-
User inserts a YouTube URL for parsing and analysis
-
The YouTube video is processed and parsed by the NLP and data analytics in the backend
-
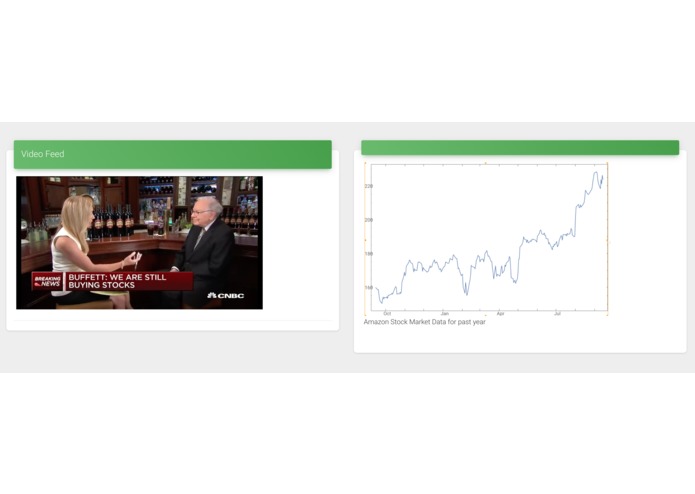
Collected data and statistics are displayed to the user at the appropriate times as the video plays
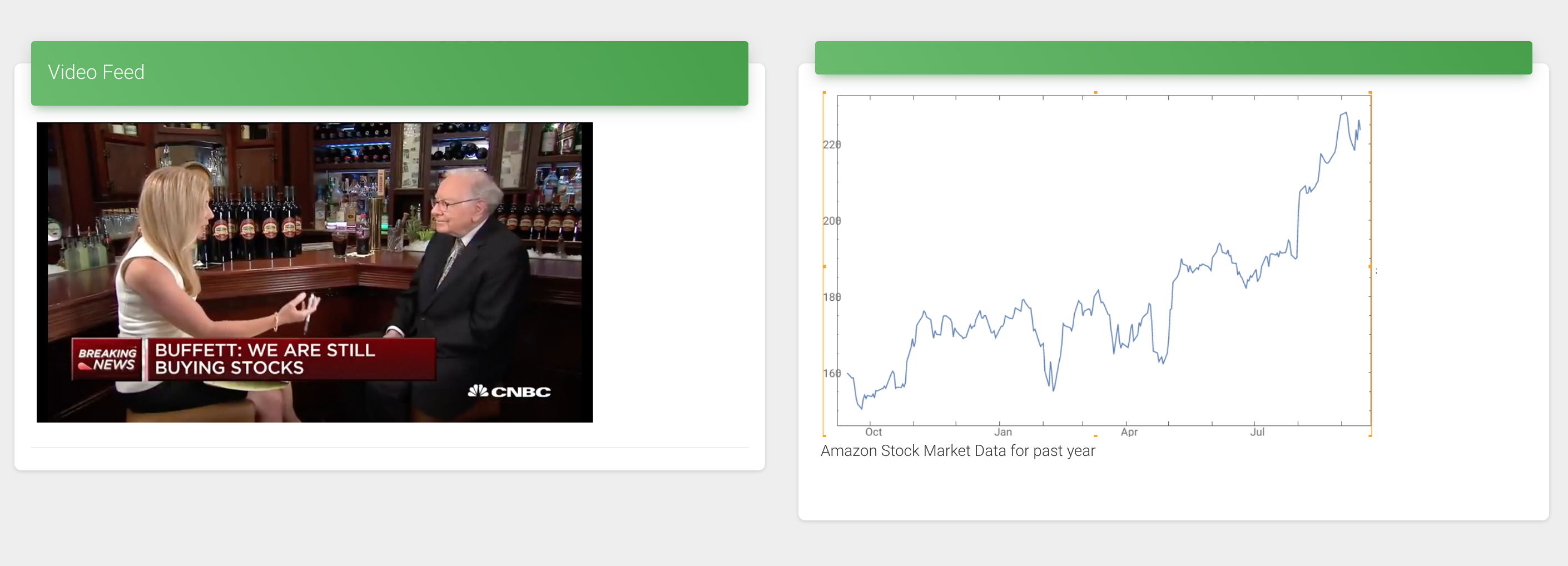
Inspiration
The idea arose from the current political climate. At a time where there is so much information floating around, and it is hard for people to even define what a fact is, it seemed integral to provide context to users during speeches.
What it does
The program first translates speech in audio into text. It then analyzes the text for relevant topics for listeners, and cross references that with a database of related facts. In the end, it will, in real time, show viewers/listeners a stream of relevant facts related to what is said in the program.
How we built it
We built a natural language processing pipeline that begins with a speech to text translation of a YouTube video through Rev APIs. We then utilize custom unsupervised learning networks and a graph search algorithm for NLP inspired by PageRank to parse the context and categories discussed in different portions of a video. These categories are then used to query a variety of different endpoints and APIs, including custom data extraction API's we built with Mathematica's cloud platform, to collect data relevant to the speech's context. This information is processed on a Flask server that serves as a REST API for an Angular frontend. The frontend takes in YouTube URL's and creates custom annotations and generates relevant data to augment the viewing experience of a video.
Challenges we ran into
None of the team members were very familiar with Mathematica or advanced language processing. Thus, time was spent learning the language and how to accurately parse data, give the huge amount of unfiltered information out there.
Accomplishments that we're proud of
We are proud that we made a product that can help people become more informed in their everyday life, and hopefully give deeper insight into their opinions. The general NLP pipeline and the technologies we have built can be scaled to work with other data sources, allowing for better and broader annotation of video and audio sources.
What we learned
We learned from our challenges. We learned how to work around the constraints of a lack of a dataset that we could use for supervised learning and text categorization by developing a nice model for unsupervised text categorization. We also explored Mathematica's cloud frameworks for building custom API's.
What's next for Nemo
The two big things necessary to expand on Nemo are larger data base references and better determination of topics mentioned and "facts." Ideally this could then be expanded for a person to use on any audio they want context for, whether it be a presentation or a debate or just a conversation.

Log in or sign up for Devpost to join the conversation.