






Inspiration
Our smart grid power distribution, based on a weather data analysis prediction, will make the power distribution more efficient and smarter. It will reduce waste which'll lead to a reduction of greenhouse gas emissions that will eventually help slow down global warming.
What it does
The power grid is basically distributing power to different areas that need, and you don't want to do this blindly. You want to to do this efficiently and smartly by taking in input from weather conditions. So that way we can determine which areas need to power the most under certain circumstances. For example, under high temperature, this would result in more AC usage which would result in more power needed in a specific. And vice versa for lower temperature will result in more heater usage and therefore more power.
Some of the resolutions for our smart grid, is that we could reroute power from low power consumption areas to high power consumptions areas. We could also increase power production to anticipate high power consumption that we foresee. As a contingency plan, if one power source goes down, we need to route power from another source. For instance, if we see a significant decrease in rain, this means we won't have enough power from hydropower and we need to outsource other power sources to compensate the loss such as nuclear or coal.
How we built it
We gather all the weather data on a daily basis and store it a in data lake. Then we perform ETL, which stands for extract, transform, and load, to get the data in the format we needed. Then we perform queries on our data using Microsoft Power BI. This is everything that we intended to complete by the end of the hackathon. Going further, the analysis we derived from our reports could then be used to drive machine learning models or algorithms. The models produced could then be served via a rest endpoint which could be queried by the power grid control center to determine how to control the flow of power to various regions based on weather conditions.
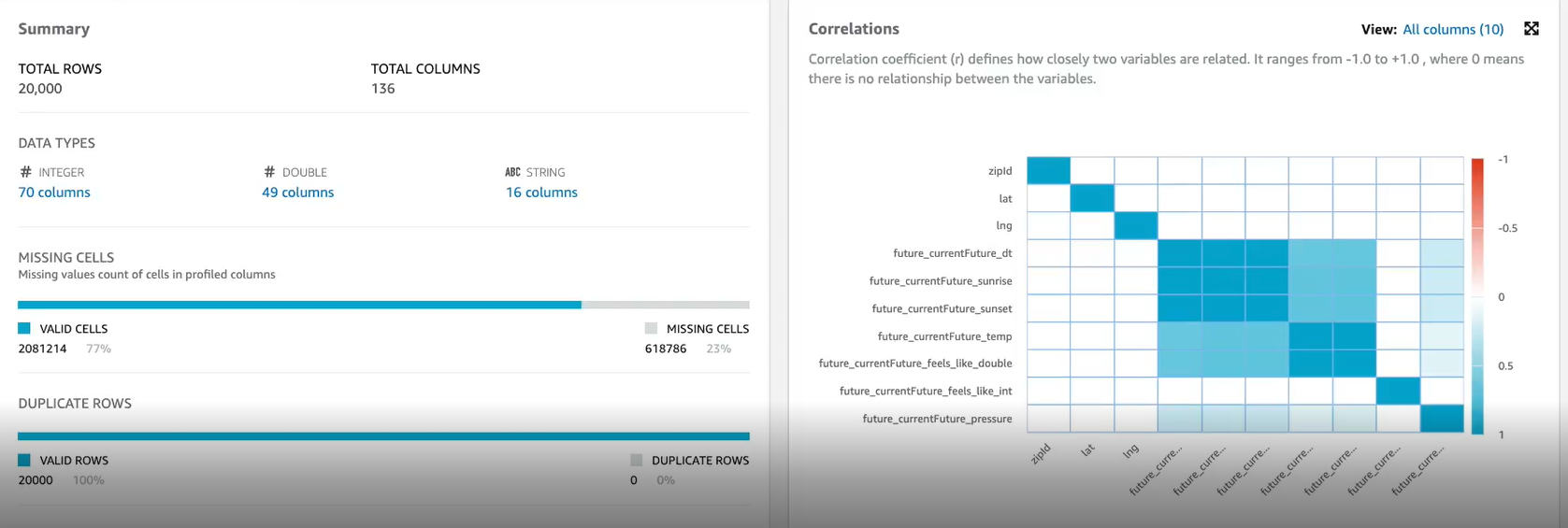
In further detail of our architecture, on step 1, we collect the weather data and store it in a data lake. For our test, we used weather data from Winter Park, Florida. On step 2, we used AWS Glue Studio to perform our ETL, store in a data lake, and create a schema out of it. Now on step 3, we used AWS Glue Databrew for its data profiling capabilities. Basically it was able to draw insights and relationships between different columns in our table which helped in determining which pieces of data would be relevant to our investigation. In the last step, we used AWS Athena as a query engine and the ODBC driver connector to make the connection to Power BI.
Challenges we ran into
Accomplishments that we're proud of
What we learned
In regards to the ETL, I found that I had to go through quite a lot of experimentation. For example, I found that I had to add an extra step to fill missing values on rain with 0 after seeing the charts in Databricks were missing so much rain data. Also there was limited resources for getting started with all of this. Spark is a narrow field of subject. For analytics, setting up all the resources before we even got to the analytics was one of the most challenging parts. Learning how to write DAX queries was also challenging as it was a new language to learn. Microsoft Power BI was a new tool for us to learn, and we found it quite powerful and imperative for data analysis.
What's next for Nature's Smart Grid
For ETL, the filling of missing values is still in the works as the json flattener seems to mess up with the data types of columns. We also need to test how efficient our ETL design is over a larger dataset. In regards to analytics, we could learn how to incorporate more DAX queries and also convert our DAX queries to SQL so that it can be used in production workloads
Built With
- amazon-web-services
- databricks
- dax
- intellij-idea
- mongodb
- powerbi
- scala
- sql



")
Log in or sign up for Devpost to join the conversation.