



Inspiration
Since taking a U.S. government course in high school with a passionate teacher, I've always valued civic engagement. However, as a busy college student, it can get difficult to stay up to date. Navi helps people find relevant government notices, proposed rules, and legislation (from regulations.gov) where they can comment, see what other people are commenting, and stay up to date on what they care about. This AI desktop app helps people stay informed on regulations they care about, encourages civic participation and protects user data with local processing.
What it does
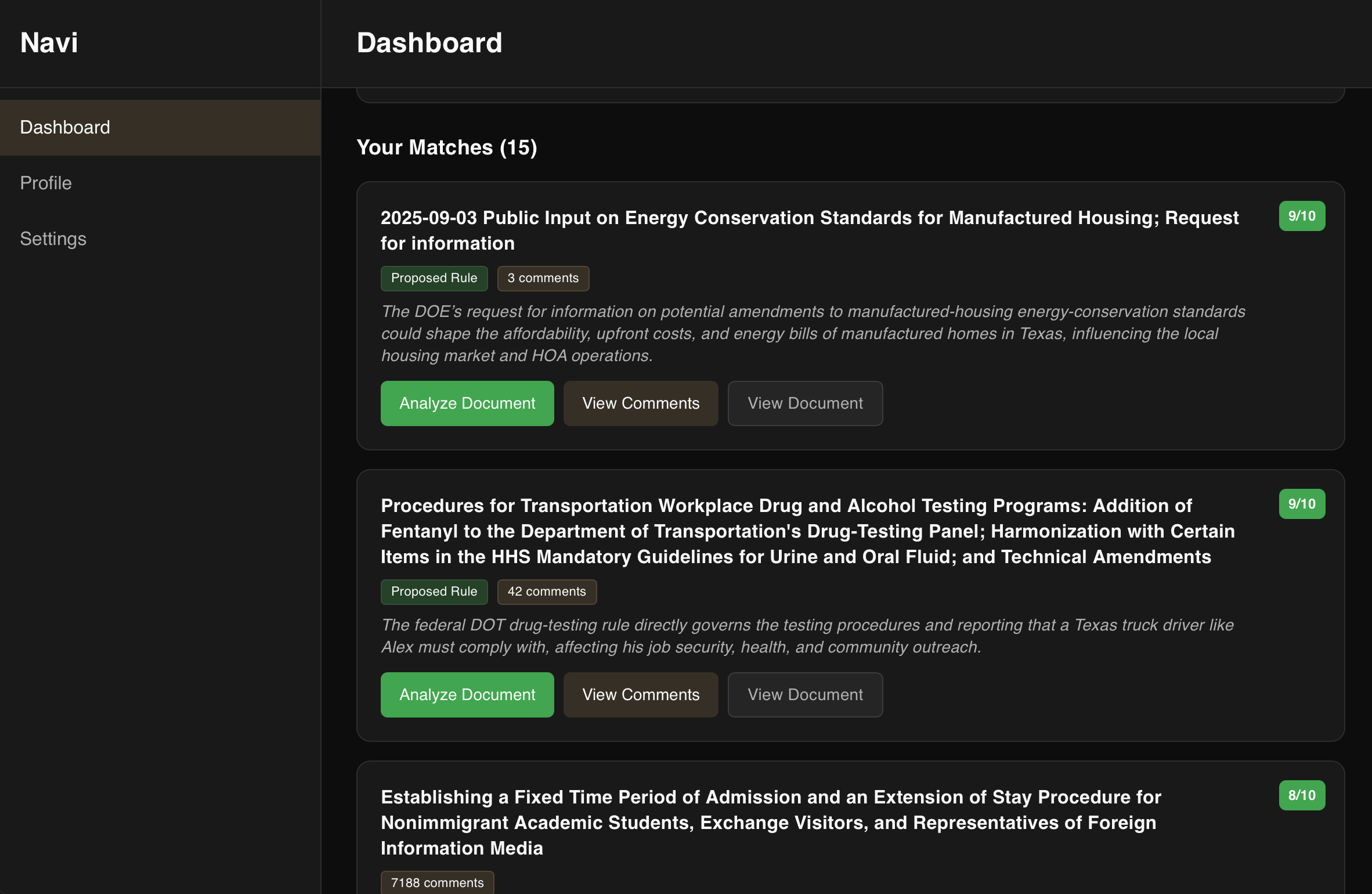
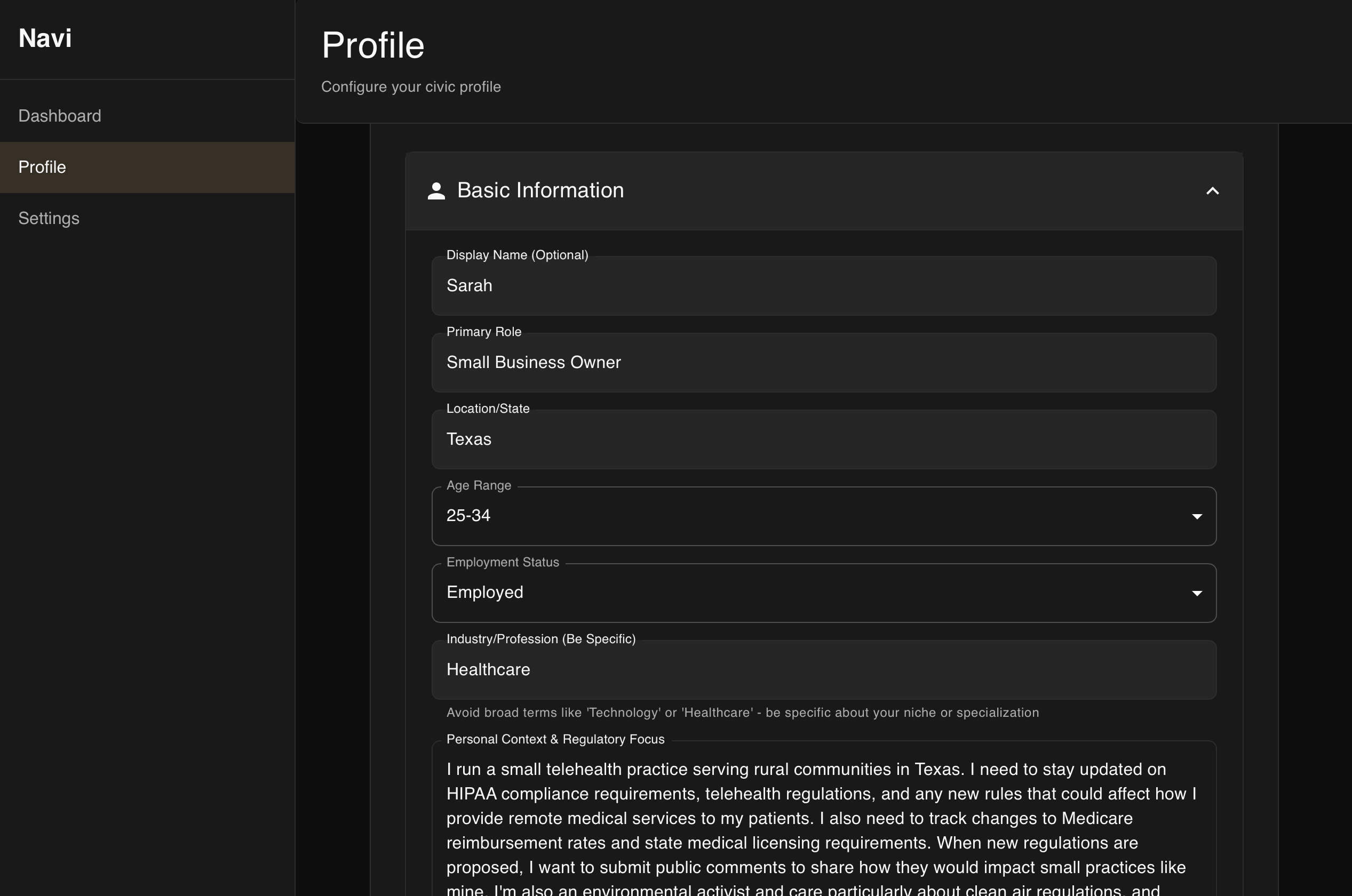
Navi is a user-centric desktop application that matches your profile with relevant comment boards on notices, proposed rules, and regulations posted on regulations.gov. The app uses RAG for semantic matching and gpt-oss:20b reasoning to match user profiles with regulatory documents that are relevant to their profile.
All personal data and AI processing happens locally using ollama and the gpt-oss:20b model, ensuring complete privacy and data protection. The application can function entirely offline once documents are downloaded, providing secure access to regulatory information.
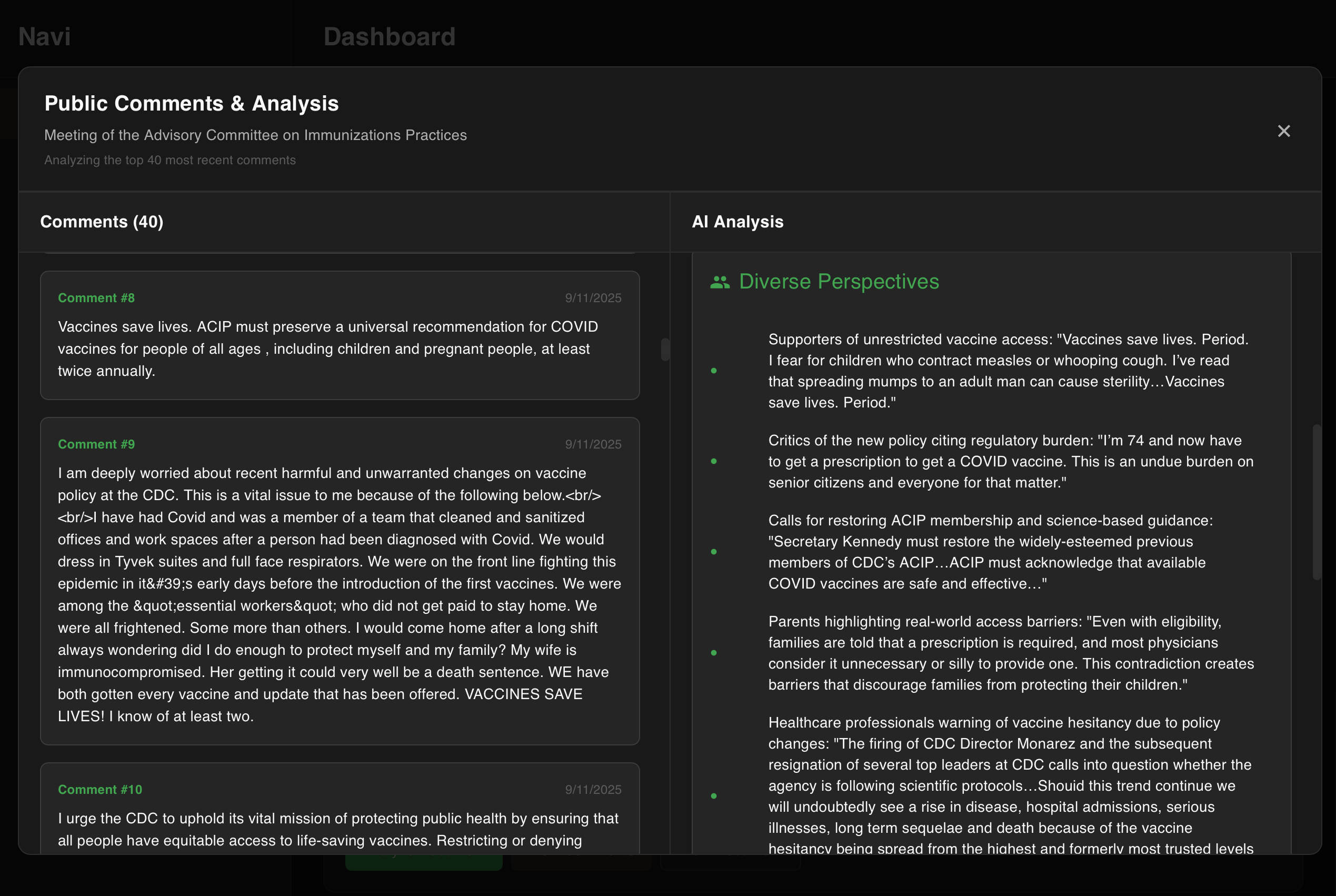
When online, the model has tools to fetch and analyze comment boards for different perspectives, common points, and overall sentiment on notices, proposed rules, and regulation.
How we built it
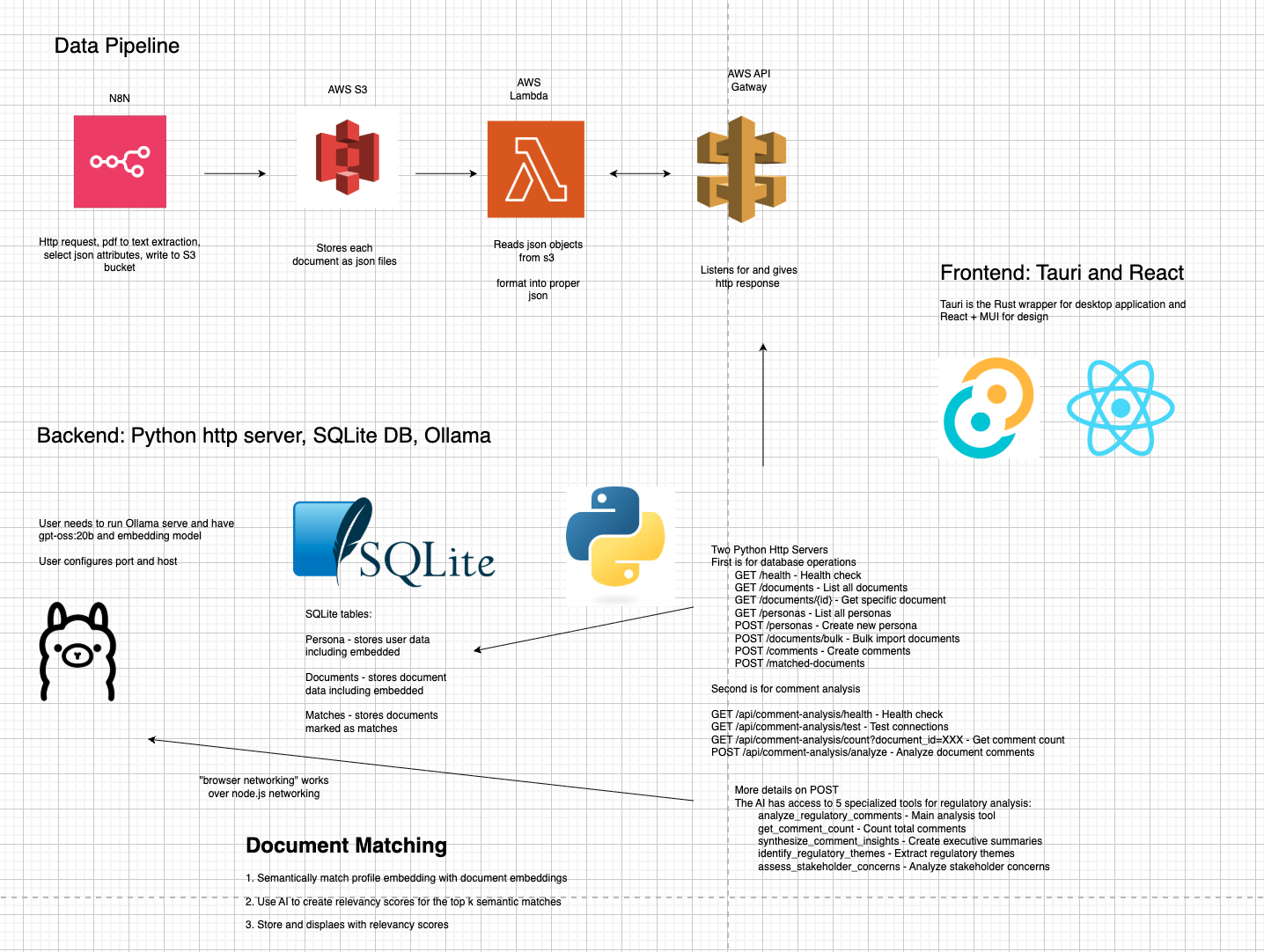
Frontend - The desktop application is built using Tauri 2, which combines Rust for the desktop wrapper with React and TypeScript for the user interface. The UI is constructed using Material-UI components, providing a clean and modern interface. Vite serves as the build tool and development server.
Backend Services - The core backend consists of two Python-based services running independently. The main API server operates on port 8001 and provides RESTful endpoints for managing personas, documents, and semantic matching data using SQLite as the local database. An optional comment analysis server runs on port 8080, offering enhanced AI-powered analysis of public comments from regulatory documents. Both services use Python's built-in HTTP server with minimal external dependencies, focusing on simplicity and reliability.
AI - Navi integrates with Ollama for local AI model inference, using gpt-oss:20b for document analysis. The user can configure any embedding model they would like for the embeddings. The RAG system processes documents in 2,000-word chunks to handle large regulatory texts efficiently, then combines chunks for comprehensive analysis. Documents are chunked, labeled, vectorized, and semantically matched between user personas and government documents, while AI models provide relevancy scoring and summary. With python functions, the model can fetch comments from documents on regulations.gov for analysis when online to share insights on what other people are saying and overall sentiment.
Data Ingestion - I have an n8n workflow containerized in Docker that fetches and publishes document text and information to an S3 bucket. There is an AWS Lambda function that reads json data from S3 and exposes it on an API Gateway. When online, the application connects to an AWS API Gateway which gets document text and information from my s3 bucket and connects to the regulationos.gov API to retrieve public comments.
Development and Deployment - Python virtual environments isolate backend dependencies, while the tauri run process creates native desktop applications.
Built With
- amazon-web-services
- docker
- n8n
- ollama
- python
- react
- rust
- sqlite
- tauri
- typescript
- vite

Log in or sign up for Devpost to join the conversation.