National AI Deep Research Agents
Project Name: National AI Deep Research Agents (NAAF Research Agents)
Inspiration
The global AI race is accelerating, but there is no standardized, data-driven way to measure which countries are truly AI-capable versus which are simply consuming imported AI technology. Existing indices (like the Oxford AI Readiness Index) cover governance readiness but miss the physical supply chain — the power grids, semiconductor fabs, cloud infrastructure, and talent pipelines that determine whether a nation can actually build AI or just buy it.
We were inspired by the concept of "full-stack sovereignty" — the idea that true AI power isn't just about having good models, it's about controlling the entire value chain from electricity generation and chip fabrication all the way up to model development, talent, and adoption. We wanted to build a system of AI agents that could autonomously research, score, and rank any country across this full stack, producing a rigorous, source-cited intelligence report in minutes rather than the weeks or months it takes human analysts.
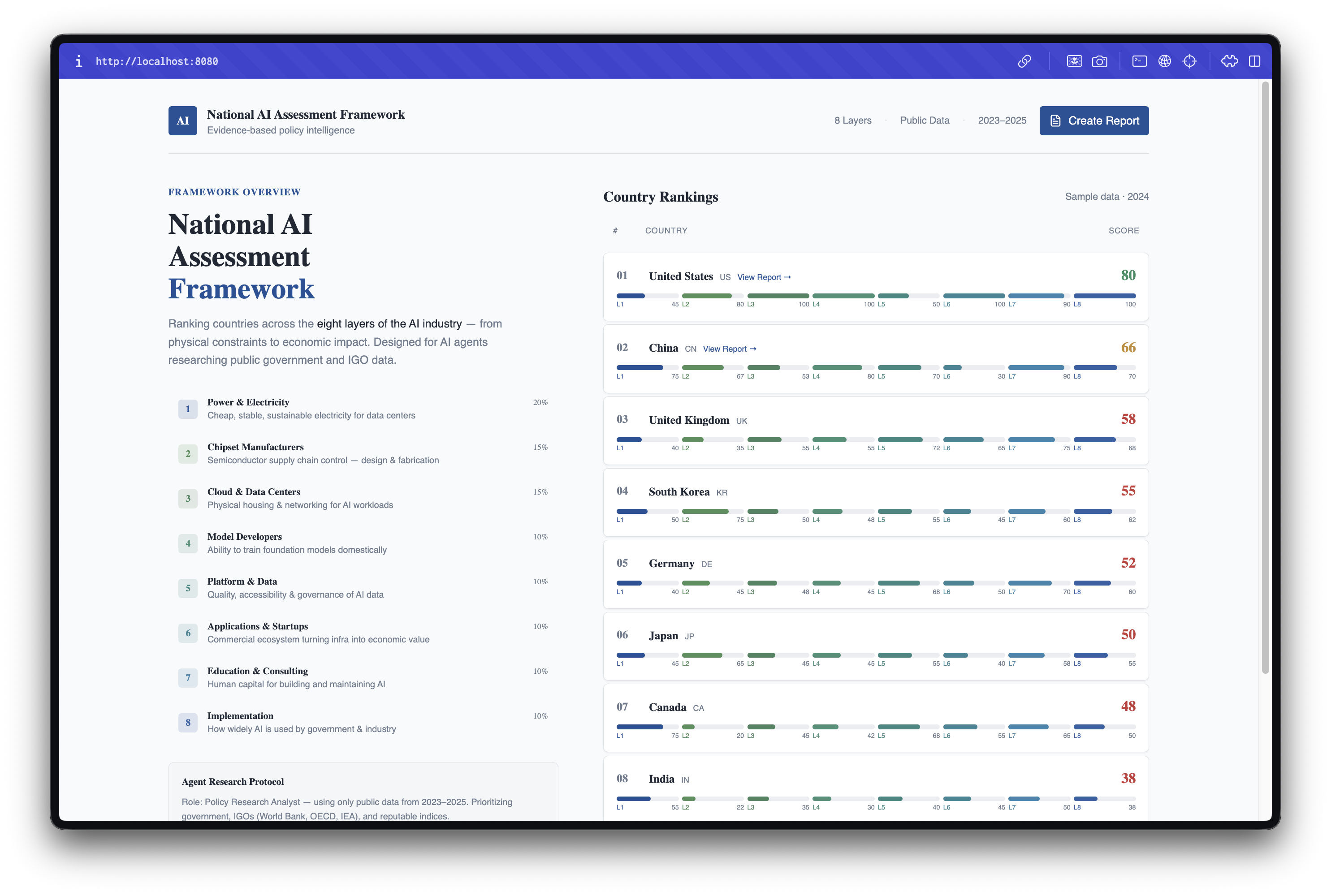
The NAAF (National AI Assessment Framework) breaks AI capability into 8 weighted layers — mirroring how the semiconductor and AI industries are actually structured — and asks: "If every import stopped tomorrow, how much AI could this country still produce?"
What it does
National AI Deep Research Agents is a multi-agent AI research system that produces comprehensive Country AI Power Reports. Given a country name, the system:
Deploys 8 specialized research agents — one for each layer of the AI stack: Power & Electricity (20%), Chipset Manufacturers (15%), Cloud & Data Centers (15%), Model Developers (10%), Platform & Data (10%), Applications & Startups (10%), Education & Talent (10%), and Government Adoption (10%).
Each agent autonomously searches the web using the You.com Search API, targeting authoritative sources (IEA, World Bank, OECD, EIA.gov, TOP500, WIPO, Stanford AI Index, etc.) to find real, current data (2023-2025) for its layer's metrics.
Scores each layer 0-100 relative to the global leader, with weighted contributions that roll up into an overall AI Power Score.
Classifies countries into Power Tiers:
- Hegemon (80-100): Full-stack sovereignty — controls atoms and bits
- Strategic Specialist (50-79): World-class in specific layers, dependent on others
- Adopter (30-49): Growing ecosystem, follows leaders
- Consumer (0-29): Relies entirely on imported AI technology
Persists structured JSON reports with per-layer scores, justifications, source citations, and an executive summary — ready for visualization in the companion web app.
Provides a React web dashboard where users can view country rankings, drill into individual layer assessments, and explore the research citations backing each score.
How we built it
Agent Framework: Google Agent Development Kit (ADK) with Gemini 3 Flash Preview as the LLM backbone. We chose ADK for its native support for multi-agent orchestration, sub-agent delegation, and session state management.
Architecture — Supervisor + 8 Layer Agents:
- A Supervisor Agent receives the country name and delegates research to 8 specialized Layer Agents (one per NAAF layer), then aggregates results into a final scored report.
- Each Layer Agent has a dynamically generated instruction prompt with layer-specific metrics, preferred authoritative domains, and a strict research protocol (2-3 targeted searches per metric, year constraints, source citation requirements).
- A Source Registry maps each layer to its preferred authoritative domains (e.g., Layer 1 Power targets
iea.org,eia.gov,irena.org; Layer 2 Chips targetssemi.org,chips.gov,tsmc.com).
Search & Research Tools:
- You.com Web Search API — primary research tool, with both open web search and domain-restricted search for authoritative sources.
- Source tracking — every search result URL is automatically tracked in session state and persisted to
sources.jsonfor full citation transparency.
Scoring Engine:
- Implements the Relative Power Index (RPI) formula with weighted layer contributions.
- Each layer score is persisted as individual JSON files to a timestamped report directory.
- Final report aggregation assembles all layer data, source URLs, tier classification, and executive summary into
final_report.json.
Persistence Layer:
- Timestamped report directories under
reports/{country}_{timestamp}/ - Individual layer JSONs, aggregated final report, and deduplicated source list
- Session state bridges the gap between independent agent runs
Frontend — React + Vite:
- React web app with Radix UI components, TanStack Query, and Tailwind CSS
- Country ranking dashboard, layer-by-layer drill-down, and source explorer
- Agent research view showing real-time progress of the multi-agent pipeline
Tech Stack:
- Python 3.11+ / Google ADK / Gemini 3 Flash Preview
- You.com Search API (hackathon sponsor tool)
- Pydantic for structured output schemas
- React / Vite / TypeScript / Tailwind CSS / Radix UI / TanStack Query
- httpx for async API calls
Challenges we ran into
Migrating from AWS Strands to Google ADK mid-hackathon. We initially built on the AWS Strands Agents SDK but decided to migrate to Google ADK for better multi-agent orchestration. This required rearchitecting our tool definitions, agent composition, and state management patterns — a significant pivot during a time-constrained event.
You.com API migration. The You.com Search API migrated from the legacy
api.ydc-index.ioendpoint toapi.you.com/v1with a different response schema (results.web[]vs the old flat format). We had to update our parsing logic and add startup key validation to catch bad keys immediately rather than mid-research.Agent coordination and state management. Getting 8 independent sub-agents to write their results into a shared session state that the supervisor could later aggregate was non-trivial. We built a persistence layer that both writes individual layer JSONs to disk in real-time and accumulates data in session state for the final report assembly.
Source quality and recency. AI agents can hallucinate sources. We mitigated this by restricting searches to authoritative domains per layer, requiring 2023-2025 data only, and tracking every URL the agent actually retrieved from You.com (not fabricated) in session state for full auditability.
Prompt engineering for consistent scoring. Getting agents to score consistently on a 0-100 scale relative to the global leader (not in absolute terms) required careful prompt design with explicit scoring rubrics, metric definitions, and calibration guidance per layer.
Accomplishments that we're proud of
A working multi-agent research pipeline that can take any country name and autonomously produce a comprehensive, source-cited AI capability assessment across 8 layers — in minutes rather than weeks.
Real research, real citations. Every data point in our reports traces back to an actual URL from an authoritative source (IEA, EIA, World Bank, TOP500, WIPO, Stanford AI Index). The system produces a
sources.jsonwith full metadata for every search result it consumed.The 8-layer framework itself. The NAAF framework is a novel contribution — no existing index captures the full AI supply chain from electricity to adoption with weighted scoring and tier classification. Layer weights reflect real supply chain dependencies (power and chips matter more than apps).
Clean agent architecture. The supervisor-delegate pattern with dynamic prompt generation, a source registry, and structured persistence is reusable beyond this specific use case. Any domain that requires multi-dimensional research and scoring could adopt this architecture.
Structured, machine-readable output. Reports are persisted as structured JSON (not just markdown), making them immediately consumable by dashboards, APIs, and downstream analysis — not locked in a chat transcript.
What we learned
Google ADK's multi-agent orchestration is powerful but young. Sub-agent delegation, session state sharing, and tool context injection work well once you understand the patterns, but documentation is still catching up. We had to read source code and experiment extensively.
Domain-restricted search dramatically improves research quality. Letting agents search the open web produces noisy, unreliable results. Restricting to curated authoritative domains per layer (our Source Registry pattern) was the single biggest improvement to output quality.
Prompt engineering is architecture, not afterthought. The quality difference between a generic "research this layer" prompt and a prompt with specific metrics, scoring rubrics, preferred sources, and research protocols is enormous. Our layer-specific prompt templates are effectively the "business logic" of the system.
Persistence design matters for agent systems. Agents are stateless by default. Building a persistence layer that writes incrementally (per-layer JSONs during research) while also accumulating in session state (for final aggregation) made the system robust to failures and auditable.
You.com's Search API is a strong foundation for research agents. The ability to do domain-restricted searches with snippet extraction gives agents access to targeted, high-quality web data — a critical capability for building research systems that need to cite real sources.
What's next for National AI Deep Research Agents
Complete all 8 layers end-to-end — Our current demo covers the first 4 layers (Power, Chips, Cloud, Models) with production-quality research. Layers 5-8 (Data, Apps, Talent, Adoption) have prompts and scoring defined but need full end-to-end testing with real country assessments.
Multi-country comparison mode — Run assessments for multiple countries in parallel and produce comparative dashboards showing relative strengths across the AI stack.
Historical tracking — Store timestamped assessments to track how countries' AI capabilities change over time, enabling trend analysis and early warning on capability shifts.
Enhanced web dashboard — Build out the React frontend with interactive layer drill-downs, radar charts for country profiles, and a global map visualization of AI power tiers.
Additional data sources — Integrate Exa Search for academic paper analysis, add live news monitoring for real-time capability changes, and incorporate structured databases (World Bank API, OECD iLibrary) for direct metric extraction.
Cloud deployment on GCP — Deploy the agent pipeline on Cloud Run with Secret Manager for API keys, enabling on-demand country assessments via a public API.
Policy recommendation engine — Add a final synthesis agent that takes the 8-layer assessment and generates actionable policy recommendations for governments seeking to improve their AI sovereignty position.
Built With
- agent-development-kit
- lovable
- python
- you.com

Log in or sign up for Devpost to join the conversation.