-
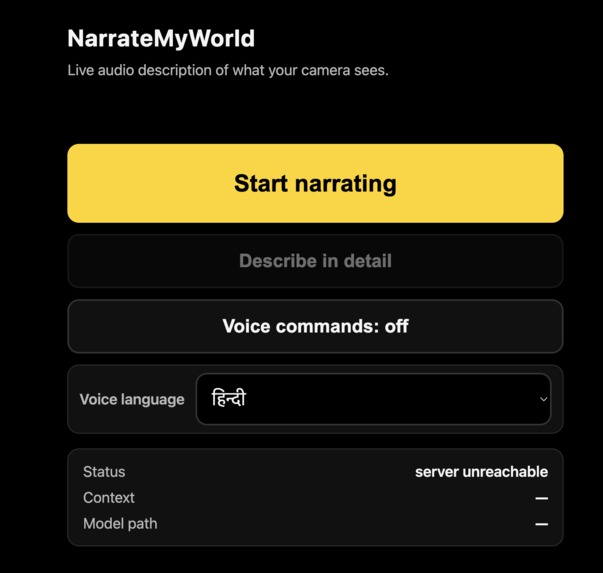
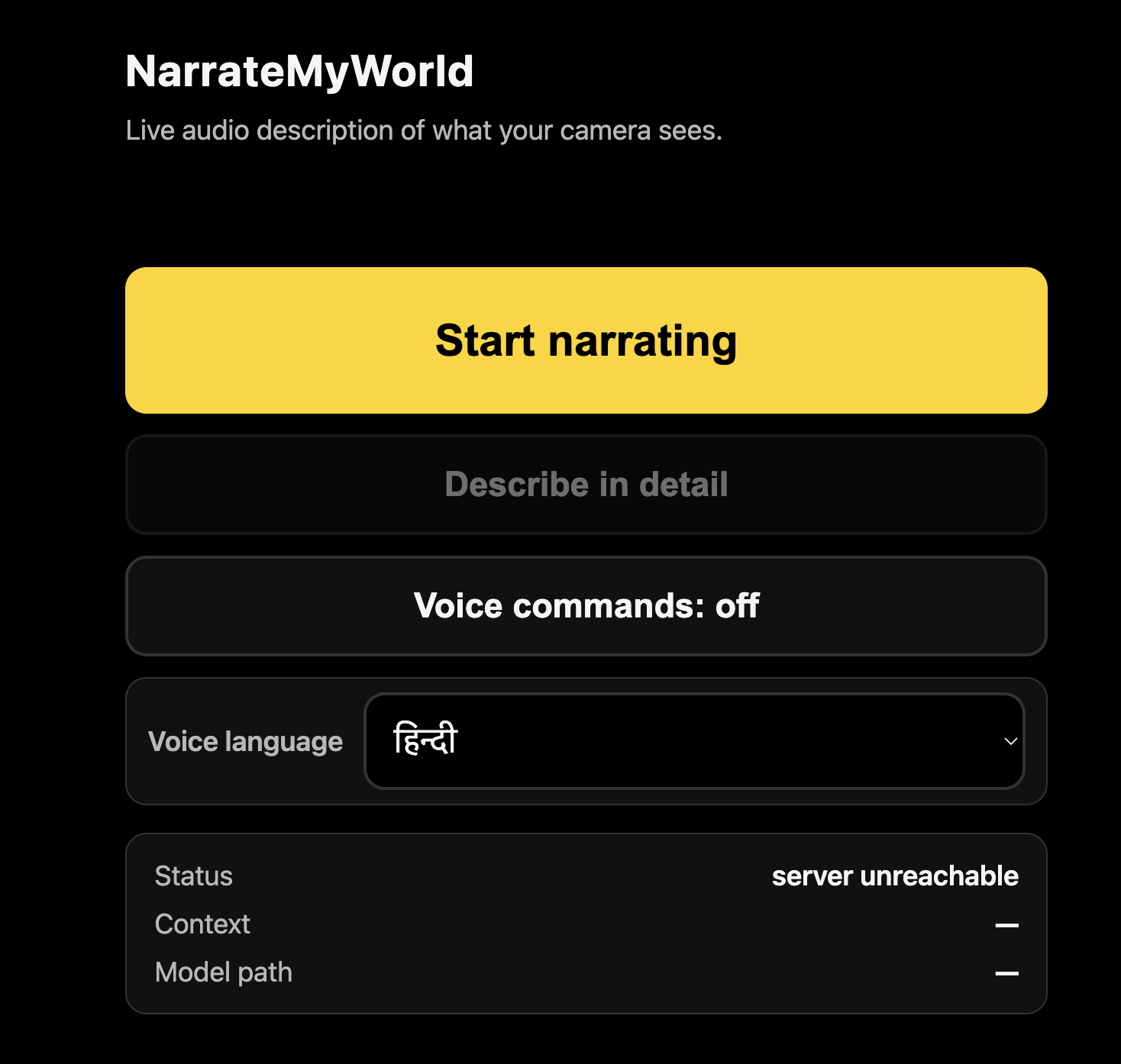
web app interface
Inspiration
My aunt is visually impaired. I watched her struggle with basic things — crossing a street, finding a door, reading a menu. The tools that exist are either expensive hardware or clunky apps that take too long to be useful in real time. I thought: everyone already has a phone with a camera. What if I could just make it talk — instantly, naturally, like a friend walking beside you describing the world?
What it does
NarrateMyWorld is a web app that turns any smartphone camera into a real-time AI narrator. You open the website, tap one button, and point your phone. Every 1.5 seconds, it captures a frame, understands the scene, and speaks a natural description out loud — with spatial awareness like "Fire hydrant right in front of you. Parked car five feet ahead. Crosswalk across the street."
If it detects a hazard — a car approaching, stairs, an obstacle — it interrupts itself mid-sentence to warn you immediately, with a haptic vibration pulse. It works in 5 languages (English, Spanish, French, Chinese, Hindi) and requires zero installation. Just a URL.
How I built it
Gemini Flash for real-time vision — it classifies the scene (transit, medical, retail, outdoor) and generates spatial descriptions with Near/Mid/Far distance tags ElevenLabs for natural-sounding streaming TTS — audio starts playing in ~300ms, not after the full response Featherless.ai as a specialized re-route — when Gemini detects transit or retail with high confidence, it enriches the description through a domain-specific model Firebase Cloud Functions as the serverless backend — all API keys stay server-side, no secrets on the client Vanilla JS PWA — no React, no framework. A progressive web app that works offline and loads instantly Server-side hazard keyword scanning so danger alerts don't require an extra API call Challenges I ran into Gemini returning broken JSON. Even with responseMimeType: 'application/json', Gemini Flash would randomly wrap its output in markdown fences or prepend filler text like "Here is the JSON requested:". I had to build a 3-layer extraction pipeline: direct parse → bracket extraction → truncated JSON rescue.
Voice identity shifting across languages. When I sent a language_code to ElevenLabs' turbo model, the voice character completely changed — it sounded like a different person. I solved this by switching to eleven_multilingual_v2 for non-English languages, which preserves the speaker's identity across languages.
Latency budget. The entire pipeline — capture frame, upload, Gemini inference, TTS streaming, audio playback — has to complete fast enough that descriptions feel real-time, not stale. I got it down to ~2.6s end-to-end with streaming audio starting at 300ms TTFB.
Mobile browser quirks. Service workers caching stale JS, MediaSource not supported on iOS Safari (had to build a Blob fallback), and URL.createObjectURL memory leaks during continuous playback sessions.
Accomplishments that I'm proud of
It actually works in real time. Not a demo, not a mockup — you can point your phone at a street and hear useful, spatial descriptions continuously. Hazard interruption. The system will cut off its own speech mid-word to warn you about danger. That felt like a breakthrough moment. Zero install. No app store, no download. Just open a URL and tap one button. That's the accessibility bar I wanted to hit. Built the entire thing solo — frontend, backend, AI pipeline, deployment, and debugging — in a hackathon timeframe.
What I learned
Gemini's JSON mode isn't as strict as you'd expect — you need defensive parsing in production Streaming audio is dramatically better than buffered playback for perceived latency (300ms vs 3s to first sound) Exponential backoff and adaptive intervals aren't just "nice to have" — they're essential when you're hitting an AI API every 1.5 seconds Accessibility-first design forces you to think about edge cases (offline, permission denied, screen off) that make the app better for everyone
What's next for NarrateMyWorld
Personalized scene memory — "You've been here before. Last time, the pharmacy was on your right." Using location + scene embeddings to build a personal spatial map AR audio cues — spatial audio that lets you hear where objects are (left ear vs right ear) instead of just being told Adaptive frame rates — slow down when the scene is static, speed up when you're moving or the environment is changing Offline mode — a lightweight on-device model for basic obstacle detection when there's no network Community hazard reporting — crowdsourced danger zones that warn users before they even encounter them
Built With
- abortcontroller
- css3
- elevenlabs-(streaming-text-to-speech)
- featherless.ai-(specialized-scene-enrichment)-other:-getusermedia-(camera)
- firebase-cloud-functions-(2nd-gen)-cloud-services:-firebase-hosting
- firebase-secret-manager
- google-cloud-run-apis:-google-gemini-flash-(vision-+-classification)
- html5
- languages:-javascript-(es-modules)-frontend:-vanilla-js
- mediasource-api
- progressive-web-app-(pwa)
- service-workers-backend:-node.js
- vibration-api
- wake-lock-api
- web-speech-api



Log in or sign up for Devpost to join the conversation.