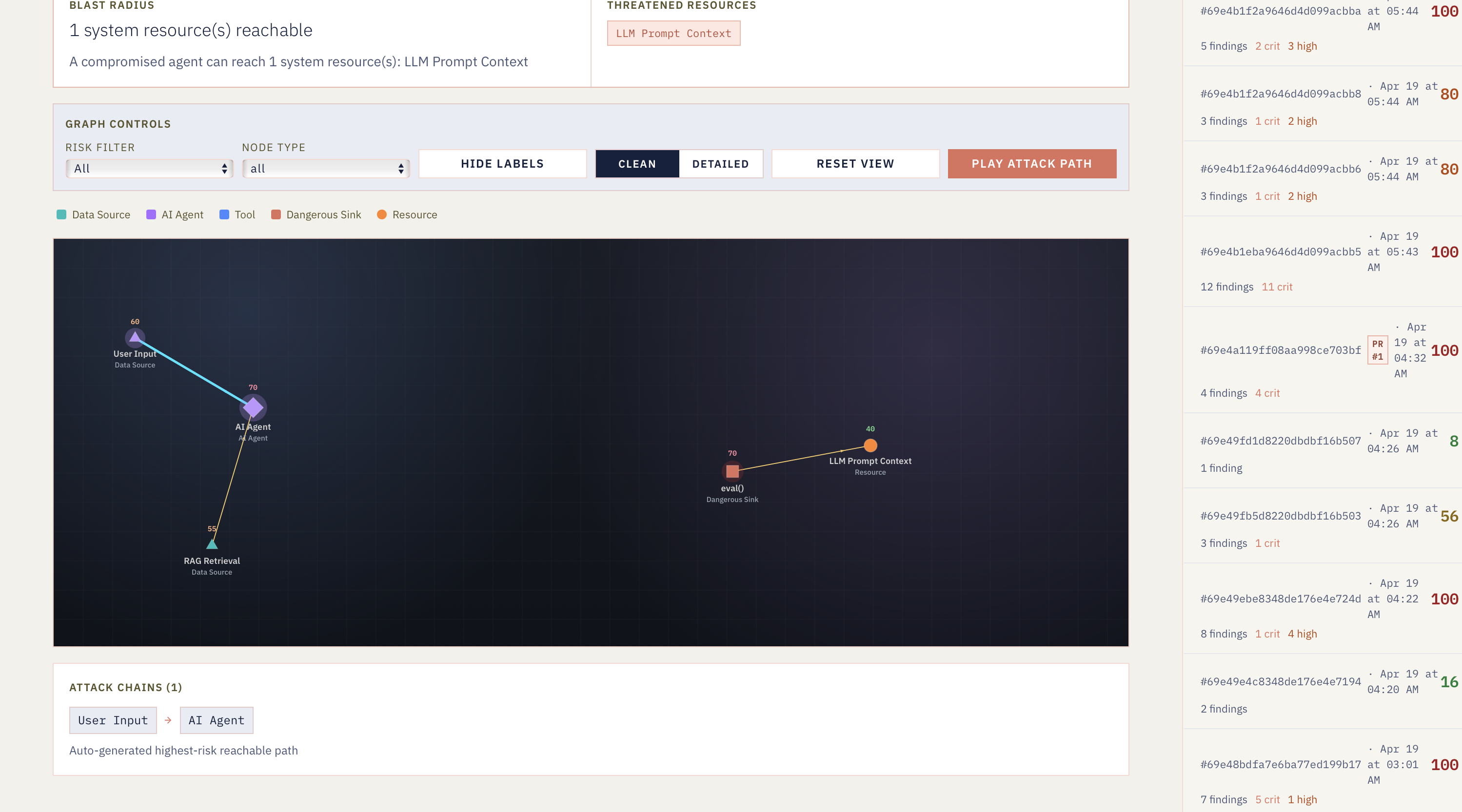
Repo Specific Risk Visualization

Inspiration
The first thing we did at the start of the hackathon was sketch out what's different about AI security in 2026. What stood out is that almost every tool in the space today is shifted right: it sits in front of a deployed model at runtime, watching prompts go in and responses come out. Useful, but late. By the time a request hits a runtime guardrail, the dangerous function is already written, merged, and running in production.
Very few tools are shifted left, meaning they run during code review and flag the risky pattern before it ever ships. That's the gap. LLMs don't just generate text anymore; they call functions that run shell commands, edit files, and query databases. A model getting tricked used to mean a bad chatbot reply. Now it can mean a wiped production database. And the place to catch that is in the pull request, not in a runtime filter after the fact.
What it does
PromptShield is a security scanner that reviews pull requests for AI agent vulnerabilities. You connect it as a GitHub App or paste code directly, and it runs three layers in parallel: regex-based static rules, AST dataflow taint tracking, and a Gemini 2.5 semantic auditor. Between them, they're looking for three things:
- Prompt injection, whether direct, indirect, or paraphrased via vector search.
- Dangerous agent tool surfaces, like @tool functions that can run shell or SQL with unvalidated LLM-controlled arguments.
- Unsafe LLM output handling, where a model's reply gets piped into exec, a shell, a raw SQL query, or innerHTML.
Every finding comes back with a CWE number, an OWASP LLM Top 10 (2025) category, an evidence snippet, and a one-sentence fix. On the PR side, it posts inline comments, creates a Check Run that fails above a risk threshold, and writes everything into MongoDB Atlas so you can search and trend agent-tool exposure across repos. The dashboard on top of Atlas shows a live feed of scans, a hybrid search bar across findings, and a 7-day risk timeline so you can see whether a repo is getting better or worse.
How we built it
FastAPI + Python on the backend, React + Vite + Tailwind on the frontend. AI is Google Gemini 2.5 Flash via Vertex AI, with Voyage AI (voyage-3-large) for embeddings.
MongoDB Atlas is the heaviest piece of infrastructure in the project, and it's not just storing documents:
- $vectorSearch across a prompt corpus and a curated exploit corpus, so new code gets matched against known jailbreaks and agent-exploit patterns.
- $rankFusion for hybrid vector + lexical search on the tool registry.
- A time-series collection with $setWindowFields for rolling averages of attack-surface growth across a repo.
- A Database Trigger that uses change streams to fan out critical findings into an alerts collection, so alerting happens at the DB layer instead of in app code.
- A second trigger that redacts secrets server-side on insert, as a backstop to the Python redaction on the way in. Every one of those is load-bearing, not decoration. Ripping any of them out would mean reimplementing it in Python.
Challenges we ran into
We faced some debugging issues with Atlas Triggers. The docs tell you to call context.services.get("mongodb-atlas"), which works if your data source is literally named that. Ours was named "main", so everything silently failed with Cannot access member 'db' of undefined, which doesn't obviously point at a config problem. We also hit a smaller bug where $rankFusion returns a nested object on real Atlas but a plain number on mongomock, which meant NaN in the UI until we normalized it.
The GitHub App side was its own mess. Webhooks from GitHub don't reach localhost, so we wrote helper scripts around ngrok and smee-client (github_webhook_url.sh, ngrok_http_8000.sh). Then we spent real time chasing why deliveries were arriving as 2xx but nothing was posting back to the PR. Turned out to be the private-key path.
Accomplishments that we're proud of
The numbers held up. Our three-layer benchmark runs 151 labeled prompts through static rules, a TF-IDF classifier, and the live API. The ML layer hit 0.972 F1 under cross-validation, and on held-out edge cases the full API got 100% recall where a Gemini-only baseline was at 50%. Redaction is defense-in-depth: Python strips secrets before persistence, an Atlas trigger strips them again on insert, and both write to audit_logs with a _written_by field so we can prove which layer caught what.
And the full chain works end-to-end. A pull request that adds something like @tool def run_shell(cmd): subprocess.run(cmd, shell=True) comes back as a critical TOOL_PARAM_TO_SHELL finding — CWE-78, OWASP LLM06, a dataflow trace, and a Gemini-generated fix, all on the PR itself. Behind it, a single scan lights up five Atlas surfaces at once: scan in, change-stream trigger writes an alert, tool registry updates, time-series point lands, and the vector embedding refreshes for hybrid search.
What we learned
We got hands-on with a lot of tooling we hadn't touched before. Gemini via Vertex AI was new; getting strict JSON output across eight specific finding types took a few iterations to feel solid. MongoDB Atlas turned out to be a lot more than a document store: triggers, change streams, time-series collections, $vectorSearch, and $rankFusion all live behind the same connection string, and once we committed to the platform a lot of logic we'd normally write in Python moved to the DB layer.
On the process side, two things helped the most. Mongomock fallbacks kept the test suite under 30 seconds — critical when you're making a change every few minutes. And leaning on a labeled benchmark from day one (151 prompts, held-out edge cases, F1 instead of accuracy) kept us from shipping changes that felt like improvements but weren't.
What's next for PromptShield
- Inter-procedural dataflow so taint follows across function boundaries and class fields, instead of giving up at the function edge.
- A real JavaScript/TypeScript analyzer. JS is regex-only today, which is a big gap given how much agent code is being written in Node.
- Treat .cursor/rules/*, CLAUDE.md, and AGENTS.md as first-class indirect-injection surfaces.
- Expand the agent-exploit corpus past the current seed set by ingesting real CVEs and LangChain/LlamaIndex issue threads.







Log in or sign up for Devpost to join the conversation.