-

-
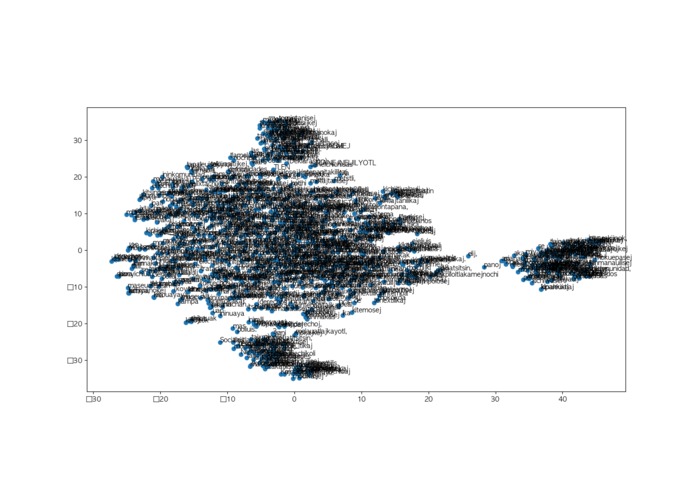
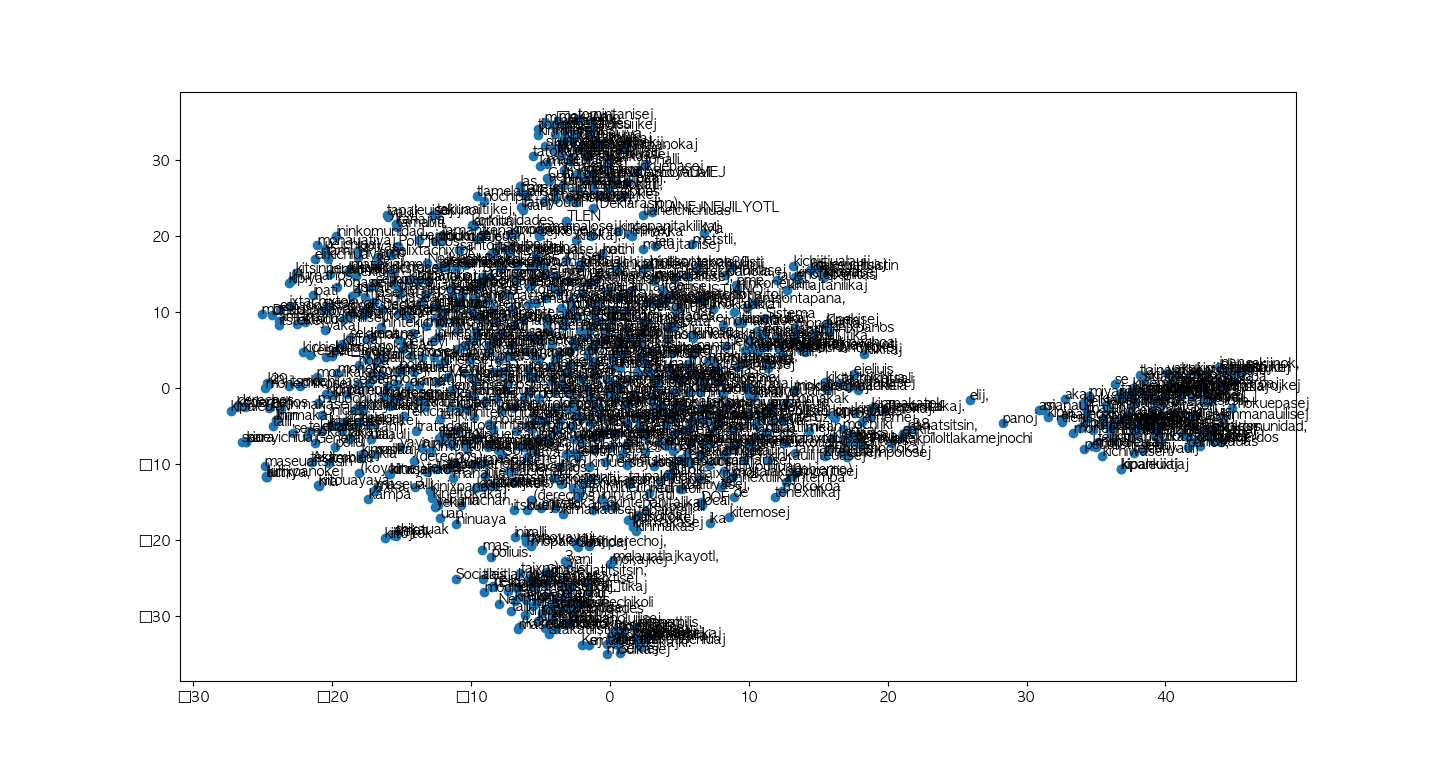
Word embedding model (Nahuatl)
-
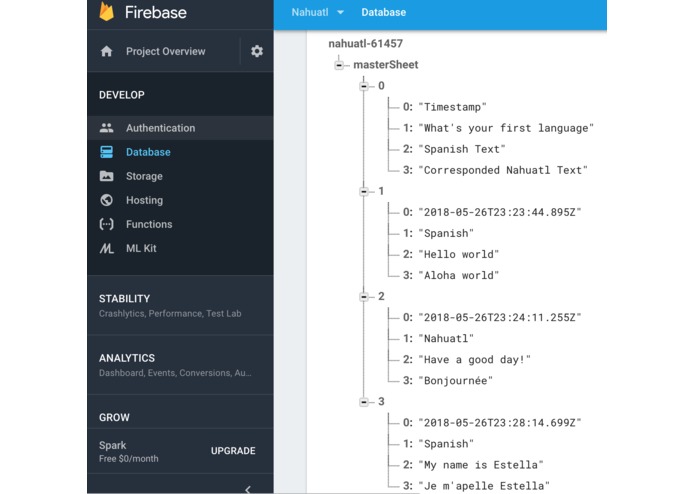
Firebase real-time database
-
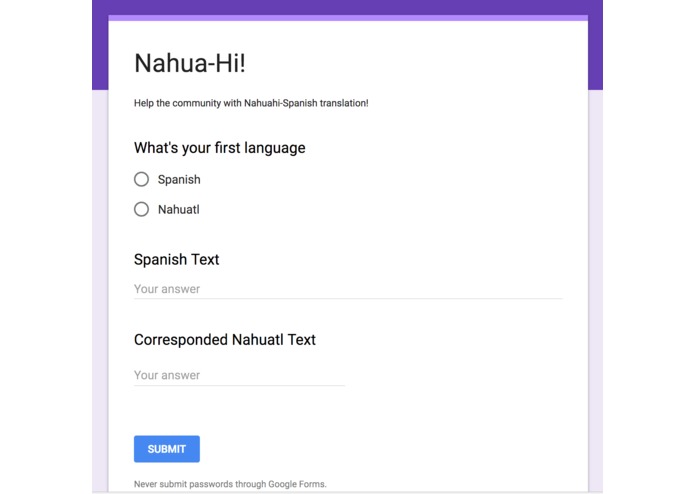
Pair-data Collecting Forms


Inspiration
52% decline in the number of people who have an indigenous language as their mother tongue since 1996. We would like to break the language barrier, so that native indigenous communities aren’t left behind and become a part of the mainstream society. We decided to tackle one layer of the language translation process, and that is data collection.
What it does
Bottom-up creative methods of collecting indigenous languages' data including chatbot and forms. Through firebase real-time database, the data could be linked to the word embedding model and help train the computer to learn the language.
How we built it
First, we build a chatbot via IBM Watson Assistant and a google form linked to firebase. A word embedding model is then built to the database of indigenous words.Word embedding is the collective name for a set of language modeling and feature learning techniques in natural language processing (NLP) where words or phrases from the vocabulary are mapped to vectors of real numbers. We used Word2Vec. Word2vec takes as its input a large corpus of text and produces a vector space, typically of several hundred dimensions, with each unique word in the corpus being assigned a corresponding vector in the space. Word vectors are positioned in the vector space such that words that share common contexts in the corpus are located in close proximity to one another in the space
Challenges we ran into
Because neural machine translation requires clean paired data which would be unlikely to gather due to the remote locations and rare usage of foreign languages, word embedding is the next step to achieve language translation for these native languages, since it only requires data from one language. Due to that constraint, the paired data that we had initially was not clean enough to work with neural machines, thus, making us rethink the way of having to collect as much data to implement the word embedding approach.
Accomplishments that we're proud of
We successfully build a word embedding model with existed documents. A chatbot is built and the data can be collected via the firebase and be used to improve our embedding model.
What we learned
In this Hackathon, we validated that the main problem for translating indigenous languages is the data collection process. We learned that there are creative ways to do data collection processes that can solve other problems while collecting the data. We proposed some ideas of our own to do this including chatbots that could deal with mental health issues.
What's next for NahuaHi
We showed creative and innovative ways to collect data as seamlessly as possible. We presented how that data would be used briefly to give the data collection a purpose. The next steps are to train the model with more data as our data collection platform is being deployed and used by more and more people. Once clear translations can be achieved, native communities can embody the roles of the mainstream society. On the application side, NahuaHi could potently serve other purposes through the chatbot and form interfaces such as creating a mental health checkup bot and as for the forms, they can be used to gather research data for survey like research.
Log in or sign up for Devpost to join the conversation.