-
-
screenshot of sample output
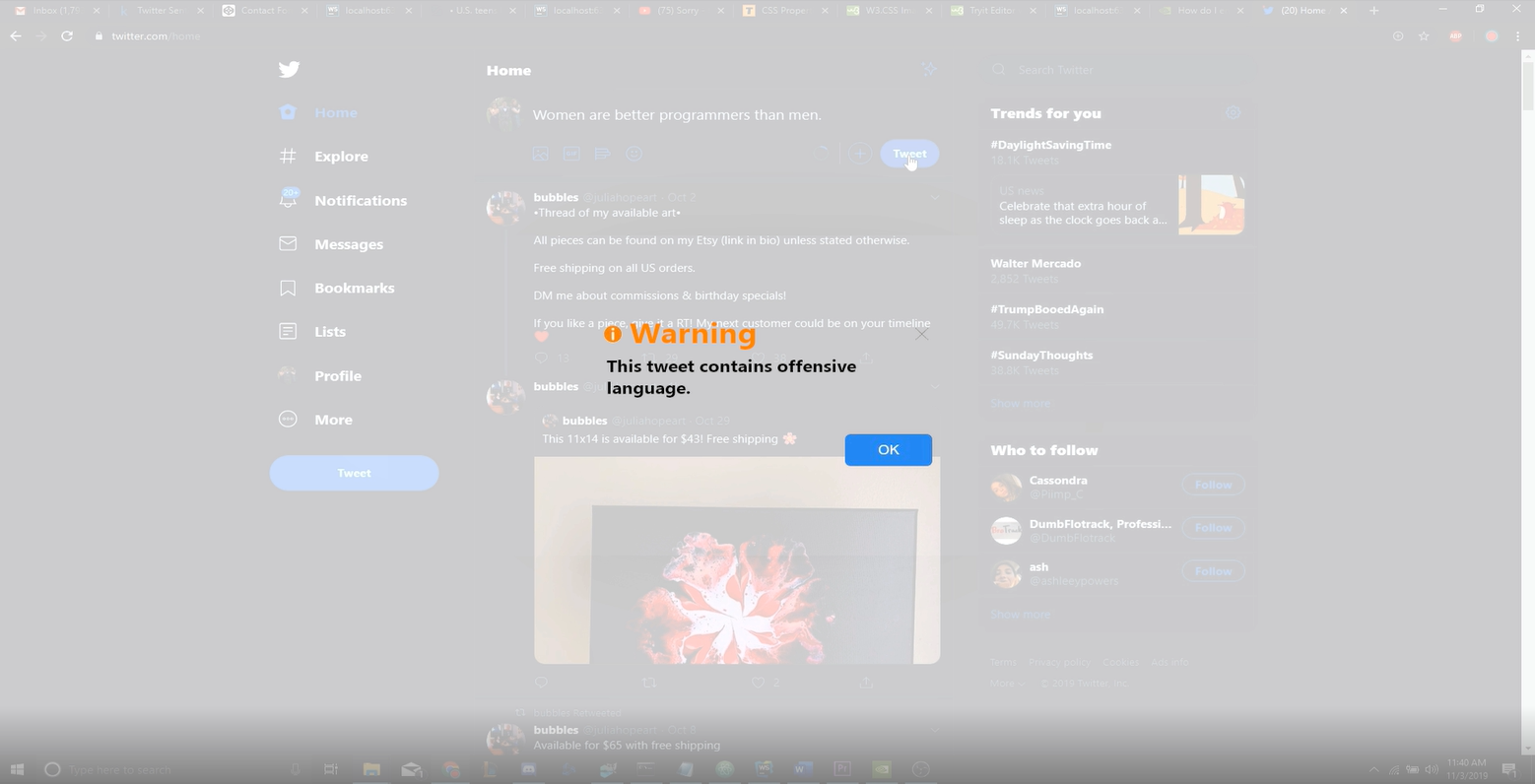
For this project, we trained a neural network using 4,000 unique tweets in order to categorize whether or not a given sentence is potentially offensive. Our network learned from analyzing the context of each word using Google's word2vec corpus rather than simply memorizing the sequence of each word. This means that our algorithm can accurately analyze the meaning of each word in the sentence given that it has adequate training data.
A copy of our neural network is attached to this file for easy import with the Keras and Pytorch frameworks. This network had an ending accuracy on our testing data of 95% with a loss value of 0.16. We have included a text box at the bottom of the Twitter_NN.ipynb file to test our algorithm on any phrases or sentences below 100 words that you may want to try out!
The only file missing from this repository is the word2vec pre-trained Google News corpus (3 billion running words) word vector model due to the size of the file(3.6GB). That file can be obtained at Google's official website or here:

Log in or sign up for Devpost to join the conversation.