
Native2Native
"A Voice and Text Recognition System Built to Specifically for Non-Native Speakers"
About
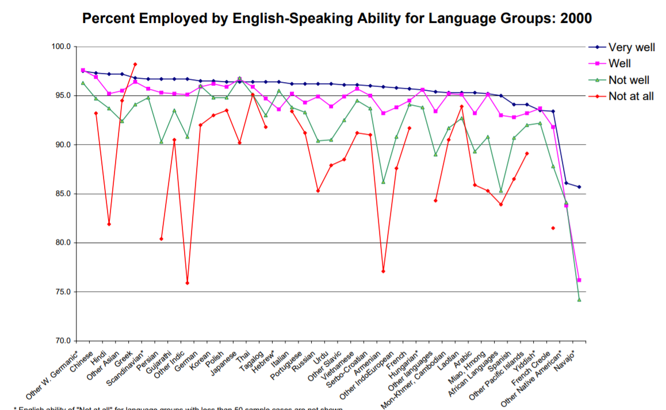
Our hackathon project for Hack.UVA 2018. According to the US Census, there is a high correlation between English speaking ability and employment rate, as well as self-confidence. This clearly puts immigrants and non-native speakers at a disadvantage in the United States. Image from US Census

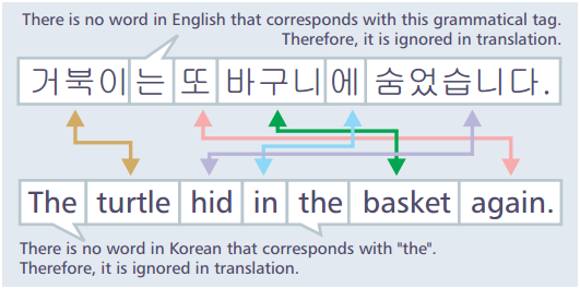
Current translating applications are very flawed. First of all, syntax and structure between East-Asian languages and Western languages are completely flipped, making translation an extremely difficult task. In addition, many words and phrases are unique to languages from specific cultures. Because of these two reasons, translations are usually inaccurate and lose information along the way. Image from here
![]()
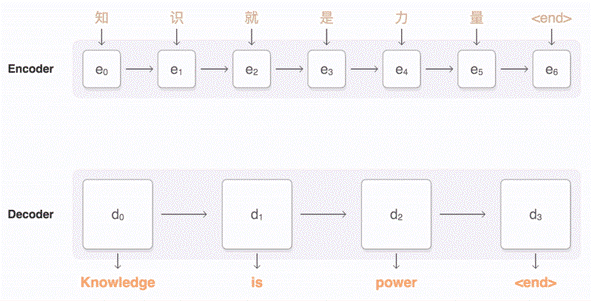
However, we have noticed that non-native English speakers know what they want to say; they're just unable to articulate it well. Instead of trying to improve faulty translators, why not start at the imperfect grammar of non-native speakers? Since people are still able to understand broken English, we hypothesize that there will be a lower loss of information from broken English to complete English. Native2Native is a Natural Language Processor that takes in a "difficult-to-understand" English sentence by a non-native speaker and completes it using Deep Learning, striving to be the "Native" voice for them. (The name "Native2Native" also comes from the Seq2Seq Recurrent Neural Network model used for our application) Unlike most modern speech and text recognition software which rely on translating fluent speech across languages, our solution aims to elevate flawed speech to fluency in the same language.
Purpose/Vision
Instead of focusing/training Voice-Recognition and Language-Recognition systems solely on eloquent English speech, we should also focus on dedicating them to the people who need these systems the most. In addition, non-native speakers are more likely to learn from corrections to their own English rather than translations of their own native languages. We hope the Native2Native will be a tool to equalize and empower immigrants by offering them a new voice and method to improve use of the English language and will motivate research towards "hard-to-understand" phrases rather than perfect English. Our vision is to generalize our technology and see more Voice-Recognition Models and Language-Translation Models train on data from non-natives rather than native speakers for all languages.
Algorithm
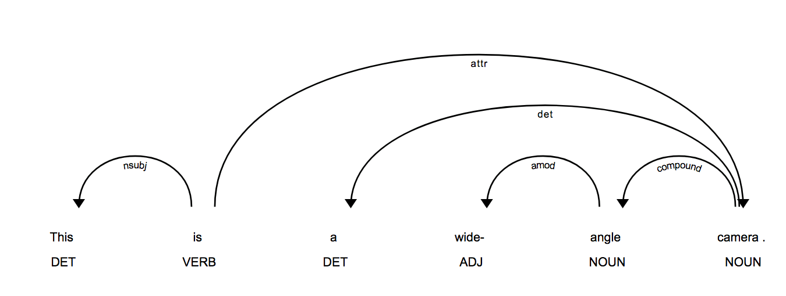
Our model trains on "non-native" sentences generated using SpaCy. SpaCy is a power natural language processing library. By labeling linguistic features, tagging parts of speech, and tracing dependencies, we were able to emulate a clever "non-native speaking" training data set for our neural network. This dataset includes proper sentences that were modified by removing stop-words (common, small words) and swapping nouns with neighboring adjectives or descriptive phrases. In the future, we hope to use real world data and have more time to train our models!
A Seq2Seq Recurrent Neural Network is used to train on these "non-native/incomplete" sentences and maps them to "complete" sentences. Seq2Seq is an encoder-decoder model that embeds sentences to a higher dimension and then decodes them to a target domain. The model was trained using an AWS EC2 P2 instance equipped with a NVIDIA Tesla K80 GPU. Image from here More specifically, our model was a variation of SimpleText, a RNN that explores the task of simplifying long sentences.
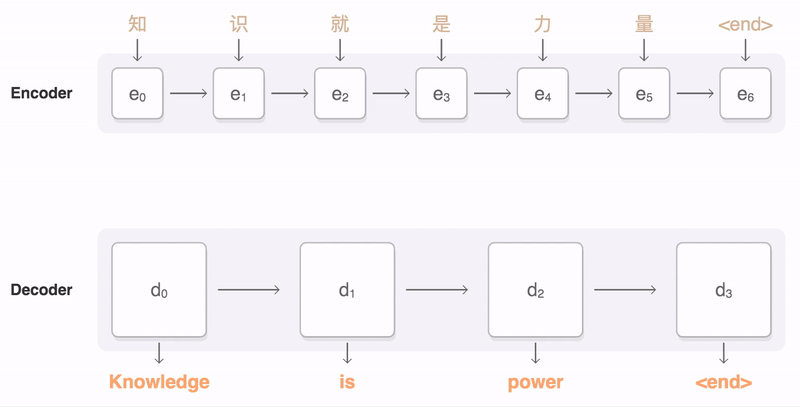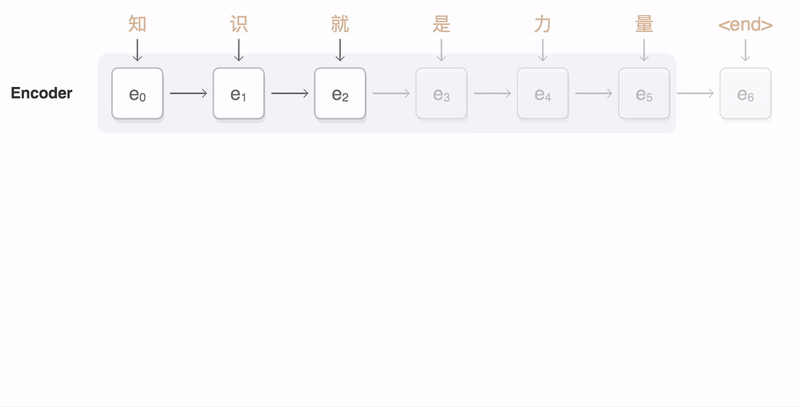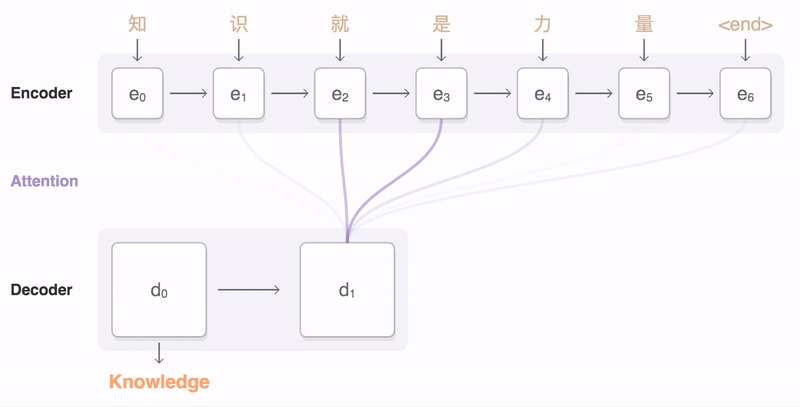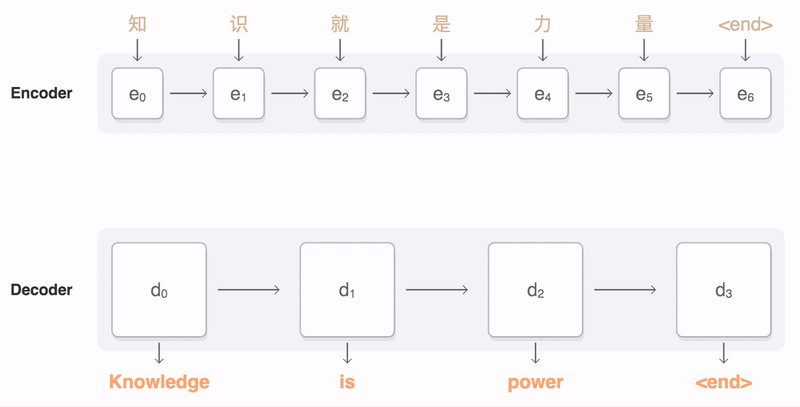
Our neural network is implemented with Pytorch and deployed using the SAP Cloud Platform.
Developers
Fengyang Zhang
Felix Park
Yutong Wang
Jiten Bhatt

Log in or sign up for Devpost to join the conversation.