-

Logo
-

-

transcript clustering


Inspiration
Cancer panels to detect what type of cancer a person has currently require several steps in order to sequence just the relevant genes. Extracted DNA and RNA has to be amplified to increase the abundance of transcripts that need sequencing before going in the sequencing machine. Removing this steps would save time and work.
In addition, in RNA-seq studies, there is a lot of RNA within the sample that is not interesting as it is not mRNA. Being able to filter out reads which are not mRNA would reduce sequencing time and make data clearer.
Nanopore sequencing produces live data of what is being sequenced and the sequencing pore can be reversed to 'spit out' nucleic acids sequencing that are unfavourable by reversing the polarity of the pore. If an algorithm can be produced that matches live sequencing data with the sequence, unwanted transcripts can be rejected during sequencing and targeted sequencing can be achieved.
Nanopore is the ideal sequencing platform for cancer panel sequencing because it produces long reads which can detect fusion proteins, and large insertions and deletions and does it fast.
What it does
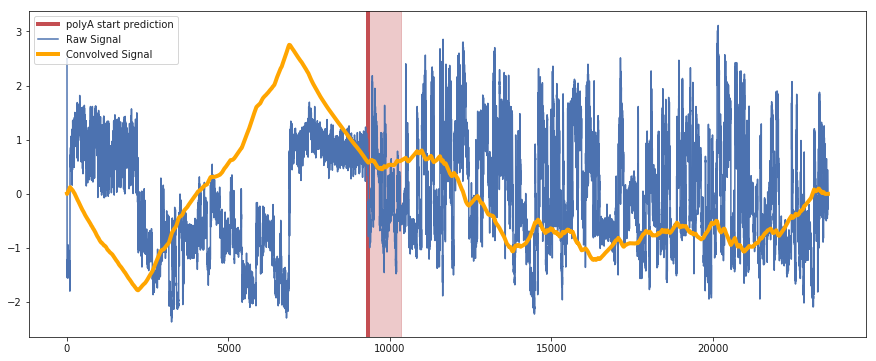
The algorithm uses signal processing methods for step detection to find the end of the poly-a tails signifying that it is messenger RNA with 90% accuracy.
Once the end of the poly-a tails has been found, signifying it is a mRNA, the algorithm does Dynamic Time Warping to measure the similarity and decide if the transcript is of interest
How We built it
The algorithm is built in python and has several steps.
First, transcripts undergo standard scaling to prep them for analysis
Then the program uses sci-py signal to identify the poly-a tails using step detection to decide if they are worth sequencing
Finally, the sequence undergoes dynamic time warping using a package called LibRosa. Librosa is designed for use in music analysis but it works in this instance to look at the similarities between signal sequences.
Challenges We ran into
Getting data! It was very hard to match transcript sequences with their signal because of the way available datasets are structured. This took significantly longer than planned
Once we had the data we originally planned to build the algorithm in R however unfamiliarity with the language meant we switched to python and used packages not traditionally used for what we are doing.
Accomplishments that We're proud of
Getting the data
Being able to predict Poly-A tails with pretty good accuracy
Quickly learning new about time series and the associated algorithms for analysis
What We learned
We learned about time series analysis and Dynamic Time Warping
We learned about nanopore signal structures
What's next for NanoPanel
Improve algorithm so it's more accurate in finding the difference between signals.
Testing it on live nanopore data
attaching algorithm to nanopore MinIon




Log in or sign up for Devpost to join the conversation.