Inspiration
In Senegal, millions of people live below the poverty line and are eligible for government support programs but never access them. The barrier isn't eligibility. It's navigation: 25+ programs are spread across multiple ministries, eligibility rules are written in bureaucratic language, and applicants need to know which document to bring, which office to visit, which number to call.
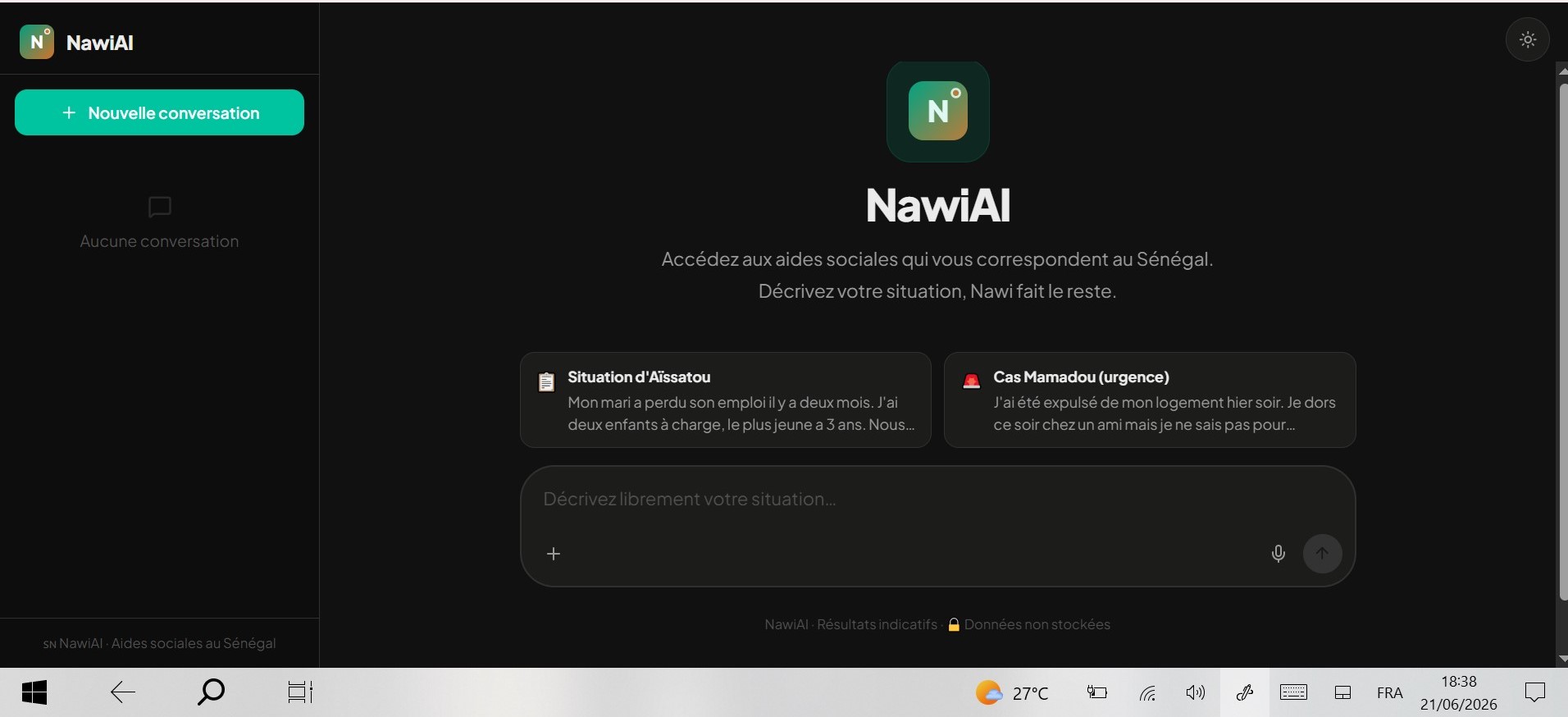
We kept coming back to three people who represent this gap differently. Aïssatou is unemployed, has two children, lives in Dakar's Médina district she likely qualifies for PNBSF, CMU, and ANPEJ training, but has no way to discover that without days of office visits. Mariama is pregnant and was just thrown out by her husband she needs a phone number tonight, not a form. Mamadou was evicted and has nowhere to sleep he needs SAMU Social, not a benefits brochure.
NawiAI was built to handle all three, in one conversation, in plain French or Wolof.
What it does
You describe your situation in your own words typed or spoken, in French or Wolof. NawiAI extracts what matters (employment status, location, children, housing, household size, urgency level), matches it against 25 real Senegalese social programs, and returns a ranked list with a confidence score, required documents, and direct contact information phone number, address, next concrete step.
If anything in your message signals real danger eviction tonight, domestic violence, suicidal language, a missing meal for your child a crisis overlay appears in under 50 milliseconds, before any AI model has even started processing your message. That response is deterministic, not generated: a fixed list of keyword matches, not a language model's judgment call.
The result, end to end: what used to take Aïssatou two days and three office visits now takes about 8 seconds and one sentence.
How we built it
NawiAI runs a five-stage pipeline, each stage with a precise input/output contract:
Stage 0 Urgency Detector. Synchronous, no LLM involved. A deterministic regex match against ~40 keywords in French and Wolof, under 50ms. If triggered, a full-screen crisis overlay and hotline number appear immediately the rest of the pipeline keeps running underneath, but the user already has help on screen.
Stage 1 Analyste (Llama 3.1 8B, NVIDIA NIM). Reads the message plus the last 6 turns of conversation and any entities already extracted from earlier in the chat. Outputs structured JSON: intent (asking about eligibility, asking how a process works, sharing info, changing topic, asking for clarification, or greeting), topic focus, and a full entity set employment status, location, children, housing, household size, age, gender, sector, urgency level plus a completeness score and a signal for whether a live web search would help.
Rule-based matching engine (not AI). Takes the extracted entities and scores them against all 25 programs using weighted boolean criteria, with a 40% minimum confidence threshold. This stage is deliberately not a model every match needs a criterion-by-criterion explanation, which a rules engine gives for free and a language model would have to be trusted to report honestly.
Stage 2 Raisonneur (GPT-OSS 120B, NVIDIA NIM). Only activates for eligibility or process questions skipped entirely for simple information-sharing or greetings, saving real latency where deep reasoning isn't needed. Takes the matched programs plus optional Tavily search context and handles the edge cases rule-based matching can't: informal sector workers, foreign residents, mixed household situations.
Stage 3 Compositeur (Nemotron-3-Super 120B, NVIDIA NIM). Writes the final response, streamed token by token over server-sent events so the reply builds character by character instead of arriving all at once perceived latency drops from roughly 8 seconds to under 1 second to first token. The model's internal reasoning tags are stripped in real time before anything reaches the user.
Voice, in parallel. Audio is recorded at 16kHz mono in the browser, sent to a dedicated Python/FastAPI microservice, and transcribed via NVIDIA Riva running Whisper Large v3 over gRPC, with automatic language detection across French, Wolof, and English. The transcript then enters the same pipeline as typed text.
Frontend: React 19 with Vite and TanStack Router. Backend: NestJS. No database 25 programs, hotlines, and Senegal's regional data live in static JSON loaded into memory at startup, manually compiled from official sources (dgpsn.sn, agencecmu.sn, anpej.sn, social.gouv.sn, ANSD). A capped in-memory audit log tracks aggregate usage signals only never the user's actual text.
Challenges we ran into
The hardest design decision was keeping crisis detection completely separate from the AI pipeline rather than asking a model to flag emergencies itself. It would have been simpler to let Stage 1 classify urgency as part of its normal output. We didn't, because a model can misread phrasing, an API call can time out, and a confidence threshold can be wrong none of which is acceptable when the message says "je veux mourir." The urgency detector runs synchronously, before any model call, on both client and server, with a hardcoded hotline fallback that returns a number even if the program data is empty.
Performance was the second real challenge. An 8-second wait for a first response is too long when someone is asking from a moment of real stress. Streaming the final stage token-by-token brought perceived latency under a second, and skipping the 120B reasoning stage entirely for simple greetings or information-sharing saved roughly 3 seconds per turn where it wasn't needed.
Accomplishments that we're proud of
That the crisis overlay is provably independent of model behavior it's a regex match, not a language model's opinion, and it's positioned to render above everything else in the interface unconditionally. We can say with confidence that a model having a bad day, a slow API, or an ambiguous phrasing can't delay it.
We're also proud that "Aïssatou's two days and three offices" became "one sentence and eight seconds" without losing the honesty of the system every program match still shows "likely eligible" with a percentage, never a flat "you qualify."
What we learned
That the safest place for a model to have power is the place where being wrong is recoverable. Eligibility reasoning is exactly that place a wrong "likely eligible at 65%" sends someone to an office where a human corrects it. Crisis detection is not that place, which is why it's the one part of the system we deliberately built without a model in the loop at all.
What's next for NawiAI
Expanding past the initial 25 programs, moving from a one-time manually compiled dataset to a scheduled re-verification process, and testing the Wolof detection with native speakers outside the team who built it. Longer term, a version for case workers handling multiple people's situations at once, built on the same five-stage pipeline.
Built With
- fastapi
- gpt-oss-120b
- grpc
- llama-3.1-8b
- nemotron-3-super-120b
- nestjs
- nvidia-nim
- nvidia-riva
- python
- react
- server-sent-events
- tailwind-css
- tanstack-router
- tavily
- typescript
- vite
- whisper-large-v3


Log in or sign up for Devpost to join the conversation.