Inspiration
Most search systems are based on full-text search. This is generally okay for open domain search (Google) and provides a smooth experience. For closed-domain search, like searching for a particular activity or restaurant, the search criteria might be more complicated. The user might not be aware of the available search criteria, or may not be sure of what they are looking for. In addition, not all users are proficient in using search system, for example: Elderly People. It is more possible to improve user experience for search by letting the user expressing their query in Natural Language. Using state-of-the-art machine learning, natural language processing and recent concepts of bot frameworks (DialogFlow), it is possible to uncover the semantics behind a user query with reasonable accuracy.
What it does
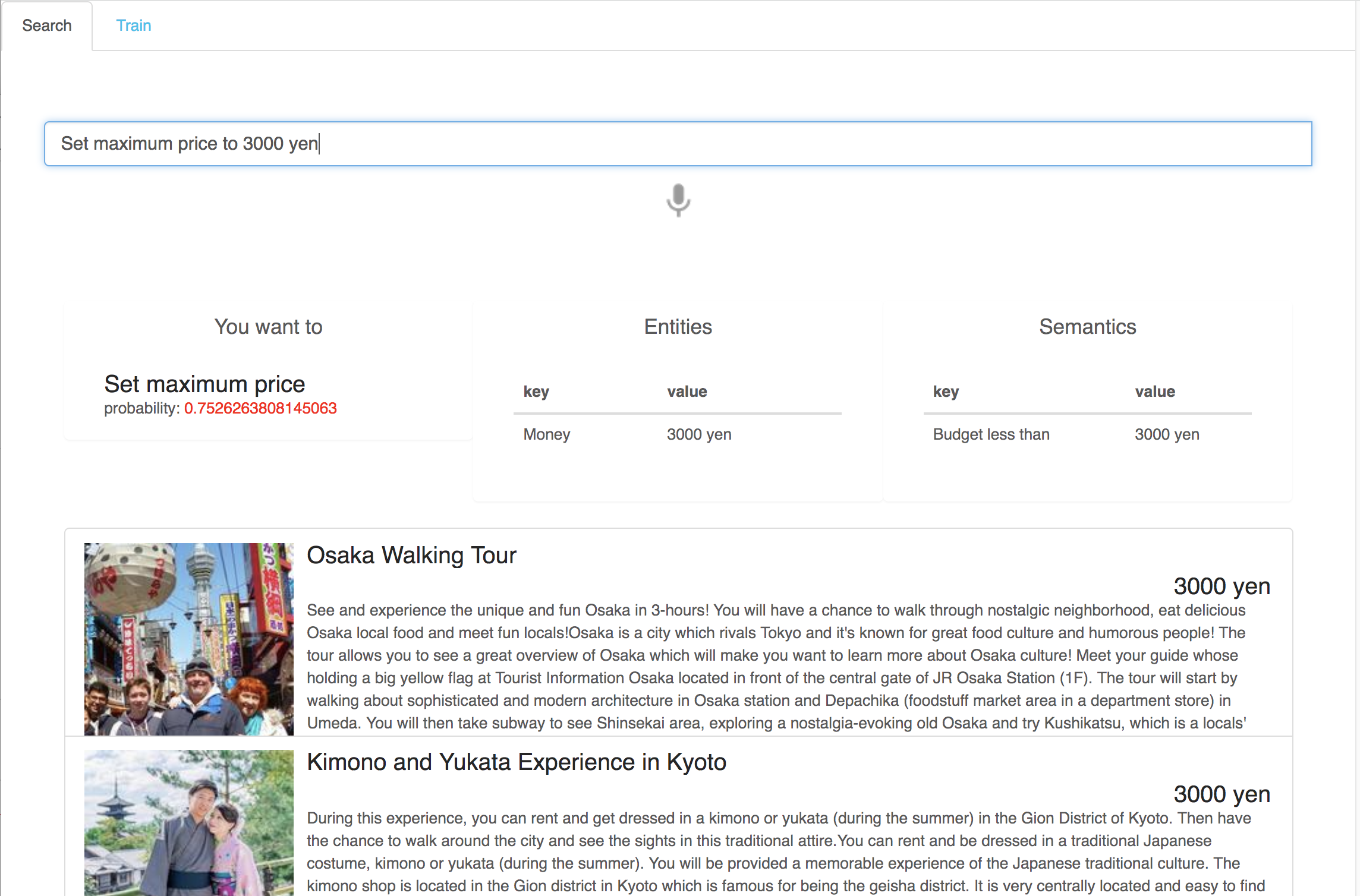
The user can write or speak their query in natural language: For example "I want to find locations near Shinjuku". The system will set the appropriate search criteria and show results. The system is fully trainable with custom intents, and possible to train interactively. It is possible to understand intent behind more ambiguous queries like "I am feeling stressed today". The system will then return results related to the concept "Relaxation".
How we built it
We built a simple trainable Natural Language Understanding (NLU) engine that can uncover intents and entities from a given user query. The intents and entities are extracted via a supervised model trained from labeled data. The information from the NLU engine is used to control a demo search interface we created. The relation between NLU results and search criteria are defined in another module call Semantic Search. The Semantic Search module can be trainable or rule-based. The search interface uses a dataset of activities collected from Veltra and Similar sites. We also implemented the Search engine and User Interface.
Challenges we ran into
We are a small team so we had to define roles and and project milestones early and stay focused. Our team consists of a Data Scientist, Front-end Engineer and a Business Associate. Since the project had multiple areas that required equal attention (Data Science, Front Eng, Server Infrastructure, UX and UI Design, Training data collection, Project Management), It was challenging to focus on different thing at once and set priorities. We feel we were able to pull through smoothly.
Accomplishments that we're proud of
Developed a Natural Language Understanding DialogFlow, (Microsoft LUIS) framework from scratch in two days. We can use it to train and infer our own Entity and Intent recognition models. It can support English, Japanese, Chinese and other languages. We hacked the RASA traning example annotation tool (https://github.com/RasaHQ/rasa-nlu-trainer) to collect examples collaboratively. We will integrate this into our search system and add a training button. This will allow us train our model interactively. Defined intents and entities specific to our use case, collected training data, and trained a sample NLU model.
What we learned
I am a Data Science person, but I learned more about User Experience and UI Design from this project. Also by working closely with a Front-end engineer I learned more about integrating ML models with web services and front-end smoothly. My team members also learned more about Machine Learning from me. More importantly, we learned about time management and collaboration.
What's next for Natural Language Semantic Search
Currently, by performing unsupervised clustering on the search contents, we can show "similar" or "related" to the current results. As an future step, we can use latent models to uncover semantic attributes from to our search contents. For example, attributes indicating whether the content is Touristy or Cultural, Exciting or Relaxing, Cold or Warm. By training a model to connect user expressed "Intents" to such latent attributes, we can deliver a true semantic search experience.
In our engine we are free to integrate any state-of-the-art Deep Learning or Machine learning model to improve accuracy.
Instead of Entities and Intents, use information more complex semantic models like Dependency Parsers.




Log in or sign up for Devpost to join the conversation.