
Inspiration
I grew up hearing Ghomala' (Ghɔ́málá') — the language of the Bamiléké people from West Cameroon — spoken by my parents and grandparents. Today, I speak only about 30% of my mother tongue. My generation is losing it. Young Cameroonians grow up speaking French or English and never learn their ancestral language. Ghomala' has:
Zero presence on Duolingo, Google Translate, or any language platform No digital corpus — the largest resource is a scanned dictionary from the 1970s No voice assistant that understands or speaks it ~1 million speakers, most of them aging
UNESCO classifies Ghomala' as a vulnerable language. If we do nothing, it dies with our elders. NAM SA' is my answer: use AI to make sure the sun rises on our language, not sets.
What it does
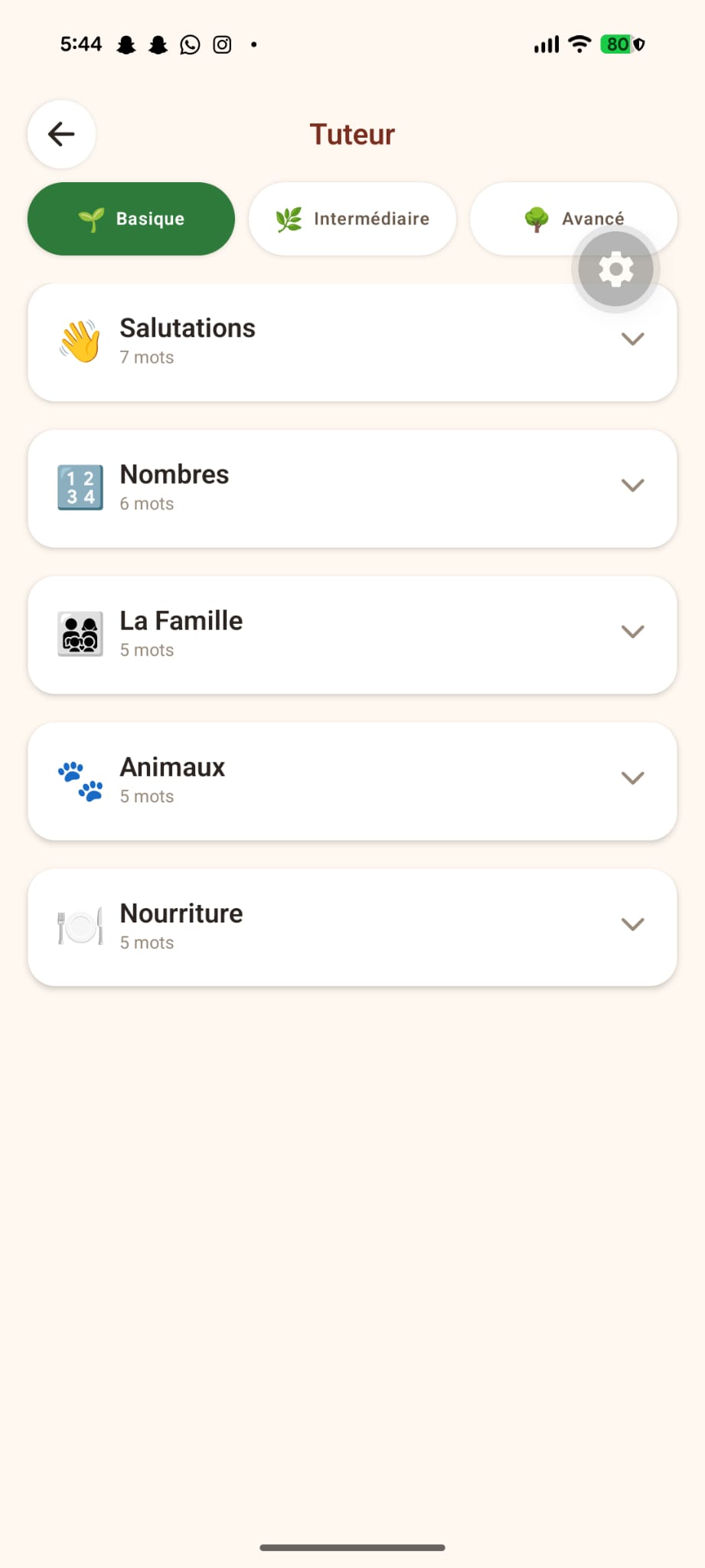
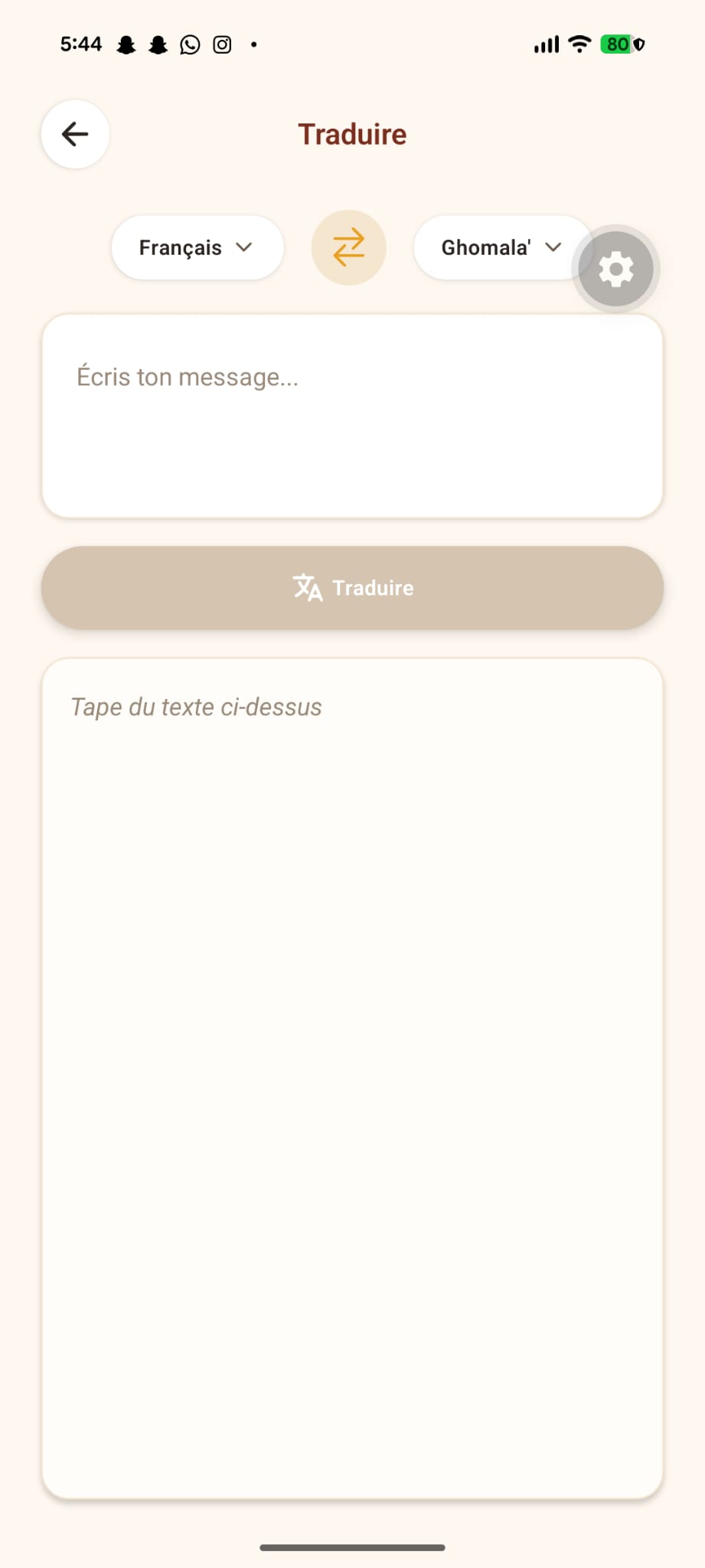
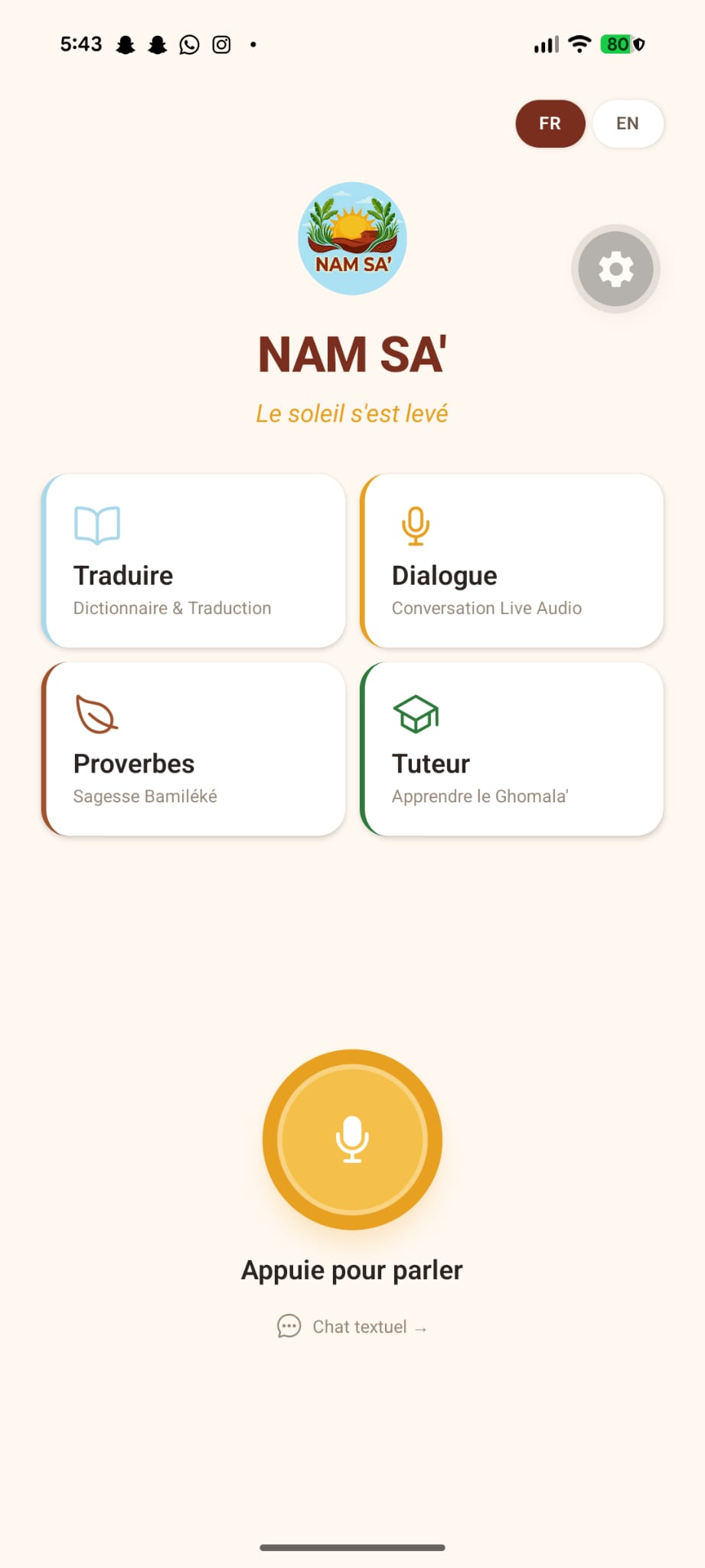
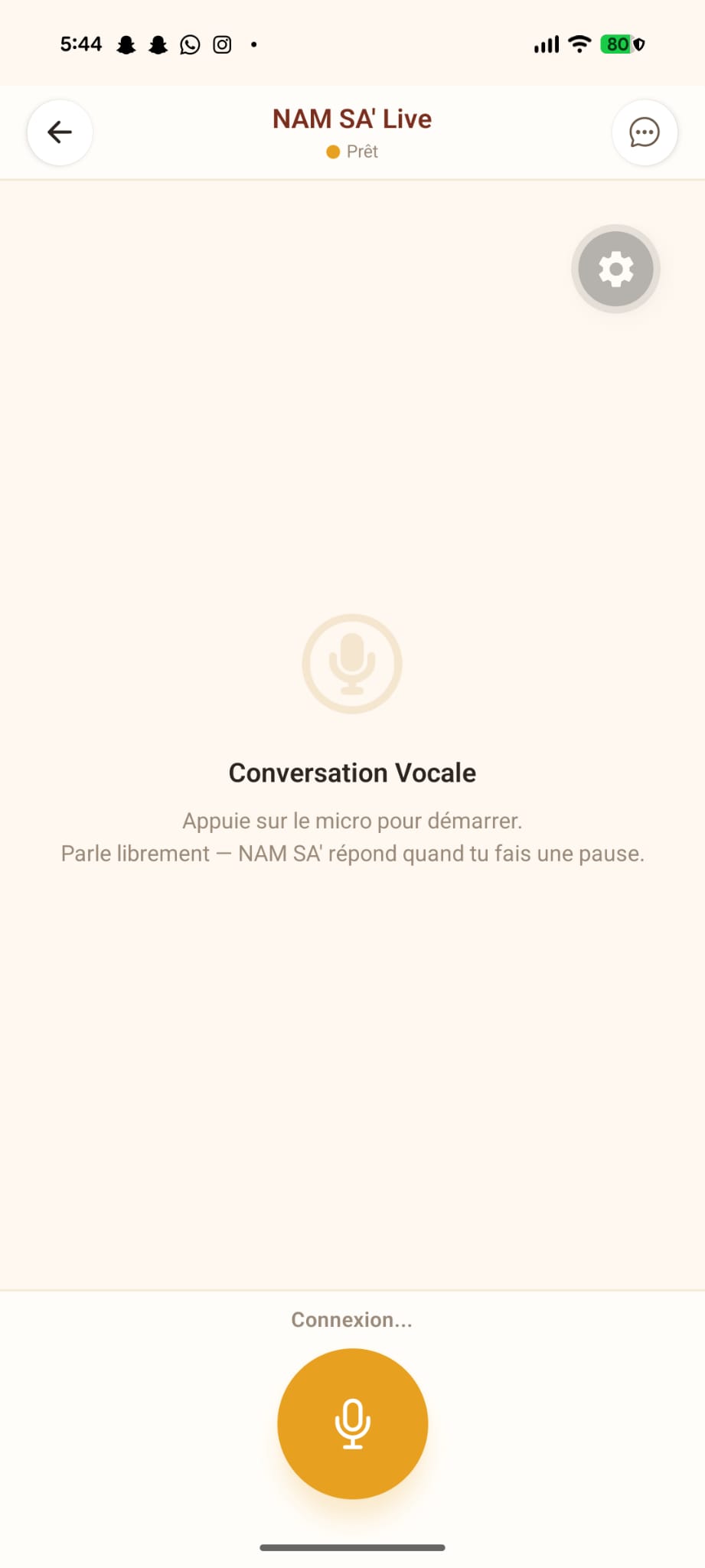
NAM SA' is a mobile app that teaches Ghomala' through voice-first interaction: Real-time voice conversations — Speak naturally and get spoken responses via Nova 2 Sonic bidirectional streaming. No buttons, no typing — just talk. AI Language Tutor — Text chat with a fine-tuned Nova 2 Lite model that actually knows Ghomala'. It translates, explains grammar, shares cultural context, and corrects mistakes gently. Dictionary & Translation — Google Translate-style interface between French, English, and Ghomala' — a tool that didn't exist before. Bamiléké Proverbs — 20+ traditional proverbs with meanings, translations, and audio playback. The wisdom of our ancestors, preserved digitally. Vocabulary Tutor — Structured learning: 3 levels, 15 topics, 75+ words with on-demand translation and text-to-speech. Text-to-Speech — Every response can be read aloud via Amazon Polly — the closest phonetic match to Ghomala' pronunciation.
How we built it
Data Pipeline (the hardest part): Ghomala' is a true low-resource language — almost no digital data exists. I built a 6-step pipeline:
Extracted 4,929 dictionary entries from a scanned 1970s PDF using Gemini Vision API (page-by-page OCR) Downloaded open-source Masakhane datasets from HuggingFace (MAFAND-MT, AfriQA, XLSUM) Found community-contributed Ghomala' datasets: stephanedonna/english_ghomala (6.3K pairs) and stfotso/french-ghomala-bandjoun (15.2K pairs) Converted everything to Bedrock conversation JSONL format Curated a balanced 2,000-sample training set (cultural content + dictionary + French pairs + English pairs) Launched SFT on Amazon Bedrock → 5.5 hours training → deployed as on-demand custom model Backend: FastAPI on AWS Fargate (ECS) with:
/ws/sonic — Nova 2 Sonic bidirectional speech-to-speech (Smithy SDK, PCM 16kHz→24kHz) /ws/live — Record-then-send pipeline (Transcribe → fine-tuned Nova Lite → Polly) /api/chat, /api/translate, /api/tts — REST endpoints
Mobile: React Native + Expo SDK 55 with 6 screens, bilingual FR/EN interface, custom TTS service, silence detection for voice recording, and a design system drawn from the NAM SA' logo colors (Maroon, Sun Gold, Forest Green, Cream).
Challenges we ran into
Ghomala' has almost no digital data. The largest source was a physical dictionary. I had to use a vision AI model to extract entries page-by-page, then manually curate them. Bedrock SFT constraints: Nova 2 Lite on Bedrock has batch size capped at 1. My first attempt with 18K samples projected 48 days of training. I solved it by curating 2,000 balanced samples → 5.5 hours. Nova 2 Sonic SDK is brand new. It uses a Smithy-based Python SDK separate from boto3, with a specific event protocol (sessionStart → promptStart → contentStart → audioInput → contentEnd) that must be followed exactly. No TTS for Ghomala'. I use Amazon Polly's French neural voice (Lea) as a phonetic approximation — imperfect but functional for learners.
Accomplishments that we're proud of
-Built the first AI voice assistant that understands Ghomala' -Fine-tuned the first Amazon Nova model on a Cameroonian language -Created a 4,929-entry digital dictionary from a scanned 1970s PDF -The app works — real users can actually learn Ghomala' words, hear pronunciation, and have voice conversations
What we learned
-How to fine-tune Nova 2 Lite on Bedrock with SFT and deploy with on-demand inference -The Smithy SDK for Nova 2 Sonic bidirectional streaming -Building data pipelines for extremely low-resource languages -That AI can be a powerful tool for cultural preservation, not just productivity
What's next for NAM SA' — AI Voice Agent for Ghomala' Language Preservation
Community data collection — Record audio sessions with native speakers (my parents) to build a speech corpus Proper dictionary digitization — Use SIL Keyman Unicode keyboard with native speaker verification Open-source the fine-tuned model on HuggingFace under Daemon Craft Expand to other Cameroonian languages — Medumba, Fe'fe', Yemba (all Bamiléké family) Camera vision mode — Point at objects and learn the Ghomala' word (MVP2 with Nova vision)
Built With
- amazon-bedrock
- amazon-ecs-fargate
- amazon-nova-2-lite
- amazon-nova-2-sonic
- amazon-polly
- amazon-transcribe
- amazon-web-services
- expo.io
- fastapi
- python
- react-native

Log in or sign up for Devpost to join the conversation.