-
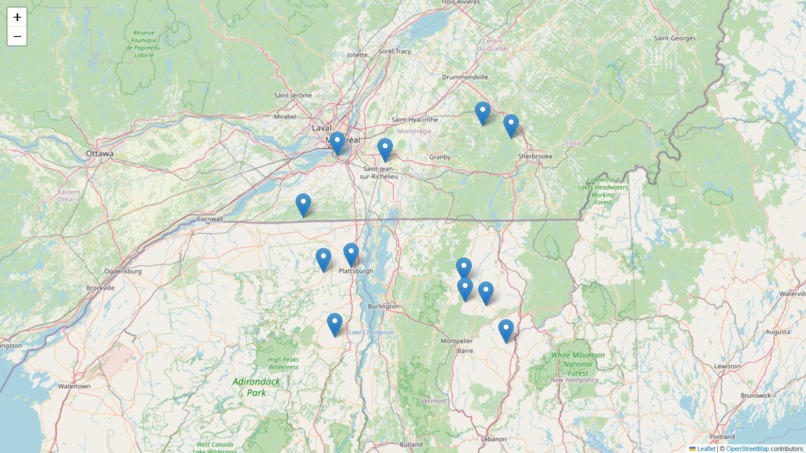
Wildfire Map
Inspiration
My inspiration was learning more about machine learning algorithms for prediction
What it does
The user inputs a CSV file to predict wildfires and display a map with markers for the wildfire locations.
How we built it
Using Python, and the recommended modules (numpy, pandas (for the DataFrames and CSV file processing, scikit-learn (for the Random Tree Model), and folium (for the creation of the map)) as well as the module (os and webbrowser) to automatically open the map
Challenges we ran into
My first challenge was my uncertainty on whether the deployment time meant that a unit could be reused; however, after clarifying with the SAP helpers in the debug room, I understood that unit's could not be reused and that fires had to be addressed as soon as they came up.
My second challenge was calculating the damage cost, since I modified the original dictionary when calculating the operational cost which resulted in having an incorrect damage cost. Thus, I made the total operation cost function create a deep-copy and only modify the copy to not affect other functions.
My third challenge was learning how to work with models, from reading the requirements.txt file which recommended the use of scikit-learn, I searched on Youtube for tutorials to train my first machine learning model (https://www.youtube.com/watch?v=29ZQ3TDGgRQ)
My fourth challenge was to compare the environmental data with the wildfire data to see which environmental data resulted in a wildfire data. After some internet searching, I found a stackoverflow solution by using the join method; however, the timestamps from the environmental and wildfire dataframes were not compatible. Thus, I opted convert the timestamp columns in both dataframes to a string, then created a new dataframe to store the environmental data as well as setting the fire risk by default to 0. Then, I iterated through the timestamps to find the ones matching with the wildfire data and changed the fire risk to 1.
My fifth challenge was that my first choice of model was not suited for the wild fire. At first, I chose the Random Tree Regressor which was used when one wanted to find the quantitative "numerical" output with a set of independent outputs. However, for the wild fire scenario, the data was in fact qualitative since it was whether a wild fire Started or Not, so 2 cases. However, the regressor model allowed for values varying between 0-1 due to uncertainty, thus I had no data for when the fire risk was guaranteed since it never reached 1. Thus, I had to change to the Random Tree Classifier which would only allow the values 0 or 1 for the wild fires. Due to the nature of Random Tree Models, the predictions may slightly vary.
Accomplishments that we're proud of
Persevering despite all of the challenges, acquired experience on models and completed the project in a timely manner
What we learned
How to make use of pandas dataframes, learn how to train models and learn how Random Tree Models work (I recommend this video here: https://youtu.be/cIbj0WuK41w?si=2Jbm_LNkcxivwFQ1), and how to visualize data using folium to create maps.
What's next for Natsu SAP
There is no GUI and I look forward to implementing it as well as optimizing the runtime.
Built With
- csv
- folium
- numpy
- os
- pandas
- python
- randomforest
- scikit-learn
- webbrowser

Log in or sign up for Devpost to join the conversation.