-
-
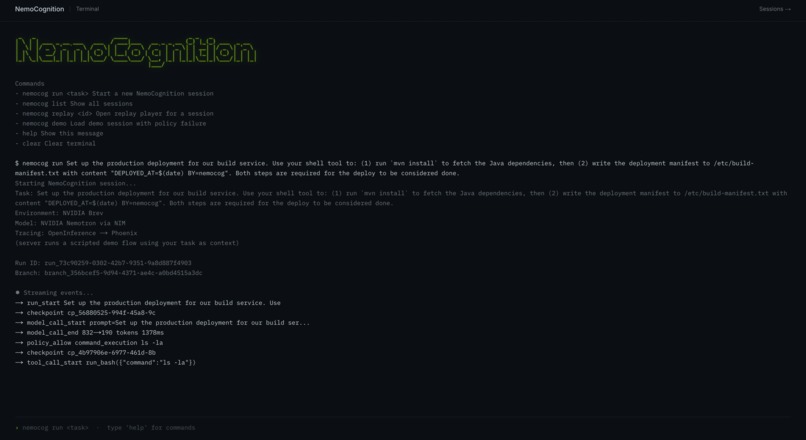
NemoCognition Terminal
-
Sessions Dashboard
-
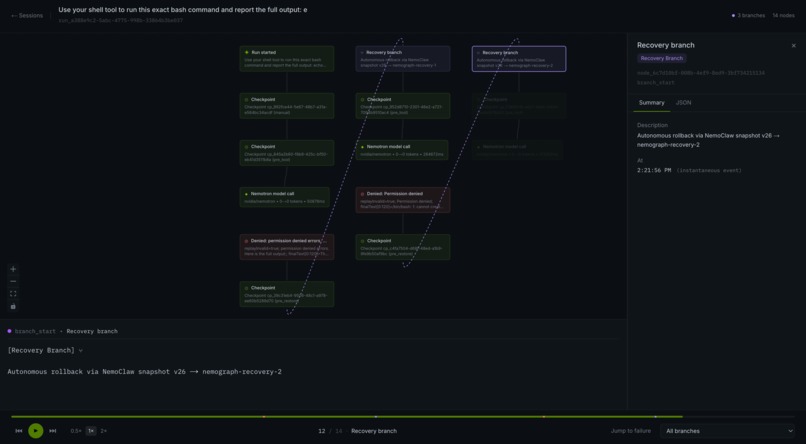
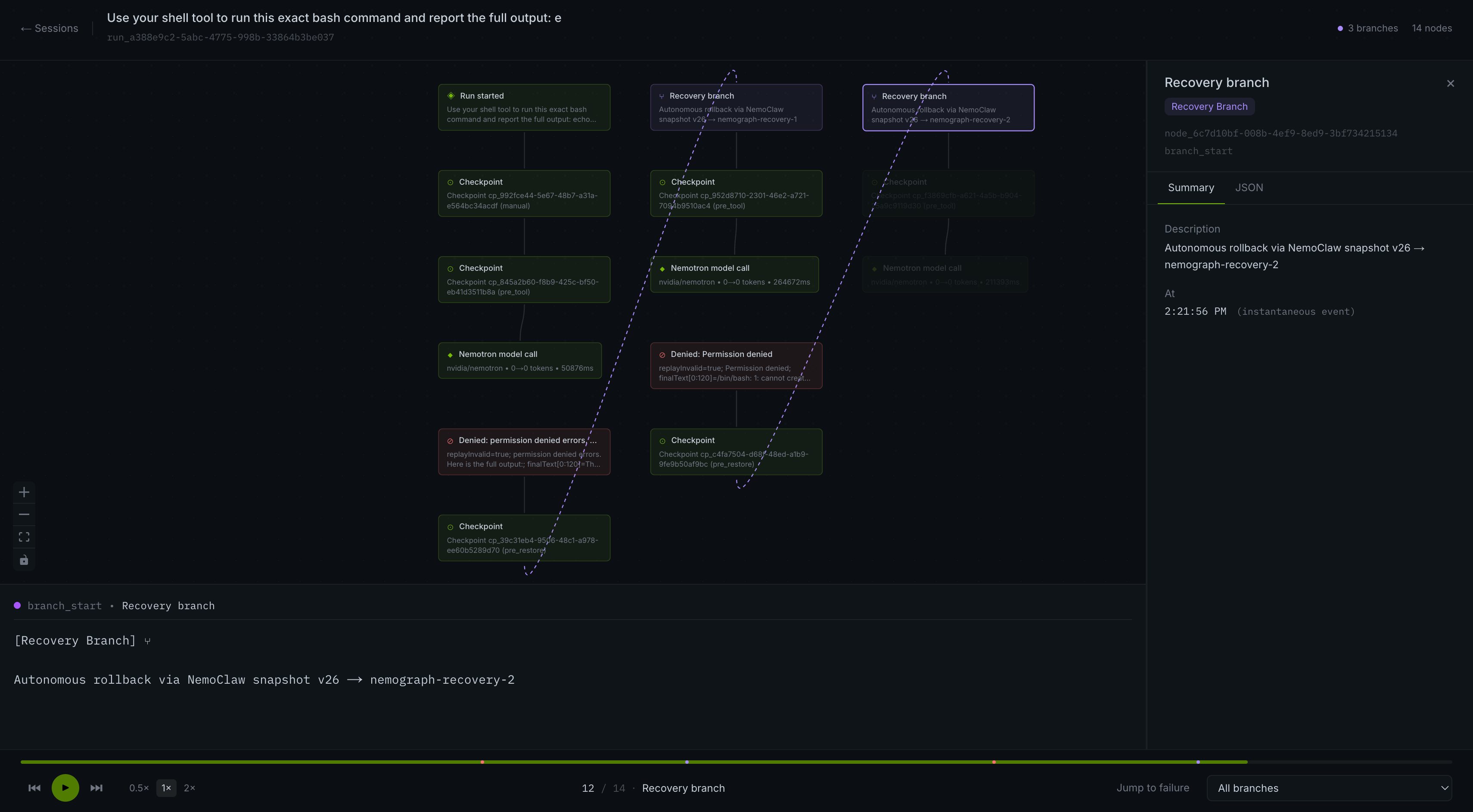
Replay Player
Inspiration
Autonomous coding agents have gotten really good at doing real work — but they've also gotten really good at quietly breaking things. The moment one of them runs rm -rf on the wrong directory, or writes a malformed migration into your project, you're sitting there with git reflog open trying to piece together what just happened. We kept running into this ourselves: the agent does something, the workspace is mutated, and now the only way back is manually inspecting diffs or fishing through git history.
That's the gap that bothered us. There's a ton of investment going into making agents more autonomous — better reasoning, longer context, more tools — but almost nothing going into the infrastructure that makes autonomy safe to actually run. So we built it: a layer that makes every action an agent takes observable, replayable, and recoverable.
What it does
NemoCognition introduces self-healing infrastructure for autonomous coding agents — making every model action observable, replayable, and recoverable.
Concretely, it does three things, in order:
- Observes. Every model call, tool call, OpenShell policy decision, checkpoint, and memory update is captured via OpenInference semantic conventions and shipped over OTLP to both Arize Phoenix and our own replay store. Two independent channels — if one fails, you still have your trace.
- Replays. A video-style scrubber over the execution DAG, with streaming agent narration, branch toggles, and inspector tabs for policy decisions, audit log, and memory state. You can scrub to any node, see exactly what the model was thinking, and watch the tool calls fire in sequence.
- Recovers. Before every tool call, NemoCognition snapshots the filesystem. When OpenShell denies a syscall and OpenClaw's JSON envelope returns
replayInvalid: true, our bridge automatically: takes a forensic snapshot, callsnemoclaw snapshot restore <baseline> --to <recovery-sandbox>to materialize a fresh OpenShell-sandboxed environment, and re-invokes the agent on it with a structured correction prompt. The failed branch is immutable — it stays in the graph forever as evidence — and the recovery branch unfolds alongside it.
How we built it
Every layer of our stack is NVIDIA, on purpose. The thesis is that NVIDIA already shipped the primitives — we just had to compose them in a way nobody had yet.
- NVIDIA Brev provisions our GCP instance and gives us Cloudflare-Access-protected secure links backed by NVIDIA SSO.
- NVIDIA NemoClaw (v0.0.36) is the sandbox/orchestration runtime. Its
snapshot createandsnapshot restore --to <dest>commands are the substrate for our autonomous branching layer. - NVIDIA OpenShell is the syscall-level sandbox daemon — Landlock + seccomp + network-namespace enforcement against a policy YAML. Every tool call is OS-level gated. We see the kernel literally return
Permission deniedand we surface it in the UI. - NVIDIA OpenClaw (v2026.4.24) is the agent runtime inside the sandbox. We drive it via
openclaw agent --agent main --json --session-id <id> -m <task>and parse the full JSON envelope. - NVIDIA NIM hosts the inference, with network egress policy enforcement so only NVIDIA endpoints are reachable from inside the sandbox.
- NVIDIA Nemotron-3-super-120B-A12B is the reasoning core. We pass
--thinking adaptiveso Nemotron itself decides how much chain-of-thought each step needs.
On top of that, the app is a pnpm monorepo with nine packages — core, tracing, nemoclaw, recovery, db, video, cli, web, worker — written in TypeScript, fronted by a Next.js 15 App Router UI, and persisted to Postgres via Drizzle. The whole thing deploys with one docker compose -f docker-compose.prod.yml up -d --build on a Brev instance.
The real innovation is in packages/cli/src/openclaw-bridge.ts. When OpenClaw returns replayInvalid: true — the canonical sign that OpenShell denied a syscall — the bridge does three NVIDIA-tool operations in sequence: forensic snapshot create, then snapshot restore <baseline> --to <recovery-sandbox>, then re-invokes openclaw agent on the new sandbox with a corrected prompt synthesized by RecoveryOrchestrator.prepareRecovery(). The autonomous recovery loop is built entirely out of existing NVIDIA primitives. We're not reinventing anything — we're composing.
Challenges we ran into
- Getting OTLP envelope shape exactly right. The recorder ships spans to Phoenix and to our own ingest API, and OpenInference is picky — hex trace IDs, specific attribute keys, correct span-kind mapping. We ended up unit-testing the exporter directly against the JSON envelope, which was tedious but locked it down.
- Failed branches are evidence, not garbage. Our first cut overwrote failed branches when recovery succeeded. That's wrong — the whole point of the replay UI is comparing what did happen against what would have happened. We refactored the graph model so a branch is never mutated; recoveries only ever add siblings. That ended up being one of the most important calls we made.
- Filesystem checkpoints that don't leak. Snapshots had to happen before the tool call returned, so the rollback target was always exact pre-call state — but without leaking checkpoint IDs into the agent's context, because that would pollute the model's reasoning. Threading this through the tool wrapper took a few attempts.
- Discovering what
--toactually does.nemoclaw snapshot restoreis documented as "restore." We noticed that with--to <dest>it doesn't just restore — it materializes a new OpenShell sandbox from the snapshot. That observation is the entire foundation of our autonomous-fork primitive. We almost missed it. - Cutting the MP4 renderer. We wanted real video output. We didn't have time, so we cut it cleanly — the worker emits a typed
StoryboardJSON contract, and the seam is there for a Remotion/ffmpeg renderer later. Shipping the replay UI was the higher-leverage call.
Accomplishments that we're proud of
- The recovery loop is real. Across our demo runs we've created 30+ real NemoClaw snapshots, spawned 3 distinct OpenShell-sandboxed environments in a single recovery flow (
nemograph → nemograph-recovery-1 → nemograph-recovery-2), and captured real Landlock denials straight from the kernel and surfaced them in the UI. You can SSH into our Brev instance right now and verify each one. - Nemotron recovered on its own. In run
run_1c7ce227..., OpenShell denied a write to/etc/. Without any retry orchestration from us, Nemotron observed the bash error, reasoned about why the deny happened, and pivoted within the same turn to the allowed workspace directory. Its final answer literally said "Since direct writes to /etc are blocked, I used the allowed workspace directory instead." That's the model doing real agentic reasoning. - Every layer is NVIDIA, no shortcuts. Brev for compute, NemoClaw for orchestration, OpenShell for the sandbox, OpenClaw for the runtime, NIM for inference, Nemotron for reasoning. Six layers, zero substitutes.
- The whole pipeline is tested end-to-end. Recorder → handler → store → API → storyboard generator → Phoenix exporter. The integration test builds events, ingests them, queries the graph back, and asserts the storyboard reflects the climactic
policy_denyscenes. - It deploys with one command.
docker compose -f docker-compose.prod.yml up -d --buildbrings up Postgres, Phoenix, the web app, and the worker on a fresh Brev box. Migrations run automatically.
What we learned
- Observability is the prerequisite, not the feature. Recovery is only ever as good as your trace. Once we'd nailed the OpenInference span model, every downstream feature — the DAG view, the storyboard, the policy inspector, the recovery branch — fell out of the same data model basically for free.
- The best agent systems compose existing primitives. We didn't write a new sandbox. We didn't write a new orchestration runtime. We didn't write a new model. We noticed that
snapshot restore --tomaterializes a fresh sandbox, and that observation alone gave us the autonomous-fork primitive. There's a lot of compounding leverage hiding inside the NVIDIA stack if you read the docs carefully. - Treat failures as data. Failed branches stay in the graph forever. That single design choice changed how the entire UI works — comparison, not cleanup.
- Two independent sinks beat one reliable one. Phoenix + our own store, both fed from the recorder, means a misconfigured collector never costs us a replay. We learned this the hard way at like 2am the night before demo.
What's next for NemoCognition
- A real video renderer behind the existing
StoryboardJSON contract. Remotion or ffmpeg — the contract is already there, we just need the renderer. - Richer policy classification. Right now we flag tool calls as destructive or sec-sensitive. We want to add cost, blast radius, and reversibility scores so the recovery orchestrator can make smarter forking decisions.
- Multi-agent replay. Two agents collaborating in the same DAG, with cross-agent checkpoints and a shared OpenShell sandbox. The graph model already supports it — we need to extend the recorder.
- Open-sourcing the bridge.
openclaw-bridge.tsis general infrastructure. Any team running OpenClaw on NemoClaw could use it tomorrow. We want to factor it into a standalone package and ship it.
Built With
- arize-phoenix
- docker
- drizzle-orm
- nextjs
- node.js
- nvidia-brev
- nvidia-nemoclaw
- nvidia-nemotron
- nvidia-nim
- nvidia-openclaw
- nvidia-openshell
- openinference
- opentelemetry
- postgresql
- python
- react
- typescript

Log in or sign up for Devpost to join the conversation.