Inspiration
Every developer has asked an AI for help with a library and gotten a confident, detailed, completely wrong answer. The model's training data is stale, the APIs have changed, and it fills the gaps with plausible hallucinations. Research from METR measured a 19% slowdown from AI-assisted coding - largely from debugging fabricated APIs and verifying suspect answers. For a 6-person team, that's nearly 23 hours lost per week.
We wanted something that could answer questions about any library - undocumented, bleeding-edge, internal, or just moving too fast for docs to keep up - by reading the actual source code instead of guessing from model memory.
What it does
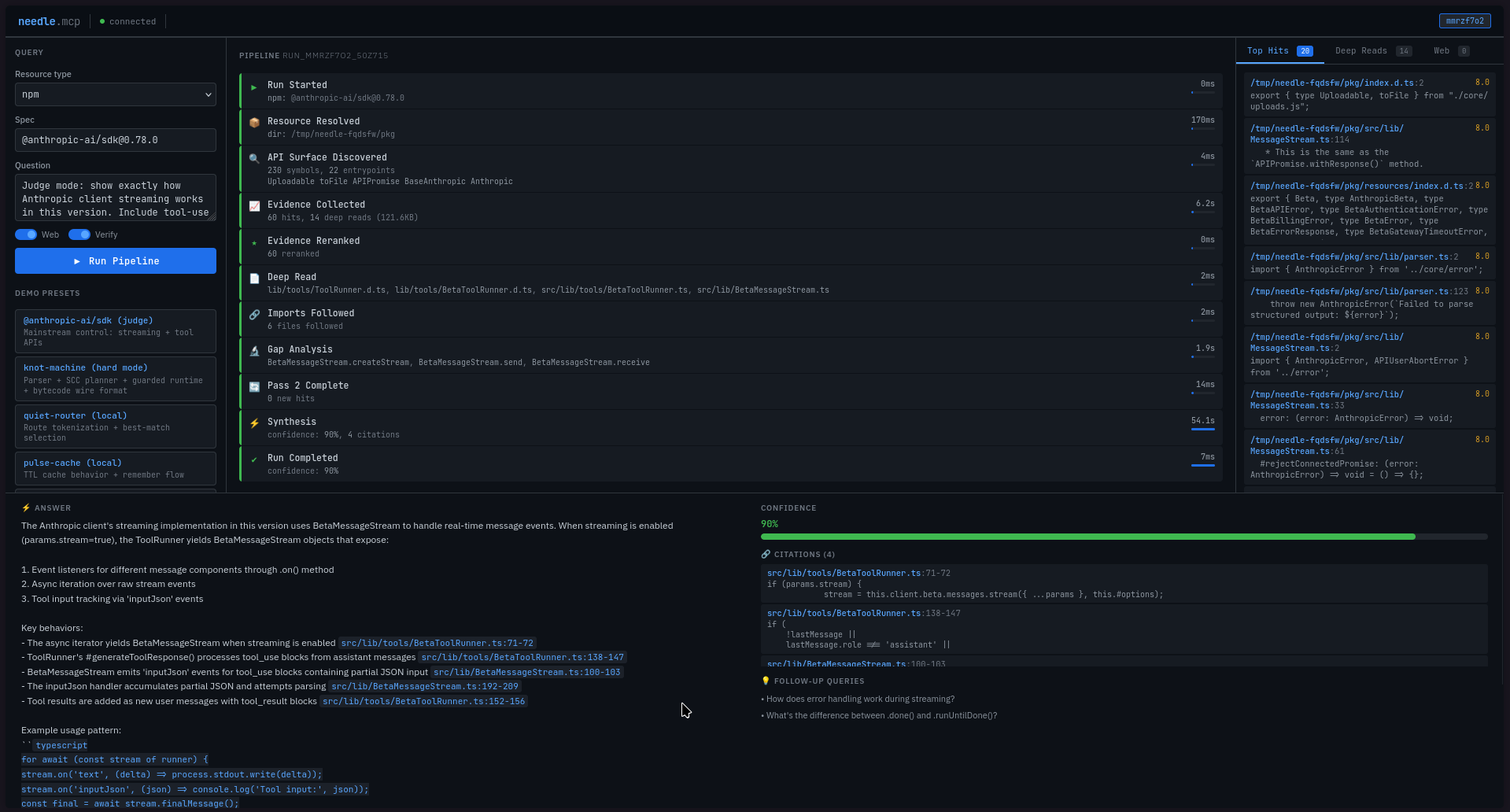
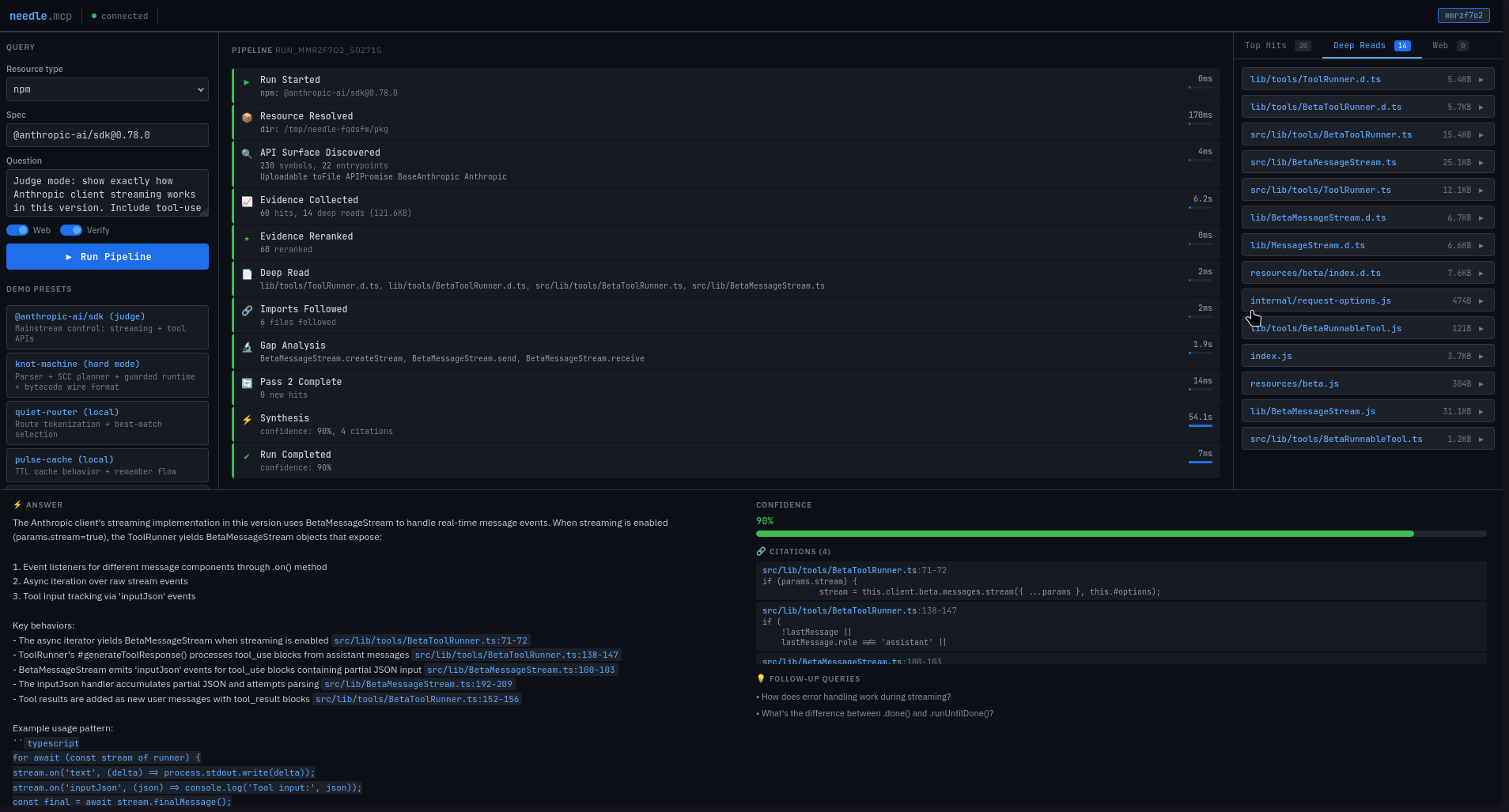
Needle MCP is an MCP server that answers questions about libraries by grounding every answer in their actual source code. Give it an npm package, git repo, or local directory and a question. It resolves the resource, discovers the real API surface, searches the source with ripgrep, and synthesizes an answer using Amazon Nova Premier on AWS Bedrock - returning structured JSON with line-level citations.
Key capabilities:
- Multi-model pipeline: Nova Lite handles query expansion, evidence reranking, and gap analysis; Nova Premier handles final synthesis
- Iterative two-pass evidence collection: search, rerank, deep-read, follow imports, gap analysis, then a second targeted pass
- Citation Integrity Guard: every citation is validated against real files and line ranges - fabricated references fail the response
- Snippet Verification Engine: executes generated code in a sandboxed temp project with auto-imports, syntax repair, and multi-pass symbol resolution
- Quality gates: prevents synthesis when evidence is too thin, returning low-confidence fallbacks with suggested follow-up queries instead
- Real-time dashboard: SSE-powered web UI for watching the full pipeline execute live, with bundled demo presets including a deliberately difficult hard-mode target
How we built it
The core is a TypeScript MCP stdio server with an iterative evidence pipeline:
- Resource resolution - npm packages via pacote, shallow git clones with
#ref, or local directories - API surface discovery - reads
package.jsonentrypoints (main,module,types,exports), scans barrel exports and.d.tsfiles to build a shortlist of real exported symbols - Query generation - four sources: discovered symbols, code-like tokens from the question, structural intent patterns, and Nova Lite semantic expansion. Generic filler words are filtered before hitting ripgrep
- Evidence scoring - hits ranked by file path (
.d.ts+5,src/+4,node_modules/-10), then Nova Lite reranks for question relevance - Deep reading - top files are read in full, relative imports are followed, oversized files get chunk extraction around evidence hits
- Gap analysis - Nova Lite identifies what's still missing, a second targeted ripgrep pass fills the gaps
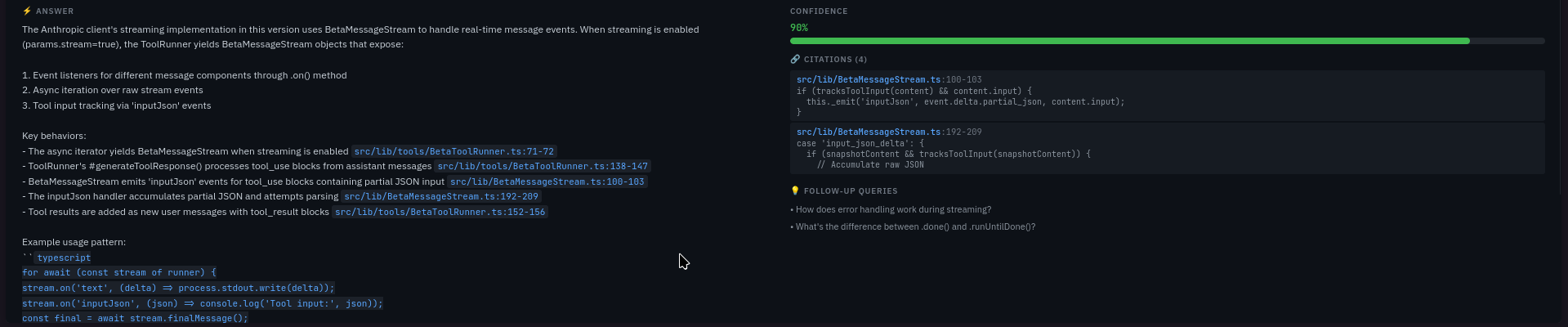
- Synthesis - Nova Premier generates the answer with citations, validated through Zod schemas with automatic retry and repair
- Citation validation - paths must resolve inside the target resource, line ranges must be in-bounds. Invalid citations are dropped, confidence is downgraded, fully invalid answers fail safely
- Optional verification - generated snippets run in a sandboxed temp project with three modes: direct execution, assisted import recovery, and nested module resolution. Non-JS snippets and CLI examples are skipped with explicit notes
The dashboard is a bundled SSE-powered web UI with demo presets backed by deliberately undocumented local libraries (knot-machine with SCC/Tarjan control flow, quiet-router, pulse-cache, framepack) for realistic stress-testing. It also includes a judge/control preset for @anthropic-ai/sdk@0.78.0 so reviewers can compare against a mainstream package.
The benchmark suite compares Needle against an ungrounded baseline (GPT-5.3 Codex or Nova Premier direct) using 8 deterministic cases with hand-written ground-truth facts per test case.
Challenges we ran into
Hallucinated line numbers: Even with strong evidence, Nova would sometimes fabricate citations. We built the Citation Integrity Guard - paths must resolve inside the target, line ranges are bounds-checked, and fully invalid answers fail with confidence 0 instead of being served with false authority.
Query generation noise: Early versions used naive keyword extraction and hit tons of irrelevant code. The four-source approach (symbols + tokens + intent patterns + Nova Lite expansion) with generic word filtering dramatically improved evidence recall.
Large packages: npm packages like
zodhave 50K+ line type definition files. We implemented file-size limits, deep-read budgets, chunk extraction around evidence hits, and import-following to stay within context windows without losing critical context.Verification edge cases: Generated snippets often omit imports, use TypeScript annotations in JS contexts, or have malformed object literals. The verifier needed three execution modes (direct, assisted, resolved), TypeScript annotation stripping, syntax repair for missing braces, and explicit skip reasons for non-JS content.
Evidence depth vs. breadth: A single-pass search misses too much. The iterative approach - search, rerank, deep-read, follow imports, gap analysis, second pass - catches significantly more relevant evidence, which directly improves synthesis quality.
Accomplishments that we're proud of
- 85% reduction in expected time to first correct answer vs baseline (27.8s vs 185.1s)
- 53.1% average fact coverage vs 21.9% for baseline - 2.4x more grounded
- 100% citation validity - every citation points to real code at real line numbers, vs 0% for baseline
- 3x correctness rate (37.5% vs 12.5% at 75% fact-coverage threshold)
- 6.6x speed multiplier to first correct answer
- 31.5 minutes saved per engineer per week, 189 minutes for a 6-person team
- Fully reproducible benchmark suite -
./benchmarkruns everything from scratch, generates reports and SVG charts - Works with any MCP client - Claude Desktop, Codex CLI, or anything supporting the protocol
- Bundled hard-mode demo resources with minified multi-file internals for realistic stress-testing
What we learned
- Grounding answers in source code is dramatically more effective than relying on training data for fast-moving or undocumented libraries
- Citation validation is non-negotiable - without it, high confidence scores are meaningless and dangerous
- Iterative evidence collection with gap analysis catches what single-pass search misses every time
- File-path scoring is a simple but powerful heuristic -
src/files are almost always more relevant thanREADME.md, and penalizingnode_modules/eliminates massive amounts of noise - The quality gate (minimum code hits before synthesis) prevents more hallucination than any amount of prompt engineering
- Multi-model pipelines work well - Nova Lite is fast and cheap for evidence tasks, Nova Premier brings the reasoning power for synthesis
What's next for Needle
- Streaming synthesis - show answers as they generate instead of waiting for the full response
- Cross-package queries - answer questions spanning multiple dependencies in a project
- Incremental indexing - cache API surface discovery and evidence for repeated queries against the same resource
- TypeScript type-checking verification - validate generated code at the type level, not just runtime execution
- Community benchmark contributions - open the benchmark harness for community-submitted test cases and ground-truth facts
- More resource types - PyPI packages, crates.io, Go modules
Built With
- aws-bedrock
- jsonrepair
- mcp-sdk
- node.js
- pacote
- pnpm
- ripgrep
- typescript
- vitest
- zod

Log in or sign up for Devpost to join the conversation.