-
-
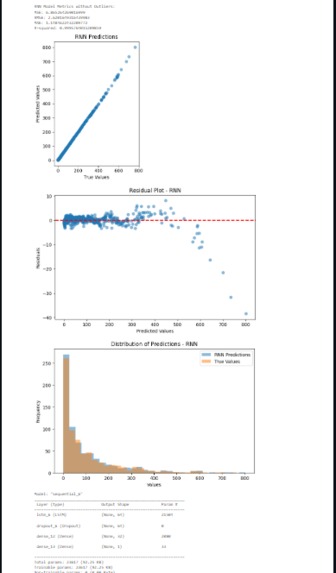
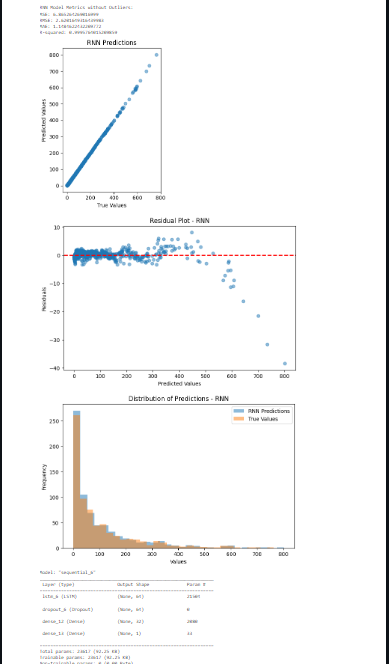
End result of model
Inspiration
We saw the increase of NBA Players' assists with new talent like Nikola Jokic and Luka Doncic, so we decided to investigate and attempt to predict players' assists using their other stats. This would serve as a benefit to coaches, scouts, and players, allowing for more informed decisions in split-second situations, as well as a means of increasing the accuracy of player evaluation.
What it does
This project was threefold:
- Get data from the NBA.com api (harder than it seemed)
- Determine which factors to use for the model
- Train and optimize the model to predict future data with a relatively high sense of accuracy (RMSE as close to 0 as possible, R-Squared as close to 1 as possible)
How we built it
We used the python framework, implementing the nba_api package and tqdm to monitor the download of data. After downloading the csv of player stats (it was a json but we converted it so we could easier integrate it with pandas), we ran some basic statistical tests on the numeric variables (since there were only 5 years anyway, so things like player name and years played would have a negative effect on the efficacy of the model). The goal here was to determine which values had the highest correlation to Assists, which were our value we were trying to predict. After finding the top 8 correlated features, we now knew what to target in our model. This was the most complicated portion of our process. We did not know whether we wanted to use a simple pass-forward Neural Network, or use some other sort of Machine Learning Algorithm. Eventually, we compared Random Forest Classification, a simple forward-feeding CNN, and a LSTM-Based RNN. We found that of the 3, the RNN had by far the most efficacy in reducing loss (MSE) and variance (R-Squared) (most likely due to the complexity of the model).
Challenges we ran into
Tair can't be added onto the team on devpost, since he forgot to do it on Saturday and is on a plane now, on Sunday Tair was in Kazakhstan Needed to learn new IDE (google colab) Artem accidentally concatenated the csv twice (there goes 4 hours of our time) Both laptops died because we accidentally kicked the power cord like 2 hours prior, so we had to redownload the entire csv again (it was on 98%) Artem’s laptop died because he went to the git sessions (which was actually helpful because we definitely would have written over some code if we didn’t know about committing) Tair’s plane got delayed, and he is slated to arrive after the time the submission was due. (Like 3-4 PM)
Accomplishments that we're proud of
We reached an MAE of 1.1484622432209772, which is really good. Ideally, an MAE of less than 1 is ideal, but this is really close and we're super happy that our model was able to relatively accurately predict on our dataset. Also, our R-Squared was 0.9995764015209859, which shows a very precise model, which did help us out a lot.
What we learned
We learned a lot of technical jargon, and had to become familiar with the concepts of feed-forwarding, backpropogation, LSTM architecture, He normalization, ReLU activation, and a lot of python packages (can be found in the github). Also, we had to become near experts in the nba_api package, since we needed specific data from it which was not the most user-friendly. We became familiar with the github platform, learning how to push/pull, commit, etc. This helped us optimize the workflow a lot, and definitely saved a bunch of time. We became pretty good at markdown to help us with the technical explainations found on the bottom of our ipynb (we weren't sure where else to put them). Finally, we had to learn premiere pro to do some quick edits for the video needed for the submission, which was super stressful since both of us overslept, and had 1.5 hours to edit the whole thing.
What's next for NBA LSTM RNN using the NBA.com api for data
Moving forward, we will train the model on other datasets (in the same context). A good starting point would be some data from the 90's, since the game played completely different back then. Thankfully, since we got so good at accessing this api, it will be much easier to get the data on the second go around, and hopefully our model maintains the same level of accuracy moving forward.


Log in or sign up for Devpost to join the conversation.