-
-
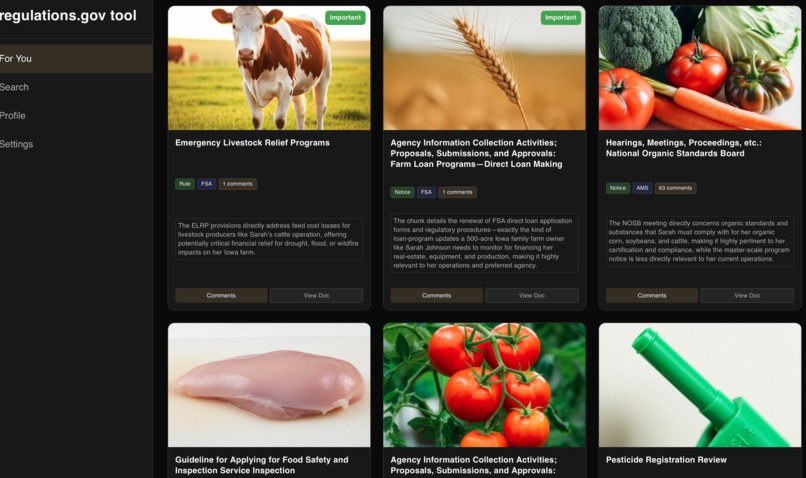
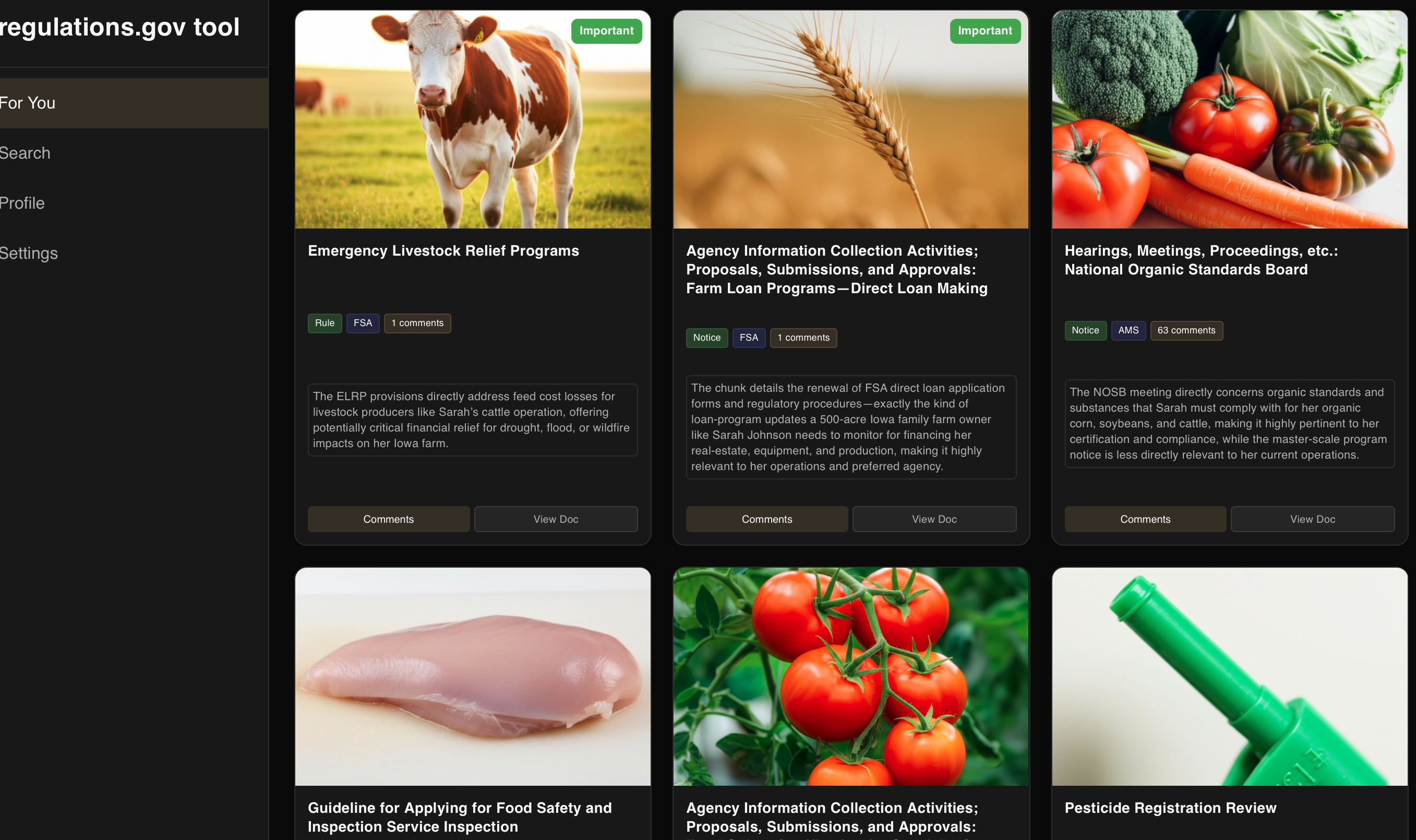
matches with thumbnails and relevancy analysis
-
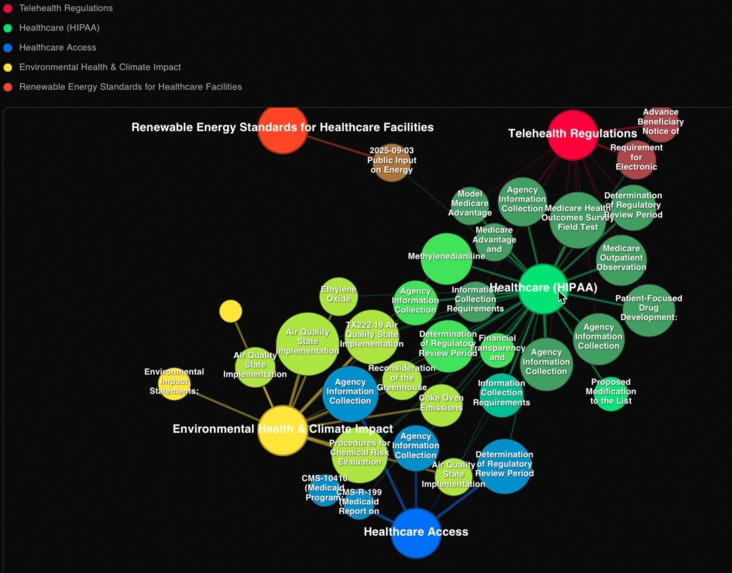
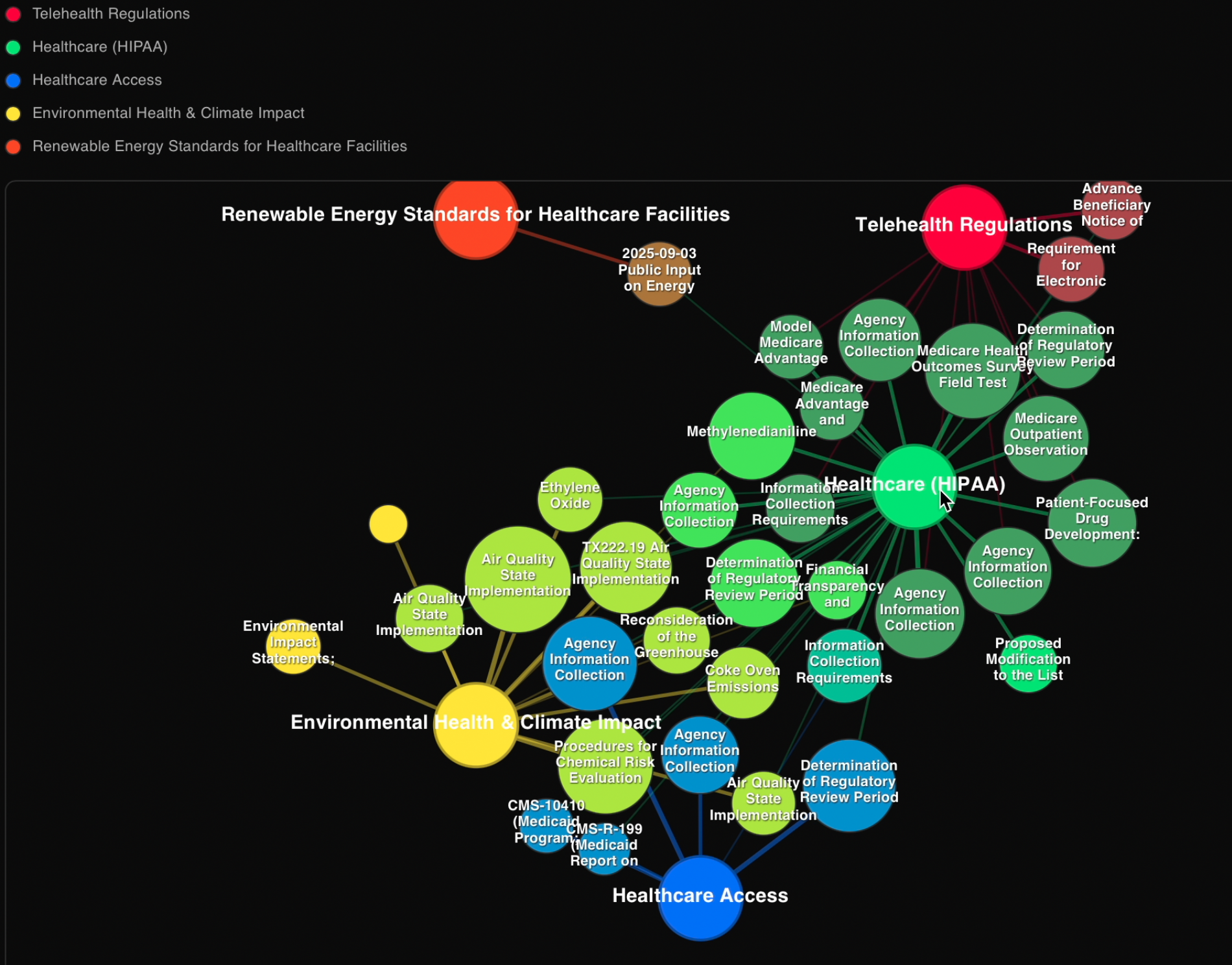
force directed graph visualization of matchmaking algorithm
-
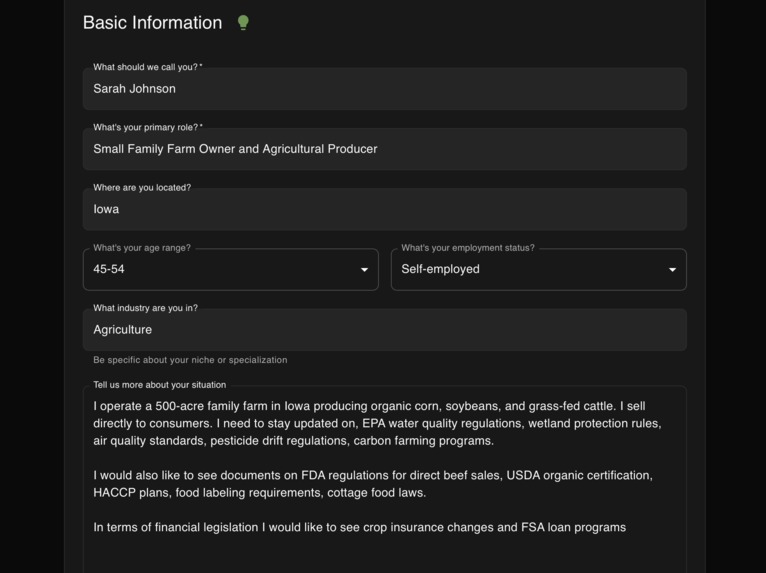
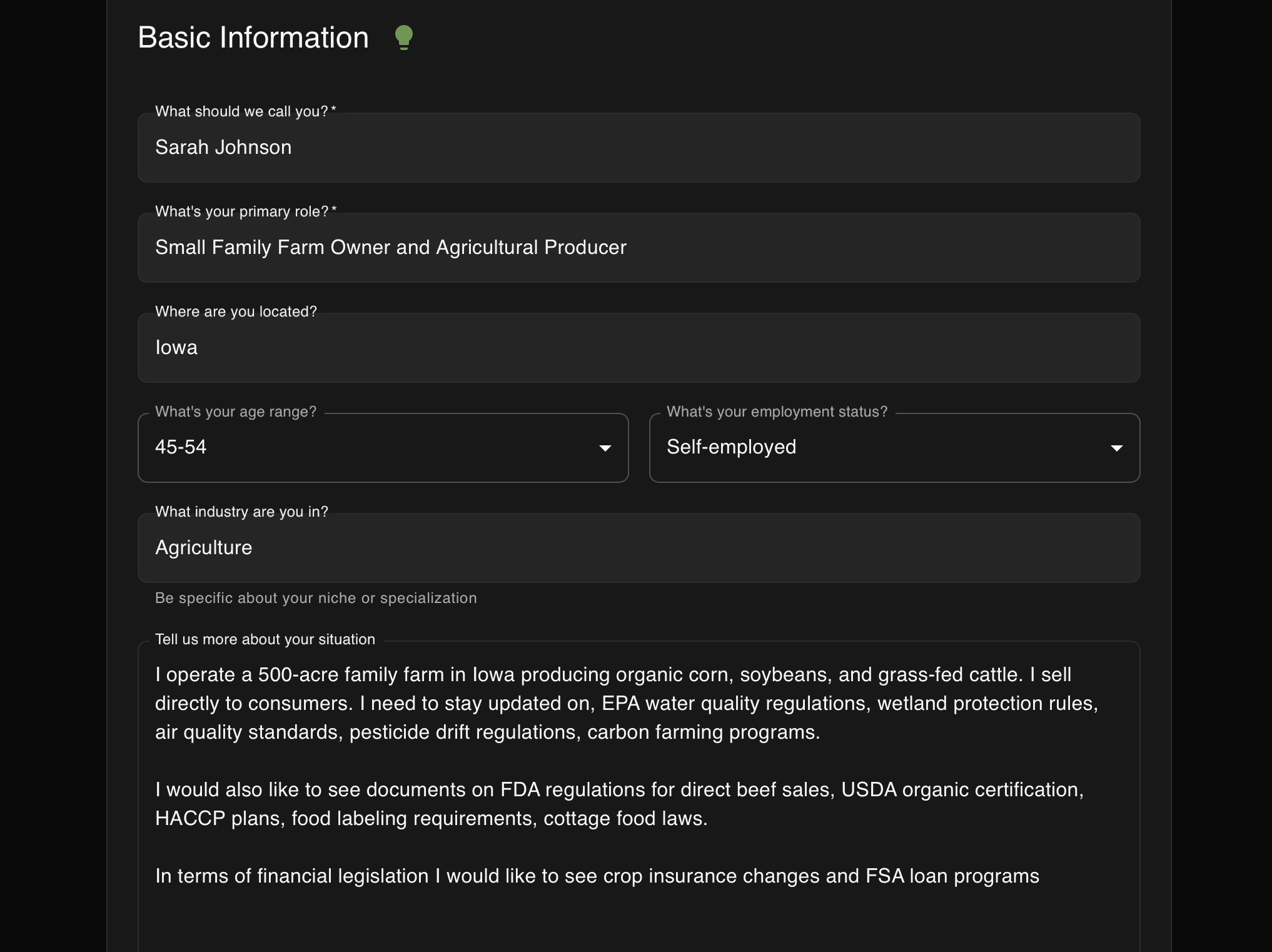
account creation
-
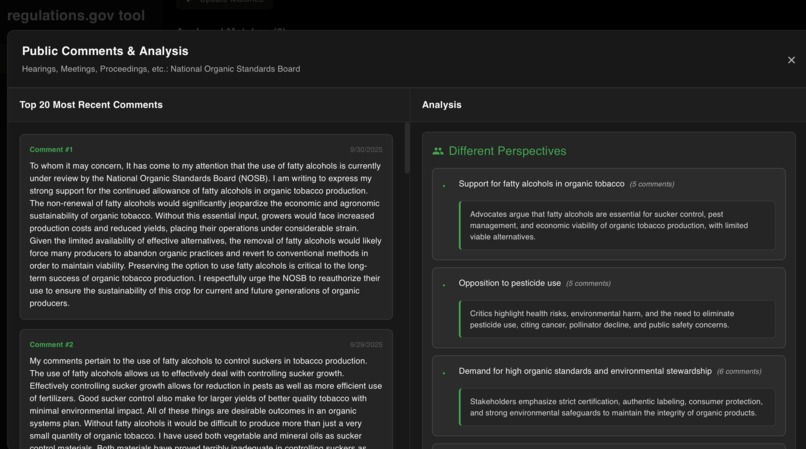
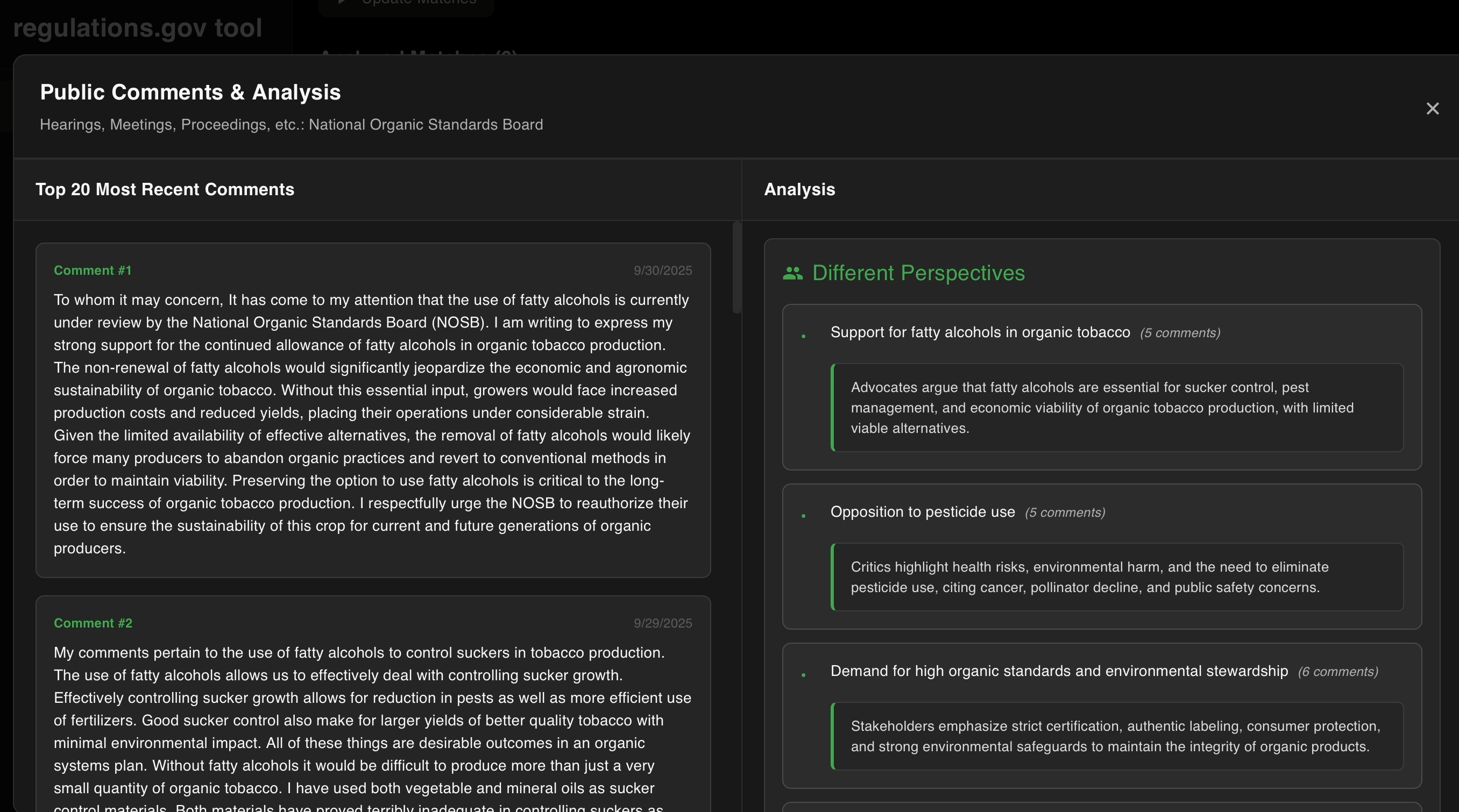
comment analysis of different perspectives
-
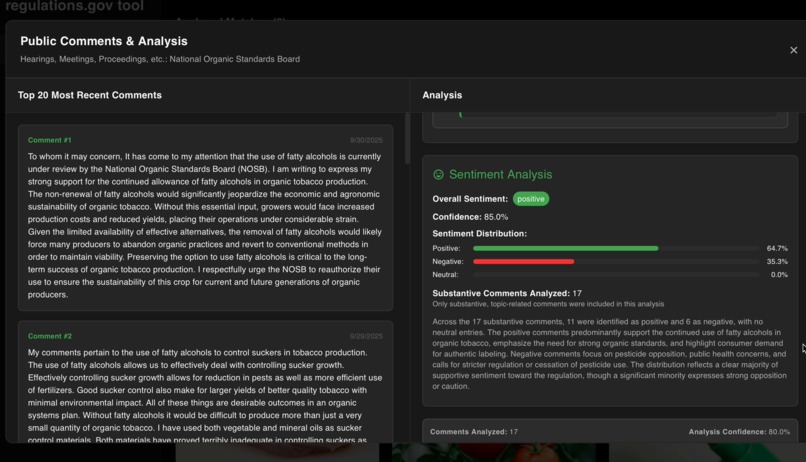
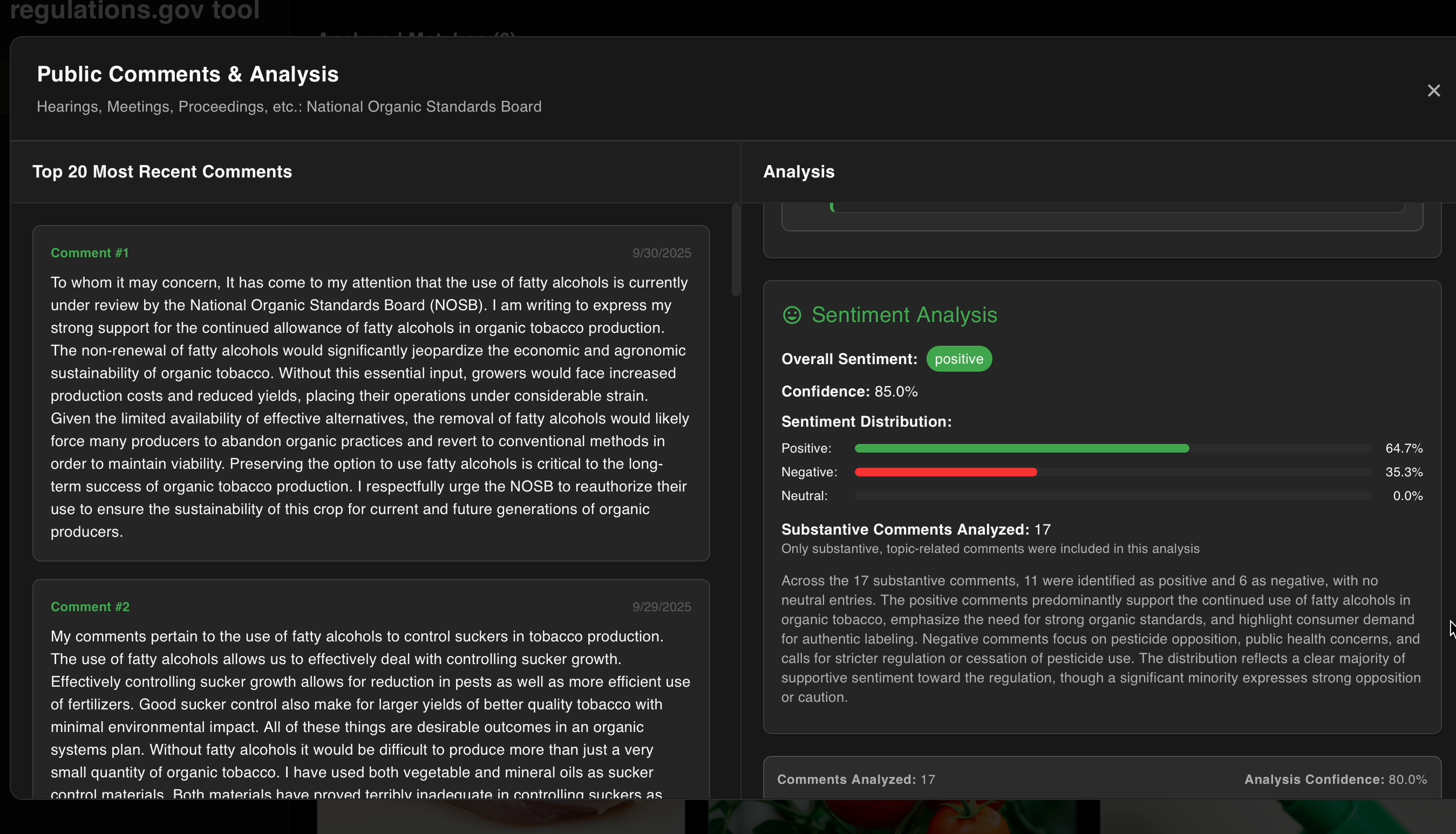
comment analysis of sentiments
-
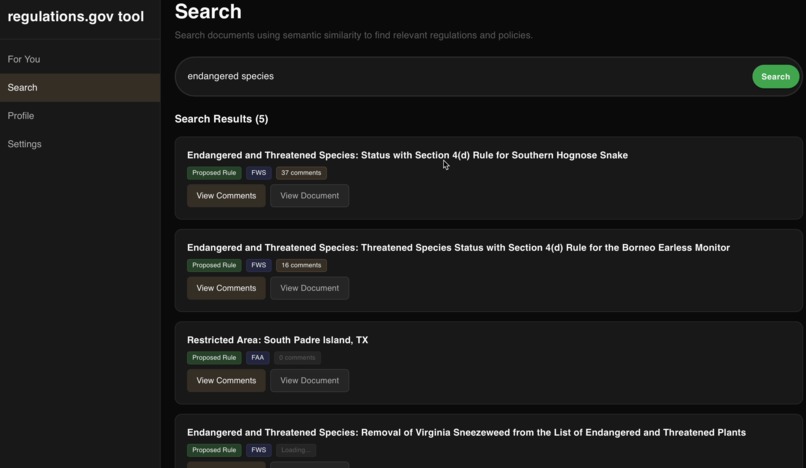
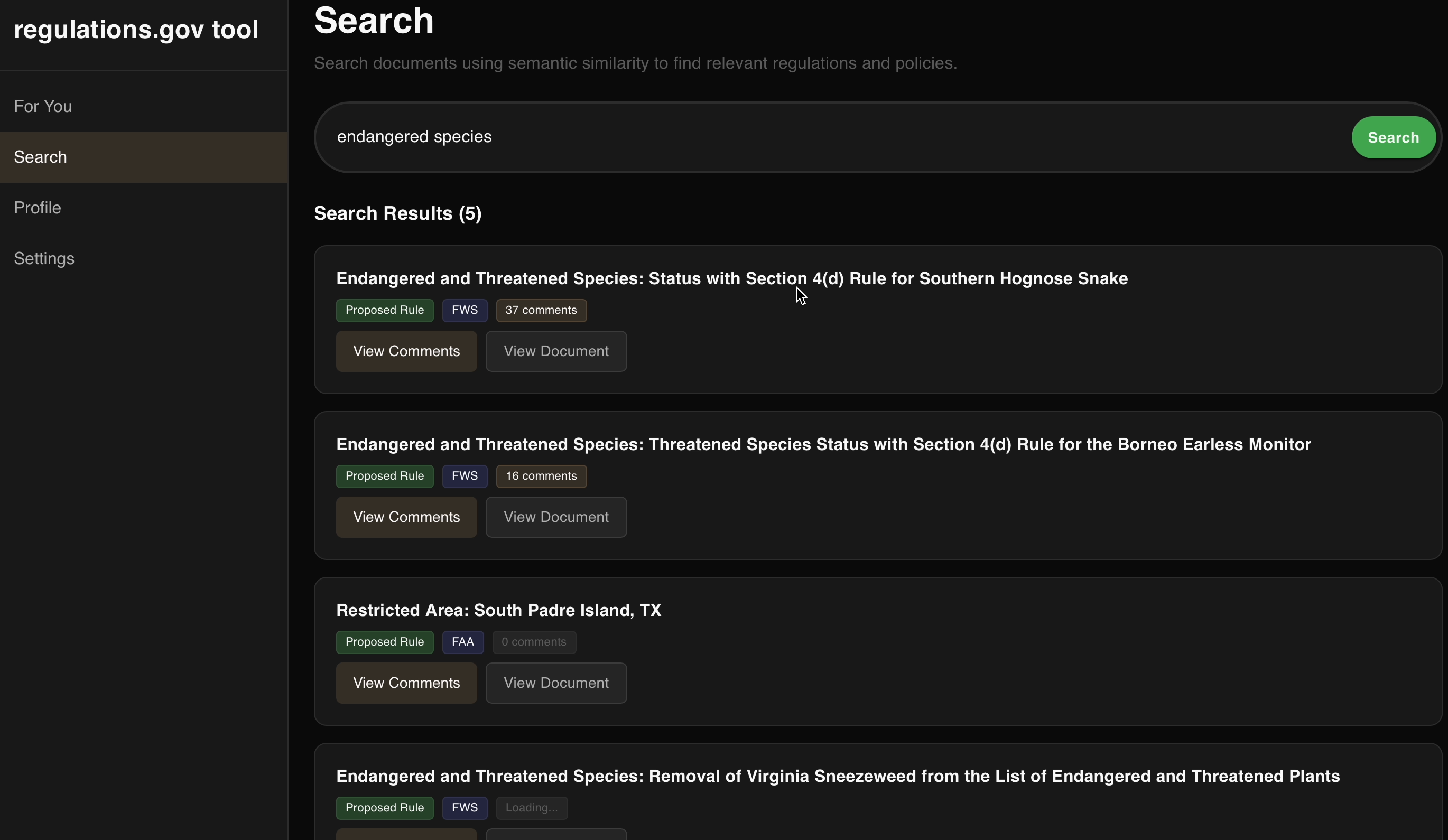
search
According to a 2023 Partnership for Public Service survey, only 1 in 5 Americans believe the Federal Government listens to the public. However, Research from the Organization for Economic Cooperation and Development shows that when people believe their feedback will be used, they trust government 60% of the time—triple the rate when they don't feel heard.
To remedy this problem, I built a prototype desktop app that sources documents from regulations.gov and matches them to user interests. For example, an environmentalist would be matched with documents on air pollution, where they can comment and see other perspectives.
I collaborated with my high school US Government teacher throughout development, incorporating their perspective and feedback to keep the design user-centric and practical.
𝐊𝐞𝐲 𝐅𝐞𝐚𝐭𝐮𝐫𝐞𝐬:
- Profile creation with document matchmaking that identifies relevant documents with AI insights explaining how it is relevant
- Comment analysis that reveals different perspectives on policy documents and general public sentiments
- Keyword search to help users find specific regulations they care about
𝐖𝐡𝐚𝐭 𝐈 𝐋𝐞𝐚𝐫𝐧𝐞𝐝:
- Learned to build a RAG architecture from scratch, including how to properly embed, label, and chunk regulatory documents for effective semantic matching
- Developed custom matchmaking workflow inspired by force-directed graphs, learning to combine semantic embeddings with user profile attributes by treating documents and user interests as nodes with attraction forces based on similarity scores
- Learned to build an automated data ingestion pipeline using N8N and Supabase that runs weekly to process new policy documents from the regulations.gov API, all hosted on Docker
- Built desktop application using Tauri to wrap a React and TypeScript frontend, learning how to combine web technologies with native desktop capabilities
- Gained experience working within the constraints of local AI models and limited VRAM, learning to optimize the system so users can configure their own Ollama models with all analysis happening locally to protect personal data
- Developed hands-on skills writing CRUD APIs with Express.js, learning to integrate both SQLite for structured data and Qdrant for vector search, and implementing thumbnail generation using Gemini text to image models
Built With
- docker
- express.js
- n8n
- ollama
- qdrant
- sqlite
- supabase
- tauri
- typescript

Log in or sign up for Devpost to join the conversation.