-
-
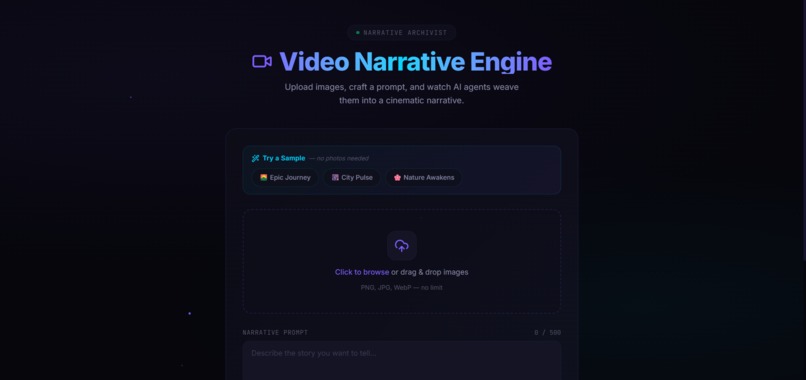
empty try it out page
-
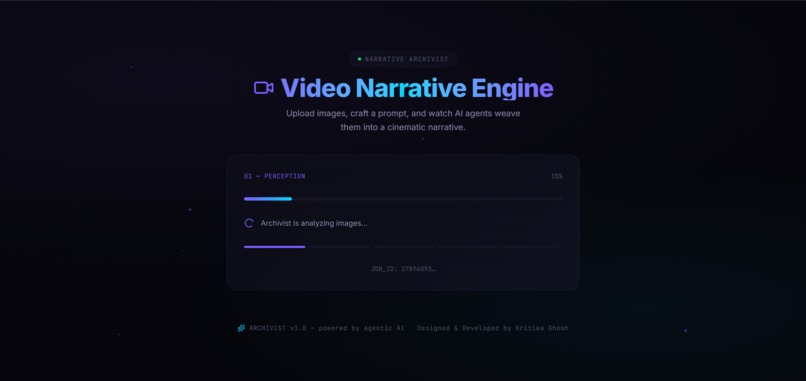
processing screen
-
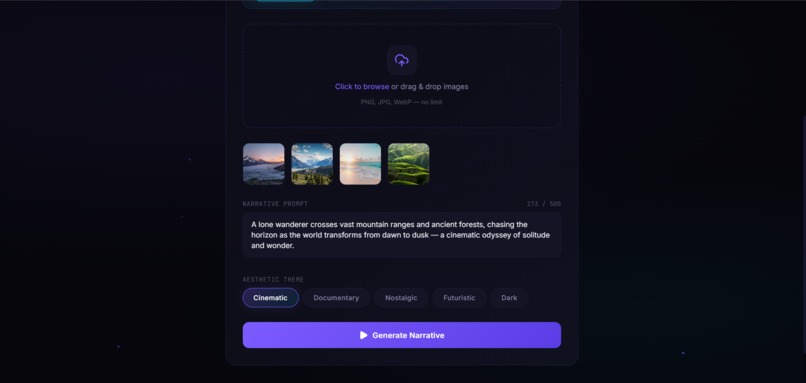
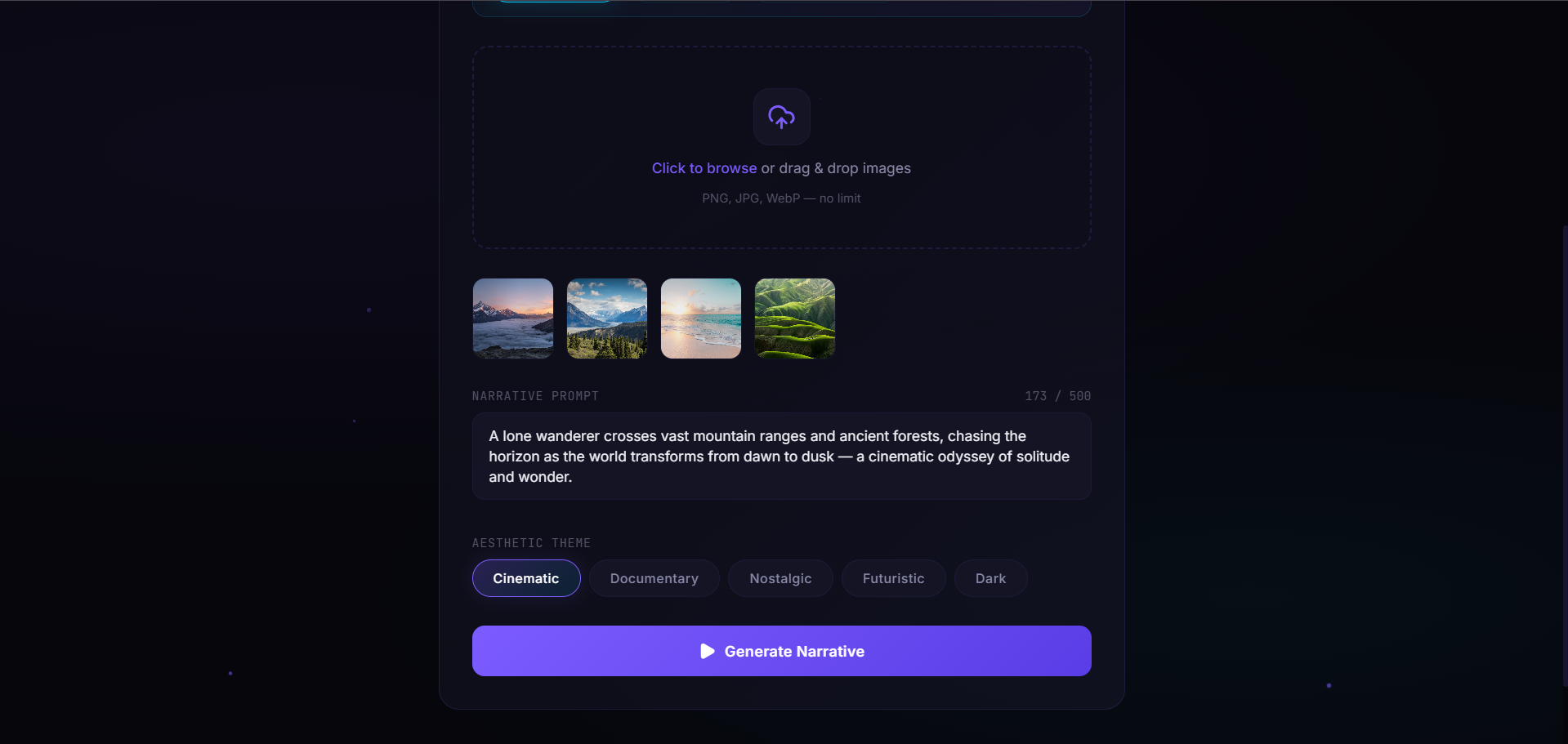
populated page
-

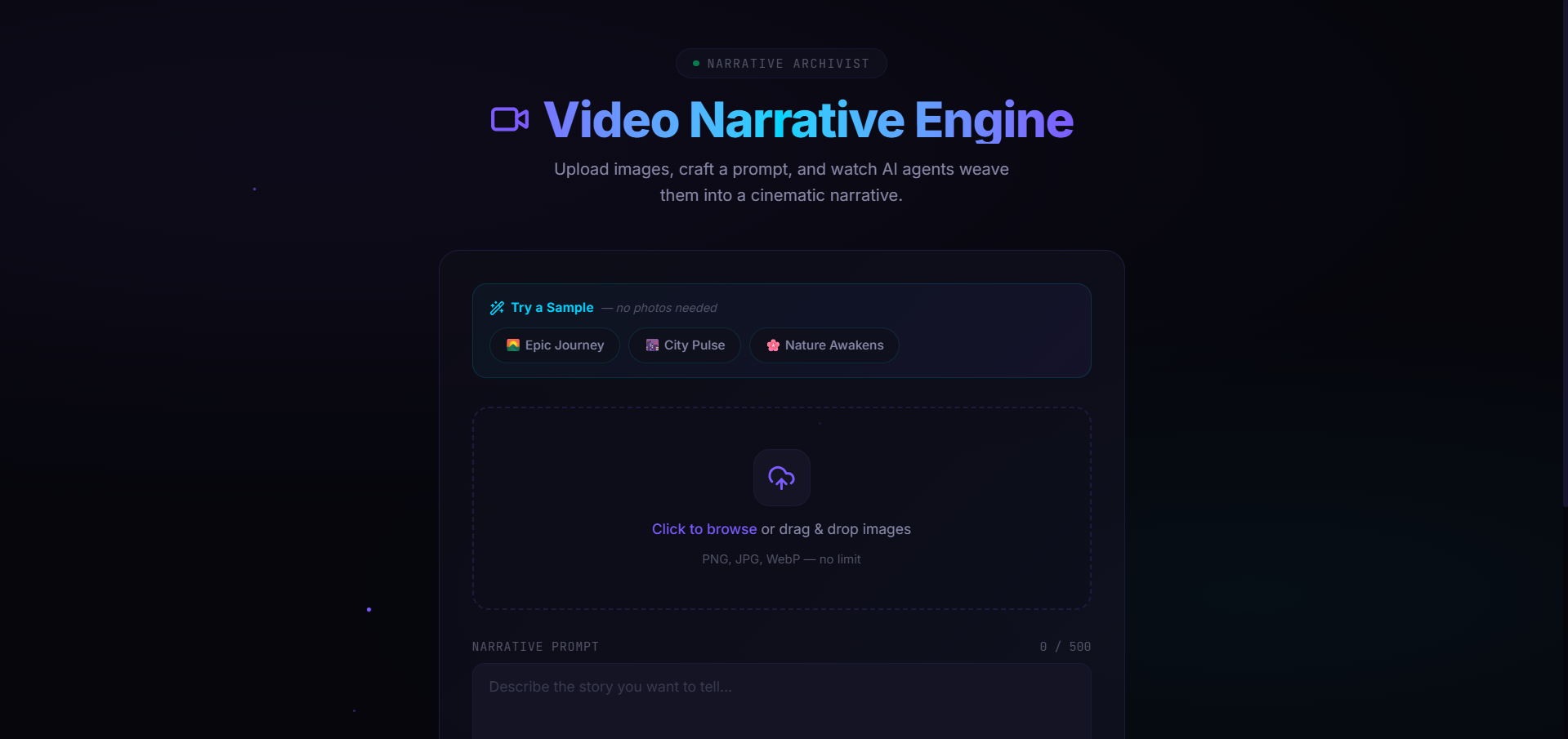
landing page
-
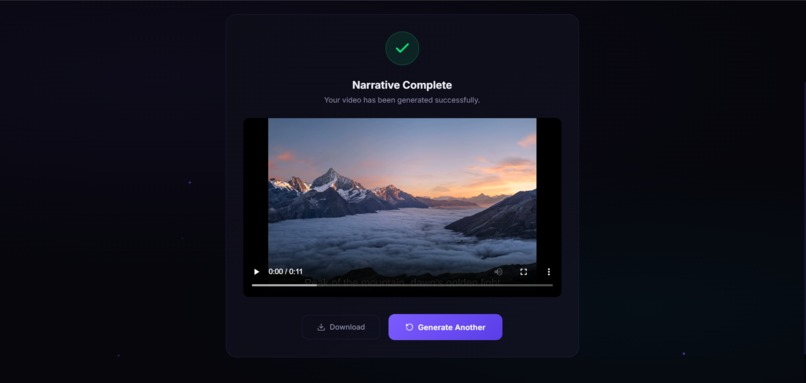
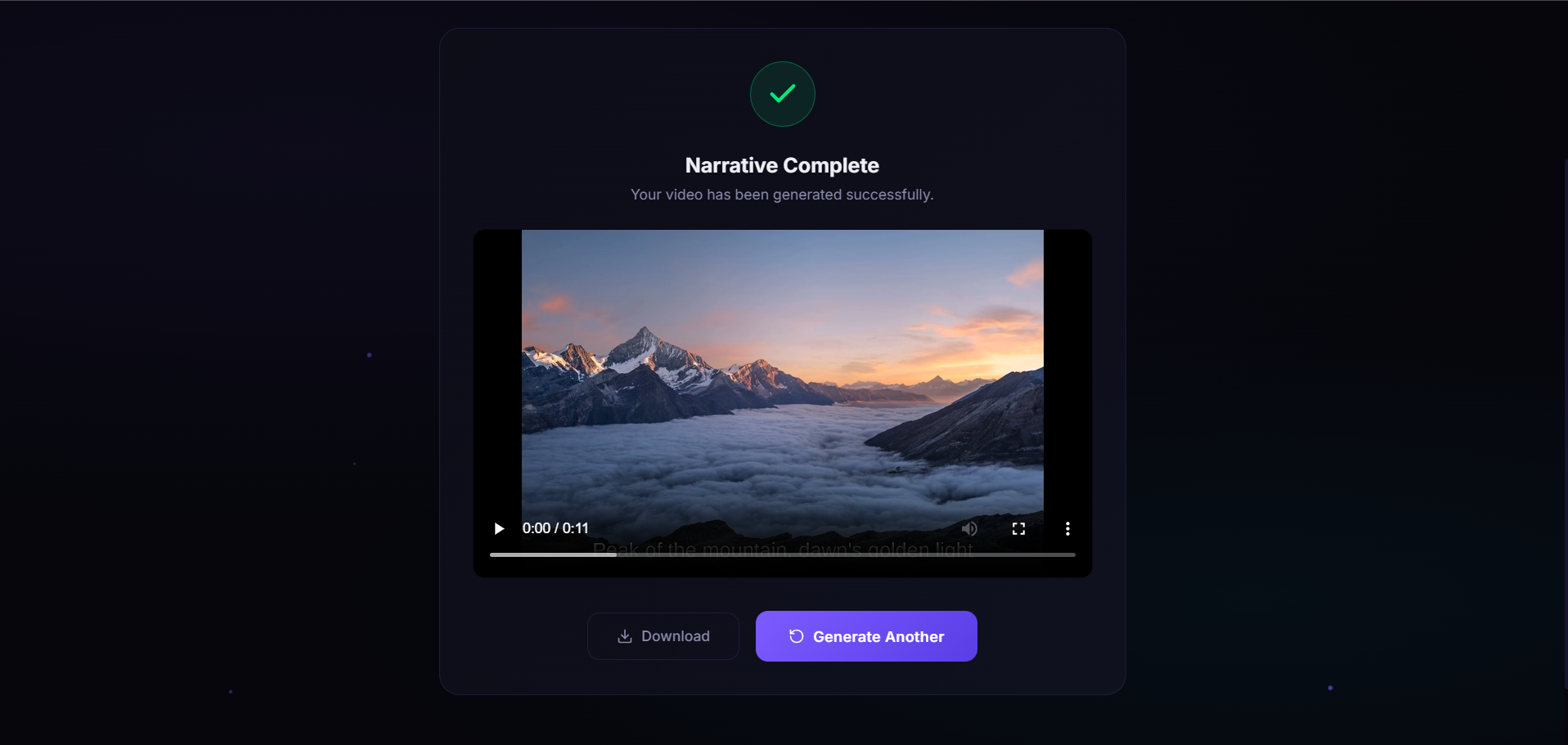
completion of generation screen


Here is the complete, cohesive write-up for your final hackathon submission form. It balances technical depth with a compelling project narrative, structured perfectly to match your submission headings.
💡 Inspiration
Traditional video editing software treats creators like assembly line workers—forcing them to manually splice timelines, time audio cuts, and align text tracks frame-by-frame. Even when looking at modern AI "image-to-video" tools, we found a glaring flaw: they treat image sequences as random, disconnected loops or simple linear slideshows. They possess zero visual empathy and no understanding of narrative flow, thematic continuity, or emotional pacing.
We were inspired to build a system that acts less like a rigid render compiler and more like an autonomous film crew—a platform that looks at a collection of images, perceives their underlying story, maps the most logical cinematic path between them, and scores an engaging screenplay completely on its own.
🎬 What it does
Narrative Video Agent is an autonomous full-stack AI production platform that transforms arbitrary batches of static imagery into coherent, captioned, 1080p cinematic video stories.
Through an ultra-modern glassmorphic studio dashboard, a creator simply drops a handful of photos and provides a high-level narrative prompt. The system instantly kicks off an asynchronous multi-agent orchestration pipeline. It analyzes the visual assets for deep semantic attributes, algorithmically recalculates their layout order to ensure the smoothest color and mood transitions, crafts a highly contextualized script overlay, and compiles a beautifully timed, fully rendered MP4 video ready for distribution.
🛠️ How we built it
We engineered the platform using a decoupled, high-performance full-stack architecture:
- The Frontend Interface: Built using React 19, Vite, and Tailwind CSS. It features a zero-copy drag-and-drop canvas that leverages memory-efficient browser object URLs (
URL.createObjectURL) to manage high-res preview assets without bogging down the main thread. A state-driven layout polls our backend tracking endpoint every 3 seconds to feed live progress metrics to the user. - The API & Core Worker Layer: Powered by FastAPI, handling multi-part form ingestion data and dispatching long-running generation pipelines asynchronously.
- The Agent Core: Managed by CrewAI, splitting the cognitive workload between two distinct identities locked into strict Pydantic data schemas:
- The Lead Visual Archivist: Uses Gemini 1.5 Flash to extract granular visual metadata matrices (mood metrics, primary subjects, dominant lighting vectors).
The Narrative Director: Operates via Groq on Llama-3.1-8b for ultra-low latency inference, compiling the visual tokens into a structured screenwriting layout.
The Secret Sauce Continuity Engine: A custom-built Python
GraphServicethat treats images as nodes in a network. It calculates cross-cutting "thematic and color friction weights" between nodes, resolving an optimal mathematical path to organize the final video timeline seamlessly.The Film Studio: An underlying MoviePy (v2.0) engine that programmatically normalizes pixel schemas, handles dynamic subtitle bounding box transformations, and builds clean FFmpeg filter complexes to stitch frames together without timebase drift.
🚧 Challenges we ran into
- The "Chatty Agent" Dilemma: Early versions failed because LLMs frequently returned conversational fluff or broken markdown blocks instead of raw script text. This consistently corrupted our MoviePy compiler. We solved this by implementing rigid Pydantic validation boundaries at the task edge, forcing the LLMs to act as deterministic data engines.
- The Asynchronous Rendering Wall: Video compilation is heavily CPU/GPU bound. Running it synchronously in a standard serverless layout causes immediate browser timeouts. We completely re-architected the backend into an asynchronous polling machine, assigning unique Job IDs upon payload ingestion so the client can monitor pipeline health states smoothly.
- System Font Mapping & Formatting: Managing text wrapping over highly contrasting images caused significant clipping. We built a custom geometric layout calculator in our rendering service that dynamically steps down text sizes based on caption length and strictly enforces even-integer scales for strict H.264 video codec alignment.
🏆 Accomplishments that we're proud of
- Production-Grade Inference Latency: By deploying a hybrid multi-model framework—offloading heavy vision analysis to Gemini and rapid text-pacing workflows to Groq—we reduced end-to-end generation wait times significantly.
- Flawless Full-Stack Integration: Creating a highly reactive, beautifully polished glassmorphic interface that communicates reliably across separate cloud hosting boundaries.
- A Working System: Building an end-to-end production tool that actually writes, paths, transitions, and delivers high-fidelity media autonomously within a single click cycle.
🧠 What we learned
- Specialized Agents Triumph Over Generalists: Trying to force a single prompt layer to perform vision analysis, sorting, and scriptwriting results in immediate thematic degradation. Segmenting tasks into a strict hierarchy of hyper-focused worker personas drastically improves output fidelity.
- The Indispensability of Deterministic Boundaries: AI agents are highly creative, but system components are inherently rigid. Building ironclad schema validation guards between non-deterministic AI models and deterministic rendering engines is crucial when constructing resilient AI applications.
🚀 What's next for narrative-video-agent
- Audio Layer Synthesis: Integrating text-to-speech models (like ElevenLabs) and AI music beds to automatically generate localized high-fidelity voiceovers and adaptive scores directly matched to the visual script timestamps.
- Horizontal Scaling with Distributed Queues: Migrating our in-memory job tracker to an enterprise-grade distributed queue mesh using Upstash Redis and Celery to safely manage thousands of concurrent multi-user render threads.
- Algorithmic Expansion: Upgrading our
GraphServiceto utilize vector database embeddings, allowing the pathfinder to calculate massive narrative sequence paths across hundreds of uploaded assets seamlessly.

Log in or sign up for Devpost to join the conversation.