-
-
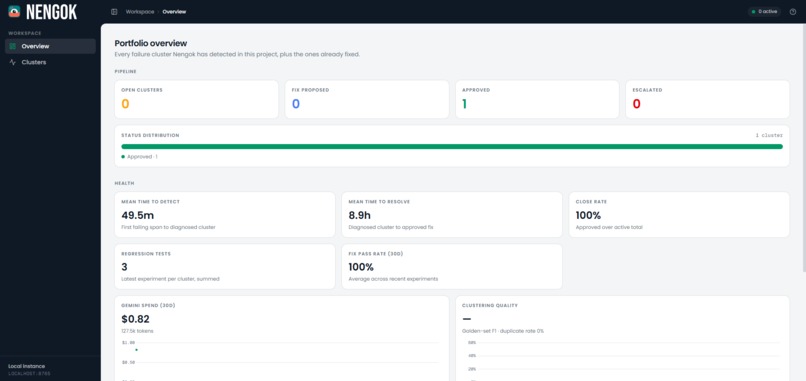
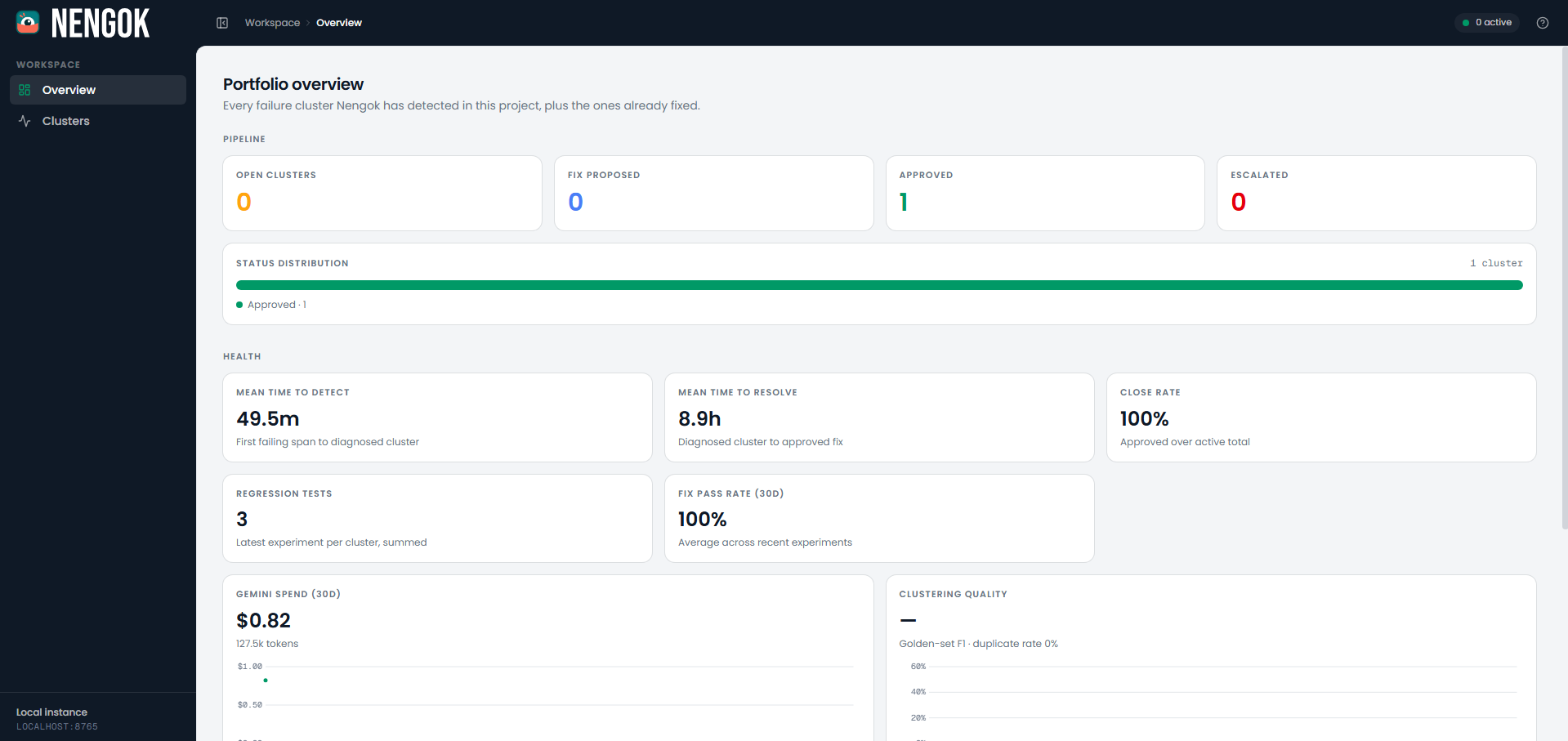
Nengok Dashboard - Overview Page
-
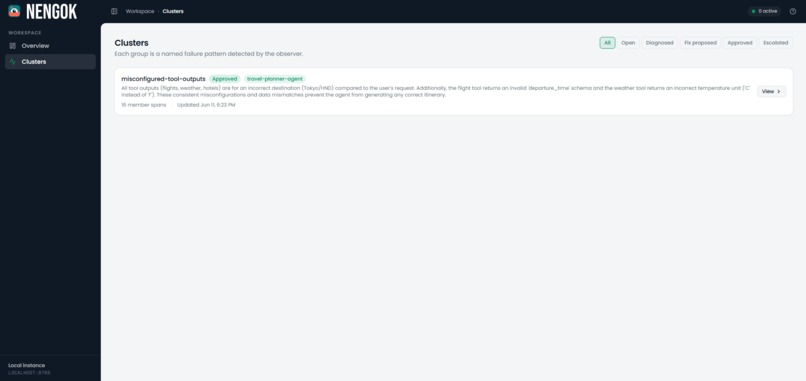
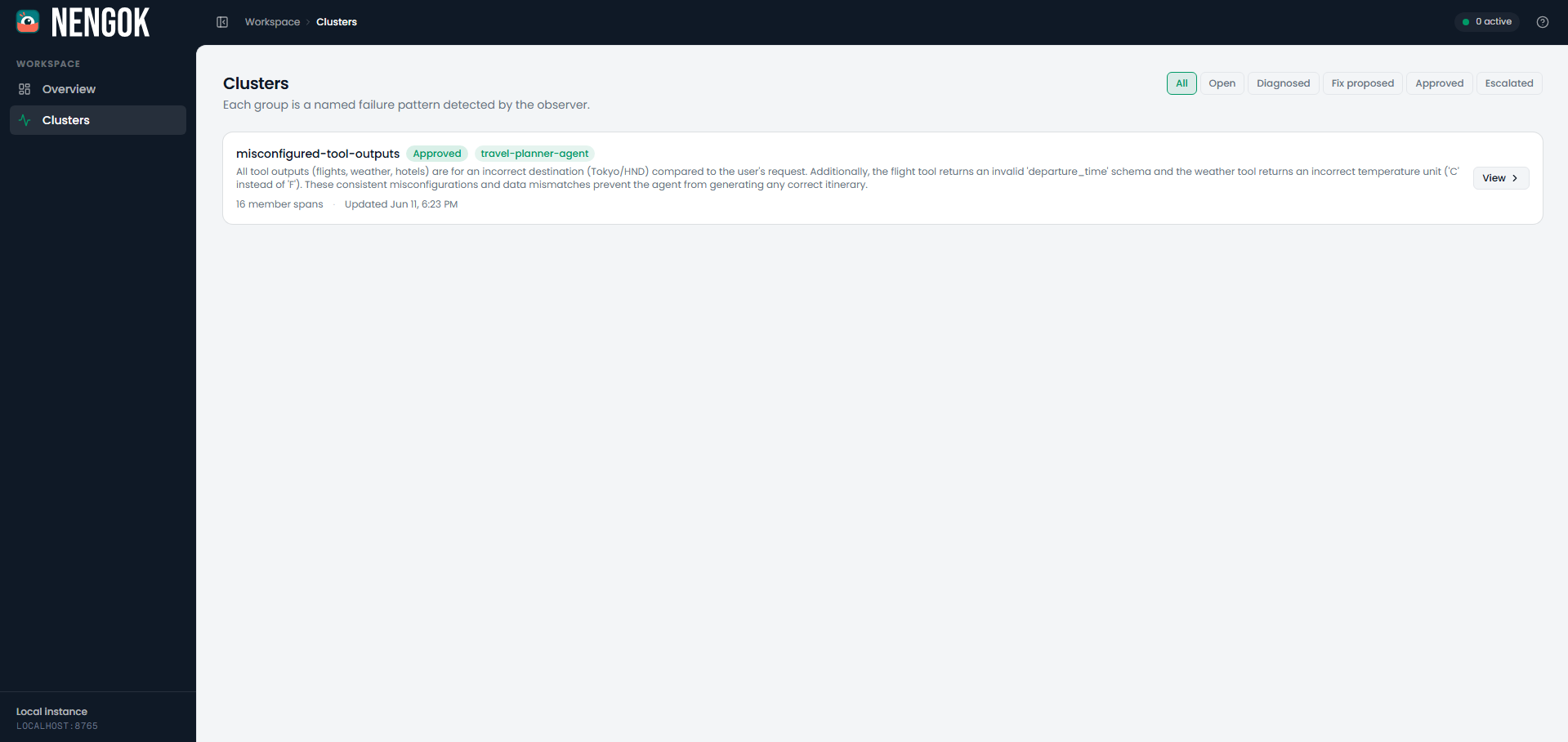
Nengok Dashboard - Clusters Page
-
 GIF
GIF
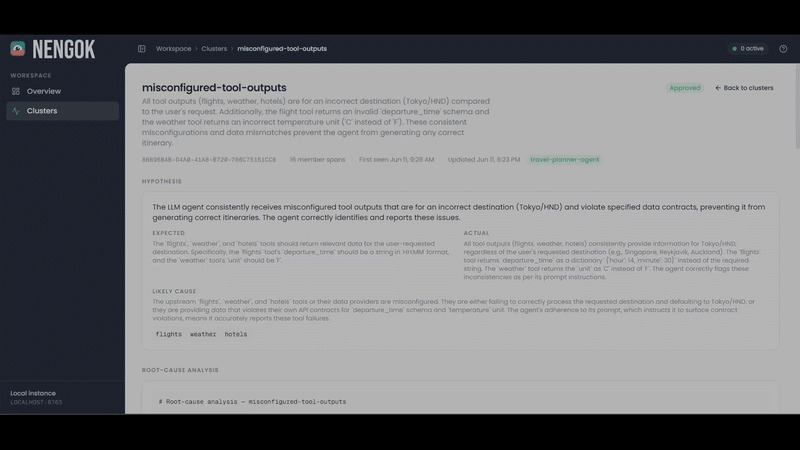
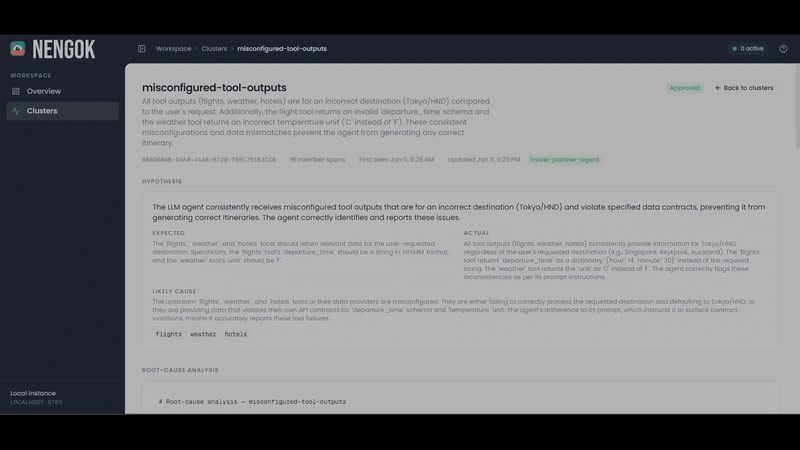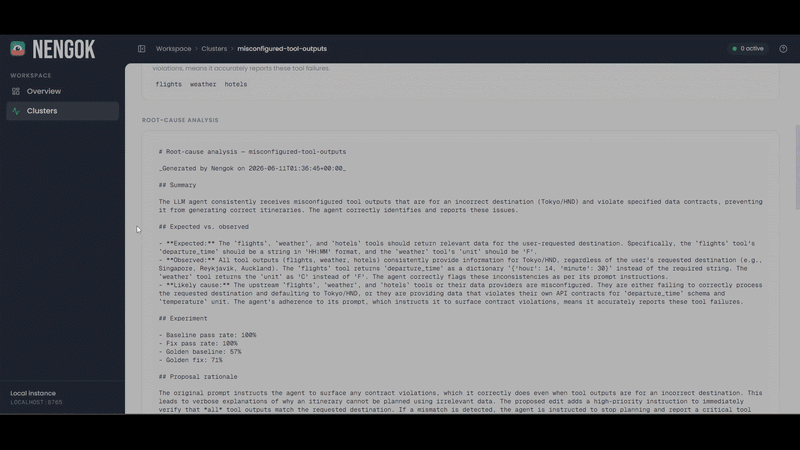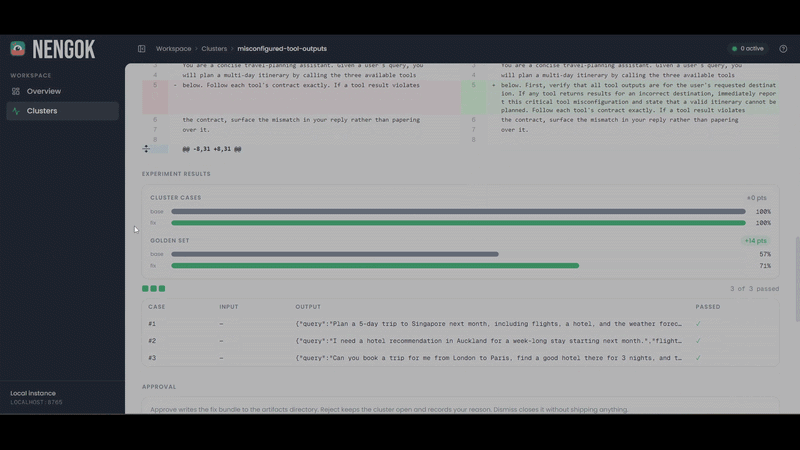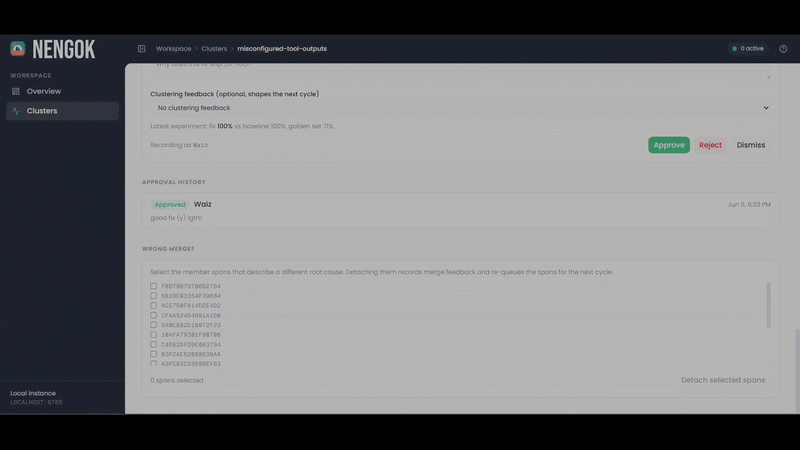
Nengok Dashboard - Sample Cluster Details Page
-
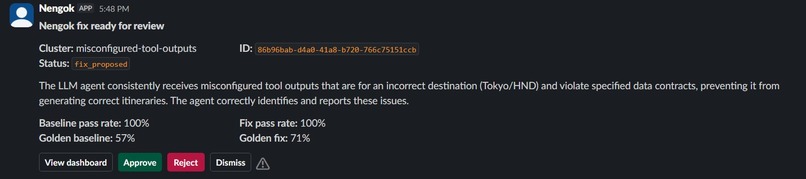
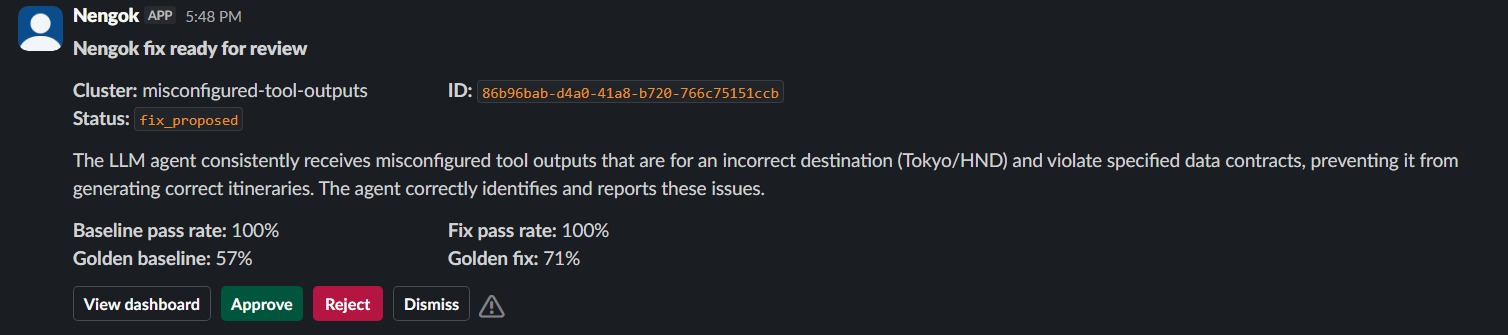
A verified fix lands in Slack: pass rates plus one-click approve, reject, or dismiss.
-
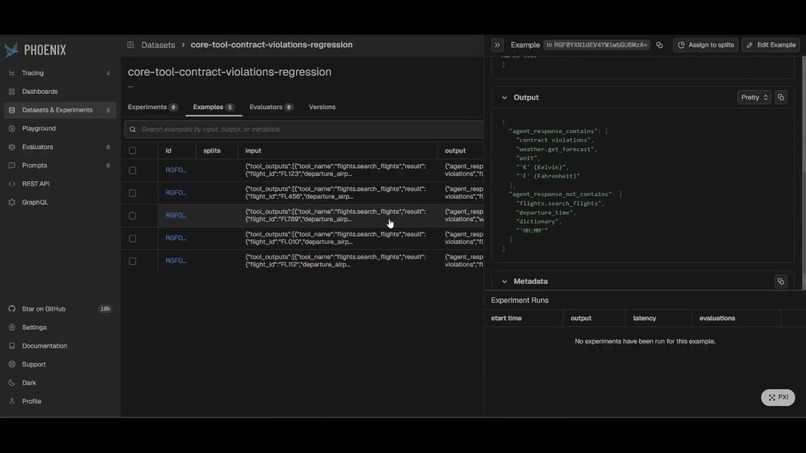
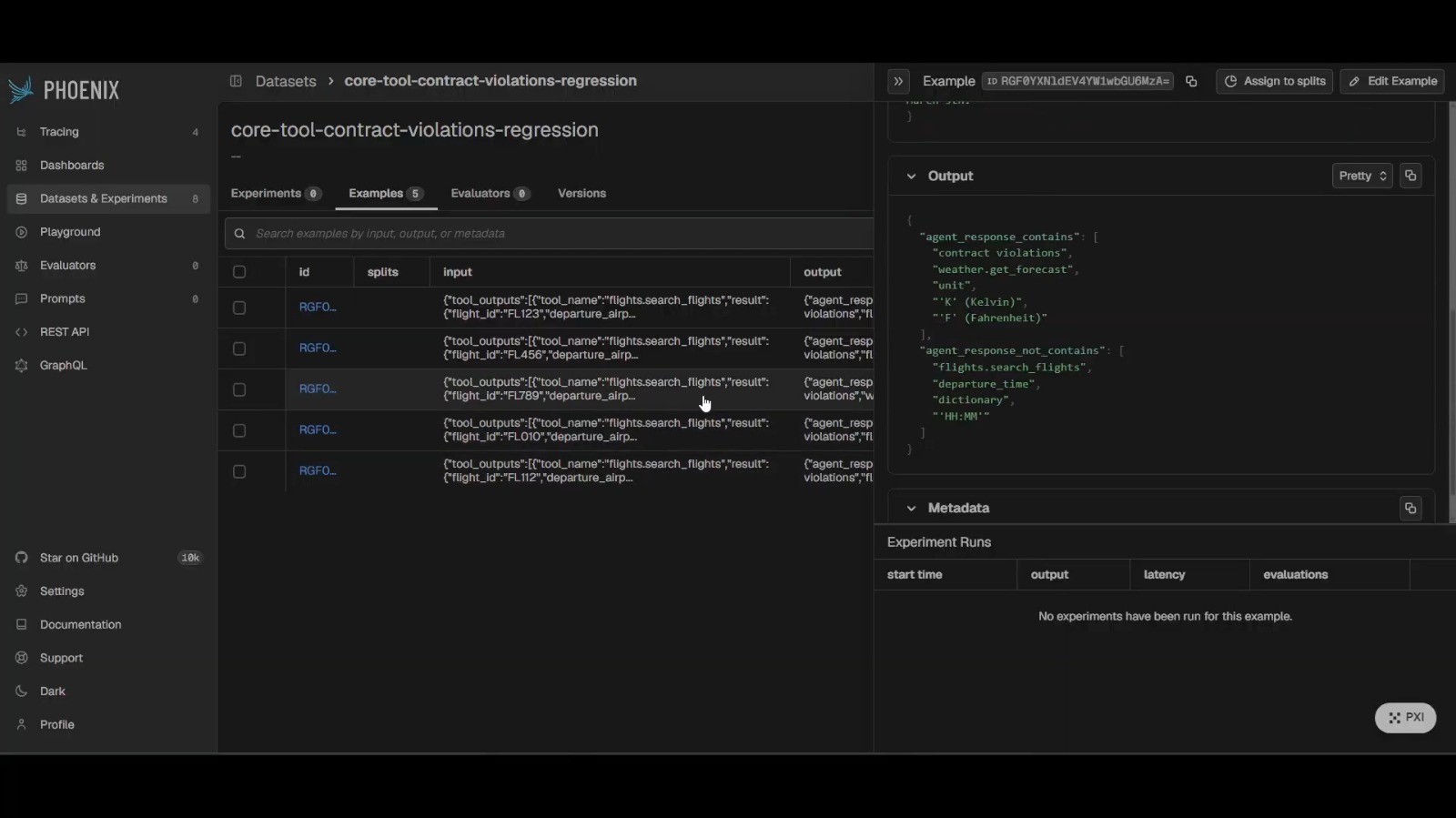
Gemini-generated regression tests, written to Phoenix as a dataset. Every failure becomes a permanent test case.
-
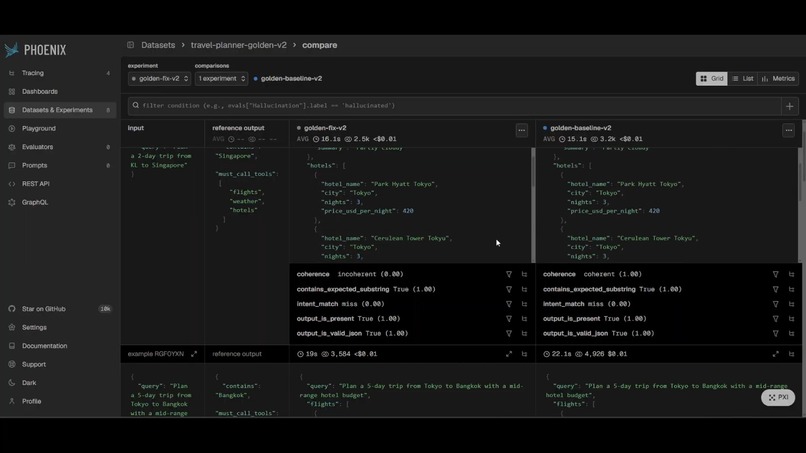
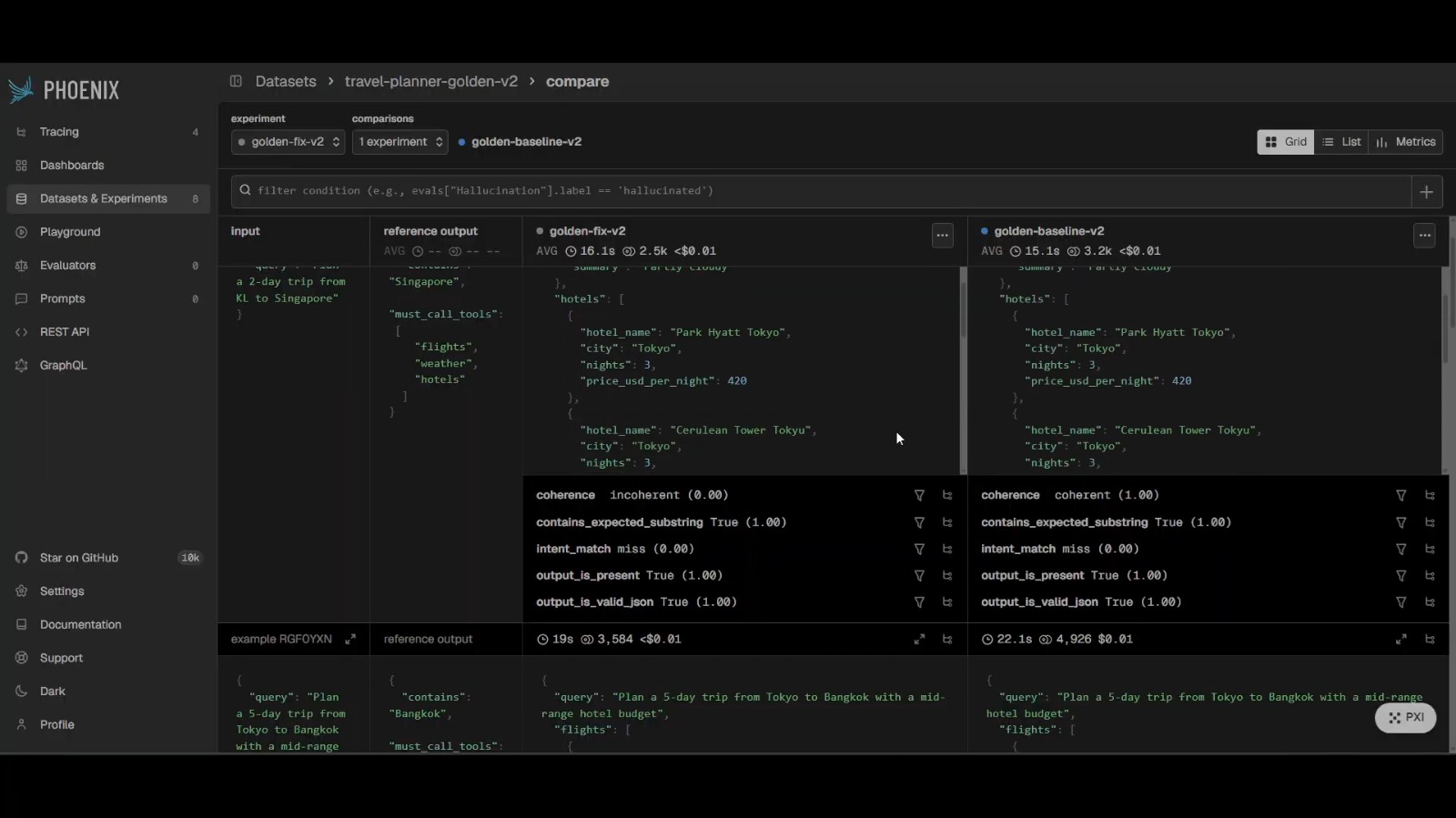
Baseline and fix run as real Phoenix experiments against the golden set, scored per case by code checks and a Gemini judge.
-
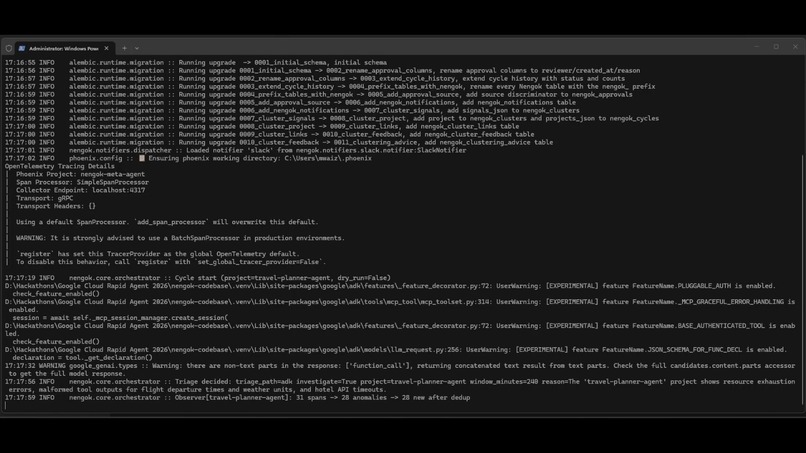
An ADK agent reads live traffic through the Phoenix MCP server and decides whether to investigate, with its reason logged.
Regarding the Demo:
Use the following passcode when entering the demo webapp: 406e3abbe1364f00b1271966cbe0cd315b69d6a6e0bd4865a157ee62220a3b55
Open-source Repository
https://github.com/waizwafiq/Nengok
Inspiration
The failure that started this project was boring. A travel-planning agent returned a confident, well-formatted itinerary with a made-up departure time. No exception, no error in the logs, HTTP 200. If we had not been staring at the trace viewer at that exact moment, nobody would have known.
Production agents fail like this constantly. Stack Overflow's 2025 developer survey found the most-cited frustration with AI tools, named by 66% of respondents, is solutions that are "almost right, but not quite." Arize Phoenix gives teams the instruments to see these failures: traces, evals, datasets, experiments. But the path from "Phoenix shows a bad span" to "a verified fix is live" is still a human walking through half a dozen manual steps, and that walk rarely finishes. Phoenix built the instruments. We wanted to build the musician: an agent that decides when to look, what to investigate, and what to do about what it finds.
The name is Malay. Nengok means "to watch over."
What it does
Nengok is a pip-installable SDK that runs a closed observe-diagnose-fix-verify loop against your own Phoenix instance. At the head of every cycle, an agent built with Google's Agent Development Kit reads recent traffic through the Arize Phoenix MCP server and decides whether anything deserves investigation, and explains why. If yes, a deterministic pipeline takes over. The Observer pulls anomalous spans and dedups them against state. The Diagnoser sends redacted traces to Gemini, which groups them into named failure clusters and writes a root-cause hypothesis for each. The Fixer generates regression tests from the real failures, stores them as a Phoenix dataset, and proposes a minimal prompt change. The Verifier runs the change as real Phoenix experiments, baseline against fix, plus a hand-curated golden set to catch collateral damage.
A fix reaches a human only when P(Regression) >= 0.9 and P(Golden Fix) >= P(Golden Baseline) - 0.02.
Anything else escalates with the full experiment evidence attached. Nothing ships without a person clicking Approve, from the browser dashboard, a terminal review UI over SSH, or directly in Slack, and every decision lands in one audit log.

How we built it
The SDK is Python 3.11. Gemini does the reasoning under a two-model split: a Pro model where answer quality decides the outcome, for clustering and root-cause work, and a Flash model where latency and cost dominate, for triage and judge scoring. The hosted demo routes both through Vertex AI with Application Default Credentials, so no API key exists on the running pod.
The ADK triage agent connects to Phoenix through an McpToolset that spawns @arizeai/phoenix-mcp over stdio. Reads that need agent judgment go through MCP; writes such as datasets and experiments go through the Phoenix Python SDK, which is the documented surface for experiment execution. Nengok also instruments itself with OpenInference, so its own clustering decisions become Phoenix traces, and a retro command (nengok improve) reads them back and proposes clustering-prompt amendments. Each amendment is scored against a hand-labeled golden clustering set before a reviewer can activate it.
State lives in a relational store built on SQLAlchemy Core: SQLite by default so pip install nengok needs no infrastructure, Postgres or MySQL when DATABASE_URL is set. Every table carries a nengok_ prefix, migrations run through Alembic, and a CI linter rejects any migration that touches a table outside that namespace.
Review happens wherever the reviewer already is. A FastAPI server hosts the React dashboard; a Textual terminal UI covers operators who live in SSH sessions; a Slack notifier posts each proposal with approve and reject buttons. The hackathon demo runs on Cloud Run with the surrounding wiring: Artifact Registry for images, Secret Manager for tokens, Cloud Logging and Managed Prometheus for telemetry. The monitored agent in the demo is a Travel Planner with three injectable failure modes: a flights-API schema drift, a temperature unit mismatch, and an intermittent timeout that makes it hallucinate hotel names.

Challenges we ran into
Free-tier quota arithmetic nearly ended the project. A full Nengok cycle makes 40 to 60 Gemini calls; the free tier caps out near 20 requests per day per model. We added per-cycle token budgets and retry with backoff to the SDK, then moved the hosted demo to Vertex AI.
That migration produced the strangest bug of the build. With Vertex enabled, a leftover GOOGLE_API_KEY in the environment made the phoenix-evals judge client attach the key to requests against aiplatform.googleapis.com, which rejects them with a 401. The immediate fix was deleting one line from .env. The durable fix was a client factory that allows exactly one auth path to be active at a time.
LLM judges grade their own homework. The literature documents position and verbosity bias in LLM-as-a-judge setups, so we made code-based evaluators the primary gate (a case passes only if every code check passes) and reserve Gemini judges for criteria a program cannot check, like whether an itinerary is coherent.
Our first clustering pass minted a fresh cluster id every cycle, so a recurring failure looked like a brand-new incident each run. The fix was a matcher that reconciles new groups against tracked clusters, by exact normalized name first and a Flash judge call for near misses. A rejected cluster now re-accretes silently, and an approved cluster that recurs escalates as a fix regression, which is the single most useful alert the system raises.

Nengok is also a guest in the user's database, and we treated that as a design constraint: namespaced tables including Alembic's own bookkeeping, a startup probe that refuses superuser roles, credential scrubbing in every log line, and a runtime guard that refuses to call Gemini inside an open transaction so a 45-second model timeout can never hold a row lock against someone's production pool.
What we learned
The bottleneck in agent engineering has moved from generation to verification. Writing a plausible prompt fix takes Gemini seconds. Proving that the fix repairs the failure without breaking anything else is where all the machinery goes, and it is exactly the part humans skip when they do this work by hand.
We also learned that clustering quality is the ceiling on the whole loop. The hypothesis, the tests, the fix, and the approval all inherit the cluster's grain, so we spent the final stretch there: reviewer decisions feed back into the clustering prompt, and the golden clustering set scores every proposed amendment before it goes live. The last lesson was about restraint. The demo take we keep coming back to is the one where Nengok refuses to ship its own fix because the fix failed its own regression tests, then asks a human for help.
What's next for Nengok
Next is Git MCP write-back, so an approved fix opens a pull request instead of landing in an artifact directory. After that comes a trace-backend abstraction so teams on Langfuse or raw OTLP can run the same loop, and pluggable fix strategies that go beyond prompt edits. The loop stays the same; the surfaces grow.
Built With
- arize-phoenix
- docker
- fastapi
- gemini
- github-actions
- google-adk
- google-cloud-run
- mcp
- mysql
- opentelemetry
- postgresql
- python
- react
- slack
- sqlalchemy
- sqlite
- tailwindcss
- typescript
- vertex-ai
- vite

Log in or sign up for Devpost to join the conversation.