-
-

Home Page
-

Sign-up Page. Players can choose NBA team and team roster will automatically be generated.
-
Sign-in Page.
-
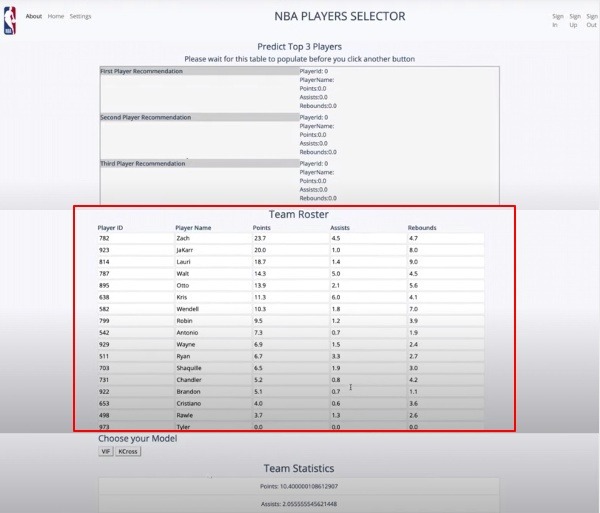
Team roster is automatically displayed upon signing in.
-
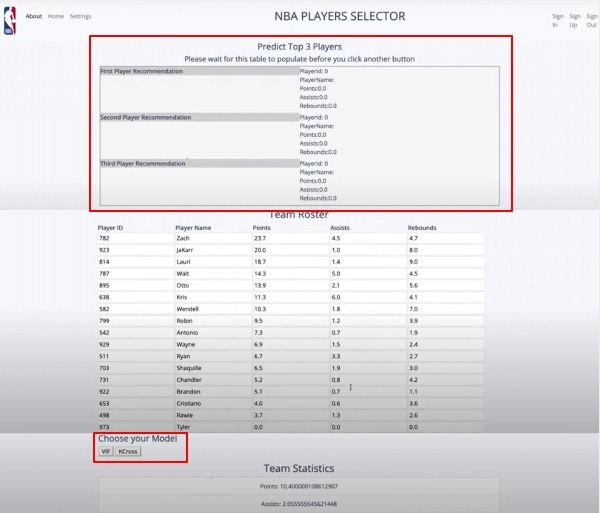
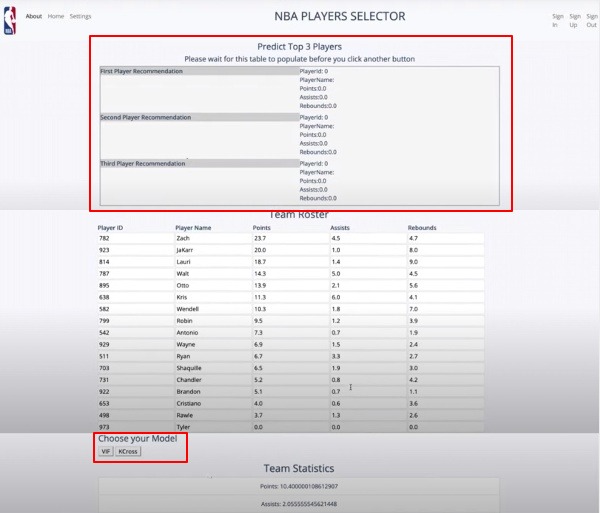
Main Page. Player recommendations are generated after selecting and running ML model. Choice of 2 models: VIF, K-Cross Validation
-

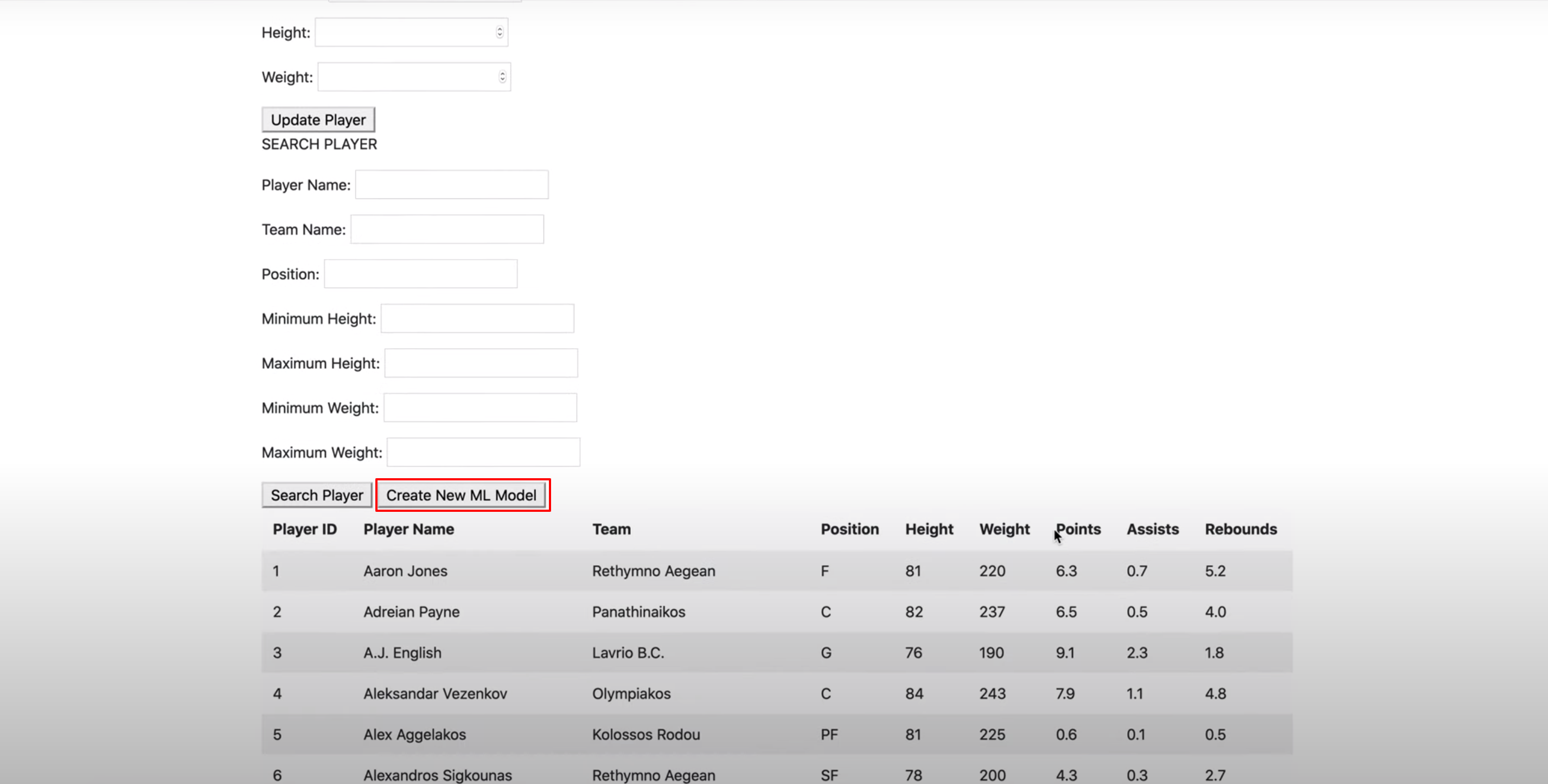
Ability to modify database from front-end by adding, removing, updating, or searching for players in the database (CRUD)
-
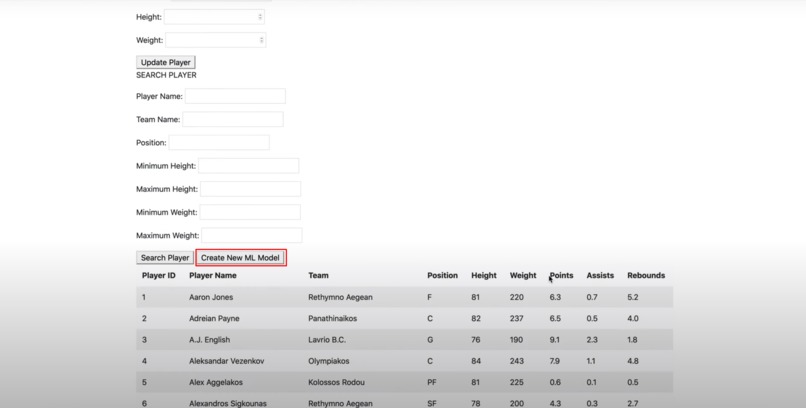
Ability to re-train ML algorithms based on newly added data points.
-
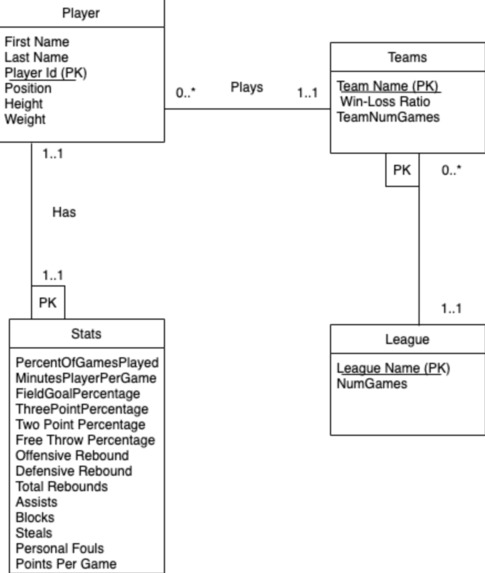
Database UML Diagram
-
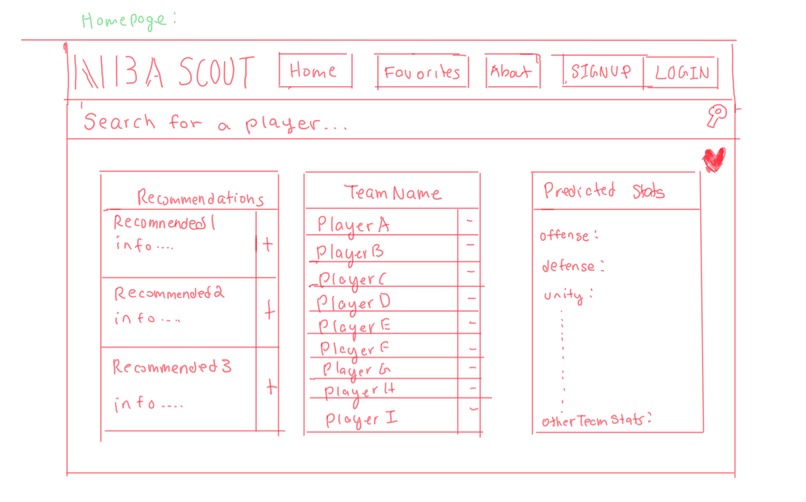
Initial Design
-
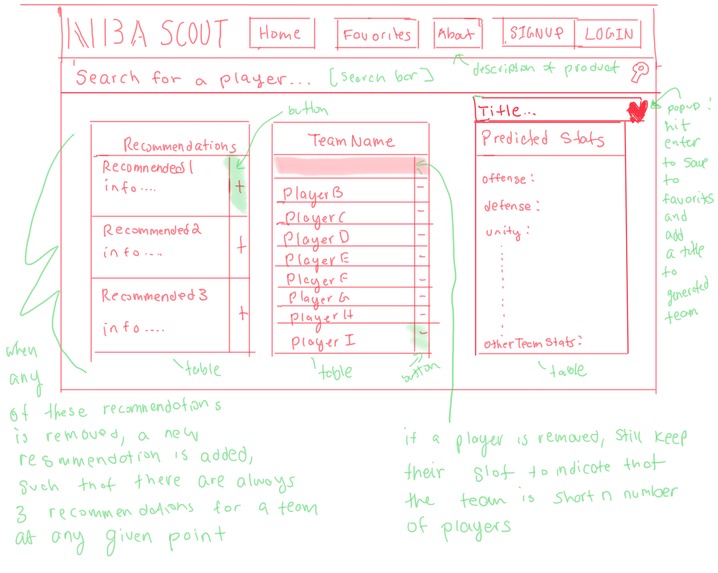
Initial Design (Detalied)




Background + The Problem
NBA scouts are professionals hired by NBA franchises to evaluate player talent or opposing teams' preparation or strategies. A prospect scout typically looks for younger players with potential or existing players whose rights may be available through free agency or trade.
Most of the time, NBA scouts recruit from leagues in the United States. However, sometimes they also recruit players internationally. Our goal with this project was to build a tool to help NBA scouts analyze and recruit talented players from international leagues, in specific, the Greek and EuroLeague basketball leagues.
Brainstorming + The Solution
So how can we develop a tool to help NBA scouts recruit talent? In our initial brainstorming phase, we came up with several ideas:
(1) Create a list of the international players and add functionality to sort players by statistics Such tools already existed and we felt that they still put a lot of manual work on the scouts. Although scouts may be able to view the statistics, they ultimately had to crunch the numbers themselves and do all the heavy-lifting analysis. We wanted to do better than this.
(2) Create a machine learning recommendation system that runs simulations to determine the top 3 foreign-league players for a particular NBA team This approach would take the burden off of the scouts. The scout could select a particular team and retrieve a list of players that would likely improve the team’s performance. We decided to offer two different modeling techniques to determine the top three recommendations. The scout could select a model, generate a list of recommendations, and then look at each of the recommended players’. Statistics in further detail to determine the best players for a team.
As you might have guessed, we decided to go with the latter of the two options.
Database Schema
In order to support our application, we included 5 different tables/relations in our database: Statistics, Players, Teams, Leagues, and Scouts.
The schema and UML diagram for our database is listed below. Please note that the UML and schema do not include the Scouts table, as the Scouts table is independent of the other relations.
Players(PlayerID, PlayerName, TeamName, Positions, Height , Weight) Teams(TeamName, LeagueName, Wins, Losses, NumGames) Leagues(LeagueName, NumGames) Statistics(PlayerID, numGames, minPlayed, FieldGoalAttempts, FieldGoalPercent, ThreePointAttempts, ThreePointPercent, TwoPointAttempts, TwoPointPercent, FreeThrowAttempts, FreeThrowPercent, Rebounds, Assists, Steals, Blocks, Turnovers, PersonalFouls, Points)

The Statistics table has around 1000 players and lists around 16 unique data points for each player. This table also has a foreign key that refers to the Players table to ensure that we are not populating statistics for a player that does not exist.
The Players table also consists of around 1000 players and stores the PlayerID, PlayerName, Team, Position, Height and Weight. This table has a primary key on PlayerID to ensure that each player can be uniquely identified, as well as a foreign key which refers to the Teams table to ensure that we are not adding players to non-existent teams.
The Teams table consists of around 60 teams and stores TeamName, Wins, Losses, and Number of Games for each one of them. This table also has a primary key for TeamName which ensures that we are not duplicating any teams.
The next table is Leagues in which we are storing the LeagueName and the Number of Games for each league.
Finally, we have a Scouts table to store the Email, UserName, Password, and Team for each scout that creates an account with us. This table also has primary keys for Email and Username to ensure that each of these are unique, as well as a foreign key on Team to check if the scout is signing up with a team that actually exists in our database.
We hosted our server for free remotely using freemysqlhosting.net, and we are using phpMyAdmin to access this server.
Data Aggregation + Refinement
Our project required data on the NBA league and Foreign Leagues. It was critical that the data from both leagues be from the same source and year (to minimize variability of data). Ultimately, we were able to find a website, basketball-reference.com, which had data on both the leagues and satisfied all parameters in our database schema. We crossed check data from the websites before agreeing to go through with the source. After we acquired the data, we realized that there were some discrepancies between our data and schema. Particularly, there were repetitions in players. Some players played in more than one team in the same basketball season. Ultimately, we were able to resolve these discrepancies by writing python scripts to only select the teams in which the player played for the longest time in particular season.
ML Model
Recall that goal of using ML was to develop a recommendation system to recommend the best players that could be added to particular team to improve performance. Before we can create such a system, we must first develop a method to evaluate an NBA team’s performance based on the players in that team. This would allow us to run simulations to find the best combination of players for a particular team.
We developed a base multilinear regression model to predict team rankings based on 16 team-based statistics (ie average team player height, average team player weight, average team player recommendations). We then refined our base model by choosing the “best” subset of predictor variables to predict the dependent variable. We used two different methods to build our final models: K-Cross Validation and Variance Inflation Factor.
(1) Simulations and K-Cross Validation We first found all possible combinations of predictor variables. Next, we ran each of these combinations through K-Cross validation (with a 70/30 train/test split) to attain an average SSE score for a particular model. We selected the minimum of the average SSE scores as our model.
(2) Variance Inflation Factor Checks whether or not each category of the statistics table is highly correlated to any of the other categories of the statistics table. If it detects a high correlation, then we will keep dropping those variables until all of the variables have a low correlation.
Once we generated each of these models, we stored each of the models in a CSV file in the back-end. This way, rather than re-training the model each time to generate recommendations, the scout can re-train the data only when a significant amount of new data is added to the database, thereby minimizing run-time.
Simulations
Once we generated our models, we would run simulations on each of the models to generate player recommendations. For each NBA team, the team’s current roster would be appended with one of 500+ foreign league players. Next, we generate statistics for the new team by including the new player’s statistics with the current team roster’s statistics, generating a new set of team statistics, which is hen used to predict the new team’s ranking (using the regression model generated from the previous step). This process is repeated for each of the 500+ foreign league players to generate 500+ unique rankings. The top three players that maximize this ranking are then recommended to the scout.
UI + UI Refinement
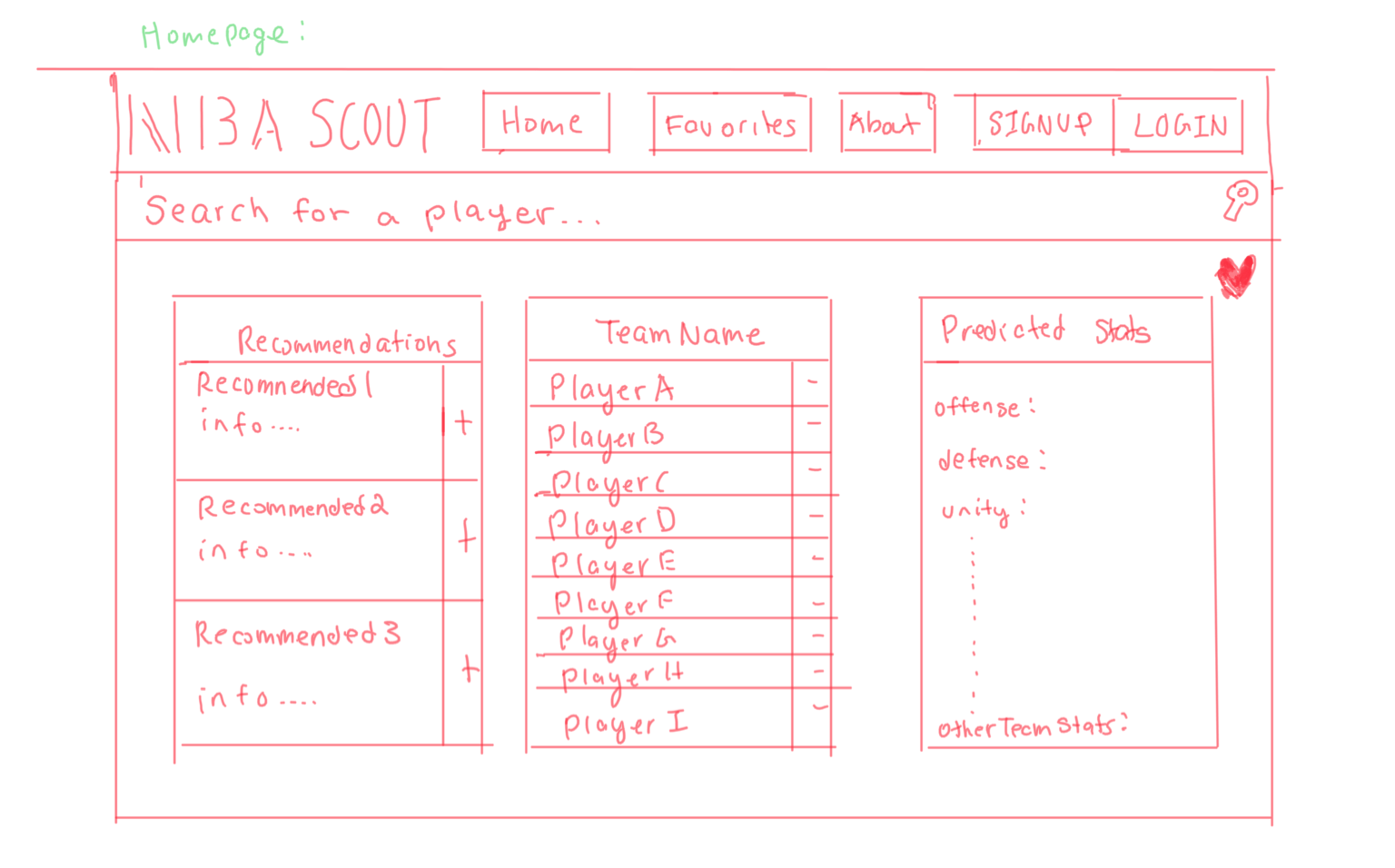
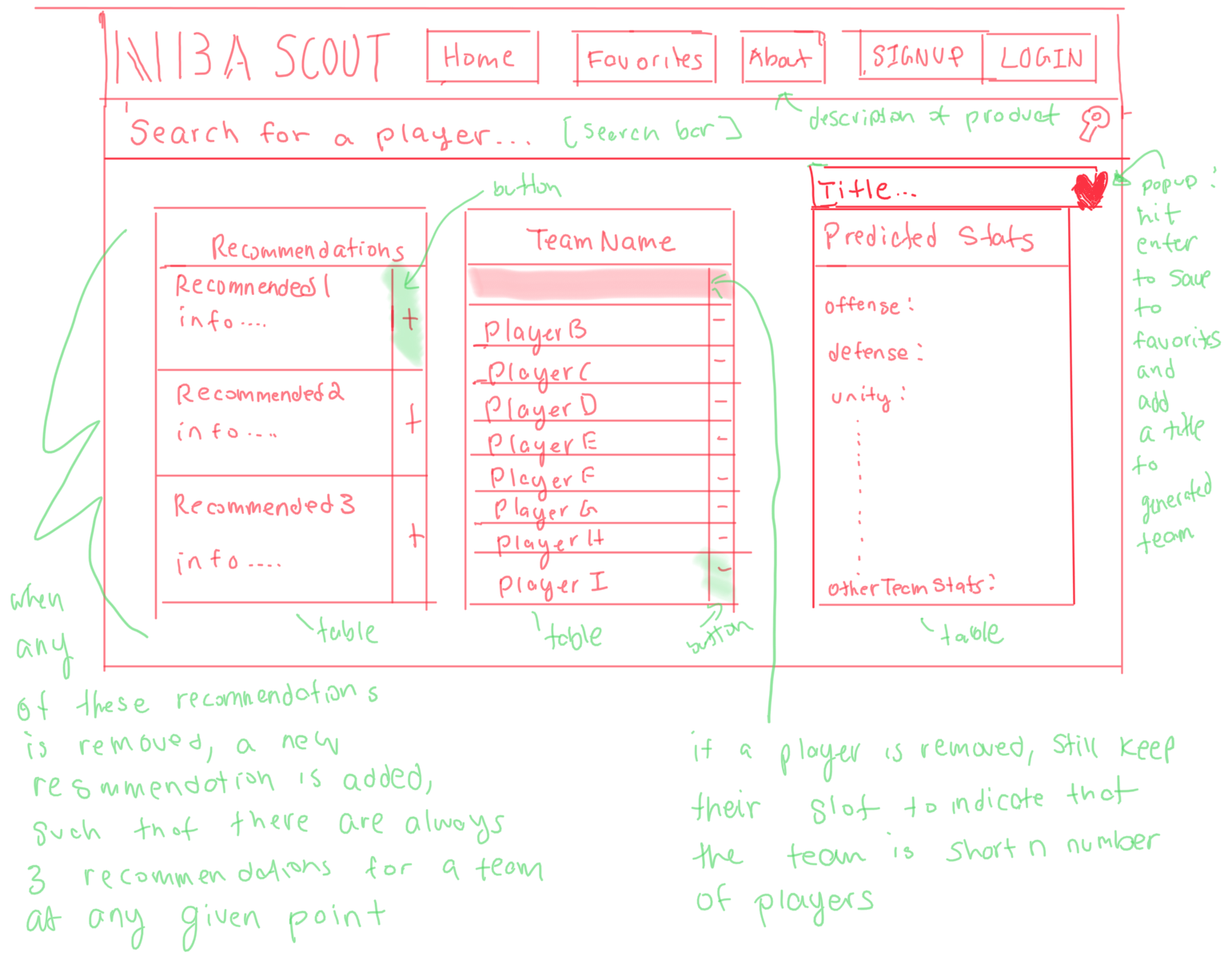
We ran into many difficulties while taking our project from prototype to final product. We had to constantly refine our database schemas and user-interface as we encountered new challenges and developed new ideas. Initially, we had planned to have a “favorites” tab within our website. This “favorites” tab would allow a basketball scout to store information about their respective team and generate new combinations for his or her assigned team. However, we soon realized that implementing such a system would be too difficult to implement in the limited amount of time that we had. Consequently, we refined our project, such that data would only be stored locally once a particular scout logged in. Another major change that differed from our original design was our UI. We had originally planned to have the UI as shown below:


However, we were having many issues integrating our initial UI with our backend. Moreover, we realized that we could create an even more user-friendly interface by allowing the user to type in player information as opposed to clicking on players to add them to their player's table.
Challenges + What I Learned
One of the biggest technical challenges that we encountered was with using python libraries such as pandas, NumPy, and sklearn simultaneously. We were using many different libraries and the format of the data that each of the libraries required often varied. For example, oftentimes we had to convert arrays into “series” or “data frames” when we were working with pandas, while we had to convert data into “NumPy arrays” when we wanted to utilize the functions of NumPy. This was extremely challenging because we had to constantly convert data from one form to another and sometimes there were no easy solutions to accomplish this. If we were to redo the project again, we would advise ourselves to become familiar with the data-types associated with each library, prior to beginning the assignment.
Another major challenge that we encountered was linking our front-end to the back-end. Initially, when we tried to integrate our front-end to the back-end, we were not able to preserve styling. While we were able to support HTML and javascript, our CSS did not show up. We realized that we could resolve this issue by restructuring the paths to our HTML pages. If I were to do this project again, I would first plan out the framework of how the pages would be linked and connected, prior to coding, as it would help resolve complications in the integration process.
Team Work Makes the Dream Work
To manage the teamwork we decide to divide and conquer the work into two teams where one handles the front end and the other handles the back end
Jasneet: Worked equally on front-end and back-end. Was responsible for developing the K-Cross validation model, as well as creating components on the front-end (particularly the team roster table), integrating the front-end with the backend using Flask and Jinja, and creating CRUD functionality for the database. Also handled preprocessing and refinement of data.
Arjun: Worked on preprocessing the data, implementing the machine learning (VIF) algorithm and simulations, as well as communications between the front end and back end.
Neil: Worked on authentication and scout db design, wrote backend queries and connections, and html/css formatting.
Wajid: Worked on the front end side and created a navigation bar for users. Also helped connecting front end to back end integration and assisted in writing CRUD queries.

Log in or sign up for Devpost to join the conversation.